



前言: 这篇文章旨在帮助新手使用 Llama-Factory 进行模型微调。我们默认读者的本地或云端环境已按官方指引配置完成,可直接开始实践。
首先在官网把项目克隆下来(这里我使用的是目前最新版本0.9.4)
git clone https://github.com/hiyouga/LlamaFactory.git接下来我们按照需要的依赖
cd LLaMA-Factory-0.94 // 进入项目的根目录
pip install -e ".[torch,metrics]" --no-build-isolation -i https://pypi.tuna.tsinghua.edu.cn/simple // 安装依赖, 这里使用了清华源依赖安装完成后, 我们在命令行就可以使用 llamafactory-cli 脚手架命令了
现在可以去Hugging Face 或者是魔塔社区, 去下载微调的模型 , 这里我微调的模型是Linshu-7B , 同时也可以在社区下载微调的数据集, 我下载的是多轮对话的数据集(以下是我数据集的示例)
[
{
"conversations": [
{
"from": "human",
"value": "脑垂体微腺瘤,泌乳素高。高泌乳素,后来做磁共振考虑脑垂体微腺瘤,吃溴隐停控制"
},
{
"from": "gpt",
"value": "您好,根据您的描述,您被诊断为脑垂体微腺瘤并伴有高泌乳素水平。溴隐停是一种常用的药物,可以有效控制泌乳素的分泌。关于您的问题,我可以告诉您,脑垂体微腺瘤一般不会对母乳喂养产生影响,您可以继续母乳喂养。不过,为了确保治疗效果和您的健康,建议您定期复查泌乳素水平,以便及时调整治疗方案。如果您还有其他疑问,请随时告诉我。"
}
]
},
]
// 注意点:
1.多轮对话的的结束一定是gpt, 不然训练过程训练数据被视为无效, 会被丢弃, 公开的数据集也不能百分百可用, 所以必要的时候可以review 一下, 或者写一个脚本去统一处理
2. 好的数据会微调出好的模型, 数据不在于数量, 而是在于质量, 微调只要记住的一句话, 垃圾进, 垃圾出, 数据集的质量和微调的效果成正相关
关于如何根据自己的机器去选择适合我模型, 下面有一个参考:

小的模型就不建议4-bit 微调, 因为效果很差, 建议先将模型完整的微调后, 再进行量化, 这样是最好的
现在开始使用命令进行微调:
llamafactory-cli train \
--stage sft \ # [选项: pt(预训练), sft(指令微调), rm(奖励模型), ppo/dpo(强化学习)]
--do_train True \ # [选项: True, False] 是否启动训练
--model_name_or_path /path/to/model \ # 基座模型本地路径或 HuggingFace ID
--preprocessing_num_workers 8 \ # [建议: 4-16] 预处理数据的 CPU 进程数。你的 6 核 CPU 建议设为 4
--finetuning_type lora \ # [选项: lora, freeze(冻结层), full(全量微调)] LoRA 最省显存
--template qwen2_vl \ # [常用: default, alpaca, qwen, vicuna, llama3] 必须与模型架构严格对应
--max_samples 2200 \ # [数值] 每个数据集加载的最大样本量,用于快速测试或平衡多数据集
--flash_attn auto \ # [选项: auto, disabled, sdpa, fa2] fa2 最省显存且最快,需显卡硬件支持
--dataset_dir data \ # 数据集定义文件 (dataset_info.json) 所在的文件夹路径
--dataset test_dataset \ # 数据集名称,支持多个数据集用逗号隔开,如: ds1,ds2
--cutoff_len 1024 \ # [数值] 最大序列长度。显存占用随此值的增加呈平方级上升
--learning_rate 5e-5 \ # [建议: 1e-6 到 5e-4] 学习率。全量微调通常设小一点(1e-5),LoRA 设大一点
