



