--num_train_epochs 3.0 \ # [数值] 总训练轮数。医疗问诊等专业领域通常建议 3-5 轮
--per_device_train_batch_size 2 \ # [建议: 1-8] 每张卡的批处理大小。显存溢出(OOM)时首选调低此值
--gradient_accumulation_steps 4 \ # [数值] 梯度累积。最终 BatchSize = 单卡BS * 累积步数 * 显卡数
--lr_scheduler_type cosine \ # [选项: linear, cosine, constant, polynomial] 常用 cosine 帮助模型平滑收敛
--max_grad_norm 1.0 \ # [数值] 梯度裁剪阈值。防止梯度爆炸,1.0 是通用稳健值
--logging_steps 5 \ # [数值] 控制台打印 Loss 的频率。设太小会略微影响训练速度
--save_steps 100 \ # [数值] 保存 Checkpoint 的频率。建议设大一点,节省磁盘空间
--warmup_steps 50 \ # [数值] 预热步数。在训练初期线性增加学习率,防止剧烈震荡
--packing False \ # [选项: True, False] 将多条短样本打包成一条长样本提高训练效率
--report_to none \ # [选项: none, wandb, tensorboard, ml flow] 推荐用 tensorboard 可视化
--output_dir saves/Lingshu_v1_3\ # 训练结果、模型权重、日志的保存根目录
--bf16 True \ # [选项: True, False] 需 Ampere 架构(30/40系)支持,比 fp16 更精准
--plot_loss True \ # [选项: True, False] 训练完后在 output_dir 自动生成 loss_curve.png
--trust_remote_code True \ # [选项: True, False] 是否信任并执行模型文件夹内的自定义 python 代码
--include_num_input_tokens_seen True \ # [选项: True, False] 在日志中实时显示模型已“阅读”过的 token 总数
--dataloader_pin_memory False \ # [选项: True, False] 锁页内存可加速数据传输,但你的 16G 内存较紧,建议 False
--lora_rank 32 \ # [建议: 8, 16, 32, 64, 128] 秩。越高模型拟合能力越强,但显存占用略增
--lora_alpha 64 \ # [建议: 通常为 rank 的 1.5-2 倍] 缩放系数,影响 LoRA 权重的步进幅度
--lora_dropout 0.1 \ # [建议: 0.05 - 0.1] 丢弃率。用于防止微调时产生严重的过拟合
--lora_target all \ # [常用: all, q_proj,v_proj] all 代表微调所有线性层,效果最好
--weight_decay 0.01 \ # [数值] 权重衰减。正则化手段,防止模型参数数值过大导致过拟合
--val_size 0.1 \ # [建议: 0.01 - 0.1] 从数据中切出多少比例作为不参与训练的验证集
--eval_strategy steps \ # [选项: steps, epoch, no] 什么时候进行验证集评估性能
--eval_steps 16 \ # [数值] 每隔多少步计算一次验证集 Loss 和准确率
--per_device_eval_batch_size 4 \ # [数值] 评估时的 BatchSize。可以设比训练时大,因为不计算梯度
--quantization_bit 8 \ # [选项: 4, 8, none] 4-bit 最省显存,8-bit 精度较高,none 为不量化
--quantization_method bnb \ # [选项: bnb, hqq, eetq] bitsandbytes (bnb) 是目前兼容性最稳的选择
--double_quantization True \ # [选项: True, False] 对量化后的权重再次量化,能再省一点点显存
--optim adamw_torch # [选项: adamw_torch, adamw_bnb_8bit, sgd] 显存极度紧缺可用 8bit 优化器
训练完成后我们可以使用模型进行对话(这里我选择第350个检查点的模型进行对话)
llamafactory-cli chat \
--model_name_or_path /.../Lingshu-7B \ # 基座模型路径:必须与微调时使用的基座模型完全一致
--adapter_name_or_path /.../checkpoint-350 \ # 适配器路径:微调产生的 LoRA 权重文件夹(含 adapter_config.json)
--template qwen2_vl \ # 提示词模板:必须与训练时一致,否则模型会胡言乱语
--finetuning_type lora \ # 微调类型:[lora, freeze, full]。此处需指明以加载 adapter
--quantization_bit 8 \ # [选项: 4, 8, none] 推理量化位数。8-bit 可在几乎不损失精度下节省显存
--quantization_method bnb \ # [选项: bnb, hqq, eetq] 量化方法。需与训练时的环境兼容
--temperature 0.7 \ # [范围: 0.0-1.5] 温度值。越高越随机(有创意),越低越严谨。建议 0.1-0.4
--top_p 0.9 \ # [范围: 0.0-1.0] 核采样。仅从累计概率前 90% 的词中筛选,过滤低概率废话
--top_k 50 \ # [数值] 采样筛选前 K 个最可能的词。通常与 top_p 配合使用
--num_beams 1 \ # [数值] 束搜索。>1 会尝试多条路径取最优,虽能提升逻辑性但极慢且耗显存
--max_new_tokens 512 \ # [数值] 单次回答的最大 Token 长度。不包括输入的提示词长度
--repetition_penalty 1.1 \ # [建议: 1.0-1.2] 重复惩罚。防止模型复读机一样循环说话
--do_sample True \ # [选项: True, False] 是否开启采样。设为 False 则固定输出最可能的词
--infer_backend huggingface \ # [选项: huggingface, vllm] 推理后端。vLLM 速度极快但对显存管理较刚性
--flash_attn auto \ # [选项: auto, disabled, fa2] 开启后可显著降低长对话时的显存压力
--visual_inputs False \ # [选项: True, False] 如果是 VL (多模态) 模型且要传图片,需设为 True
--device_map auto \ # [选项: auto, cpu, cuda:0] 设备分配策略。auto 会自动识别你的显卡
--trust_remote_code True # 允许执行模型文件夹中的自定义推理逻辑代码
// 以下是模型训练的损失和评估的损失, 可以看到在300到350步左右已经是达到了不错的效果, 一般来说, 评估的损失和训练的损失的差值不要超过0.3这个范围, 且一个重要的前提是 训练的损失和评估的损失均在下降, 如果看到评估损失不降反升, 这个时候就要停止训练了, 模型已经过拟合了, 可以选择合适的检查点(过拟合之前的点) 来进行对话, 试下效果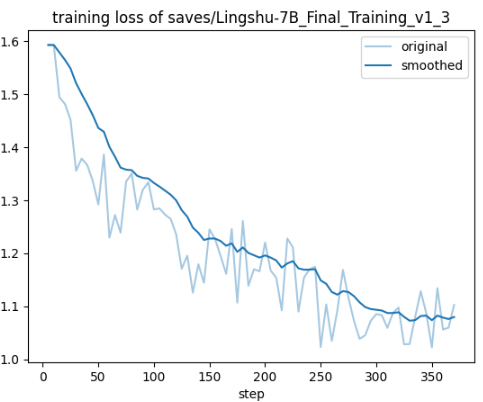
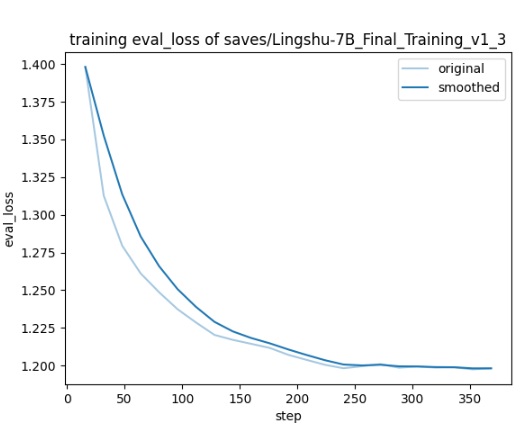
这里需要对话的原因是什么呢, 可以判断模型是否达到了你的要求, 比如我们传统没有经过微调的模型, 回答都是非常笼统, 且它的回答直接给你冷场, 没有任何的引导性的对话
未完待续..............
原创
Llama-Factory 模型微调 + Llama.cpp 模型量化
本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
评论交流
欢迎留下你的想法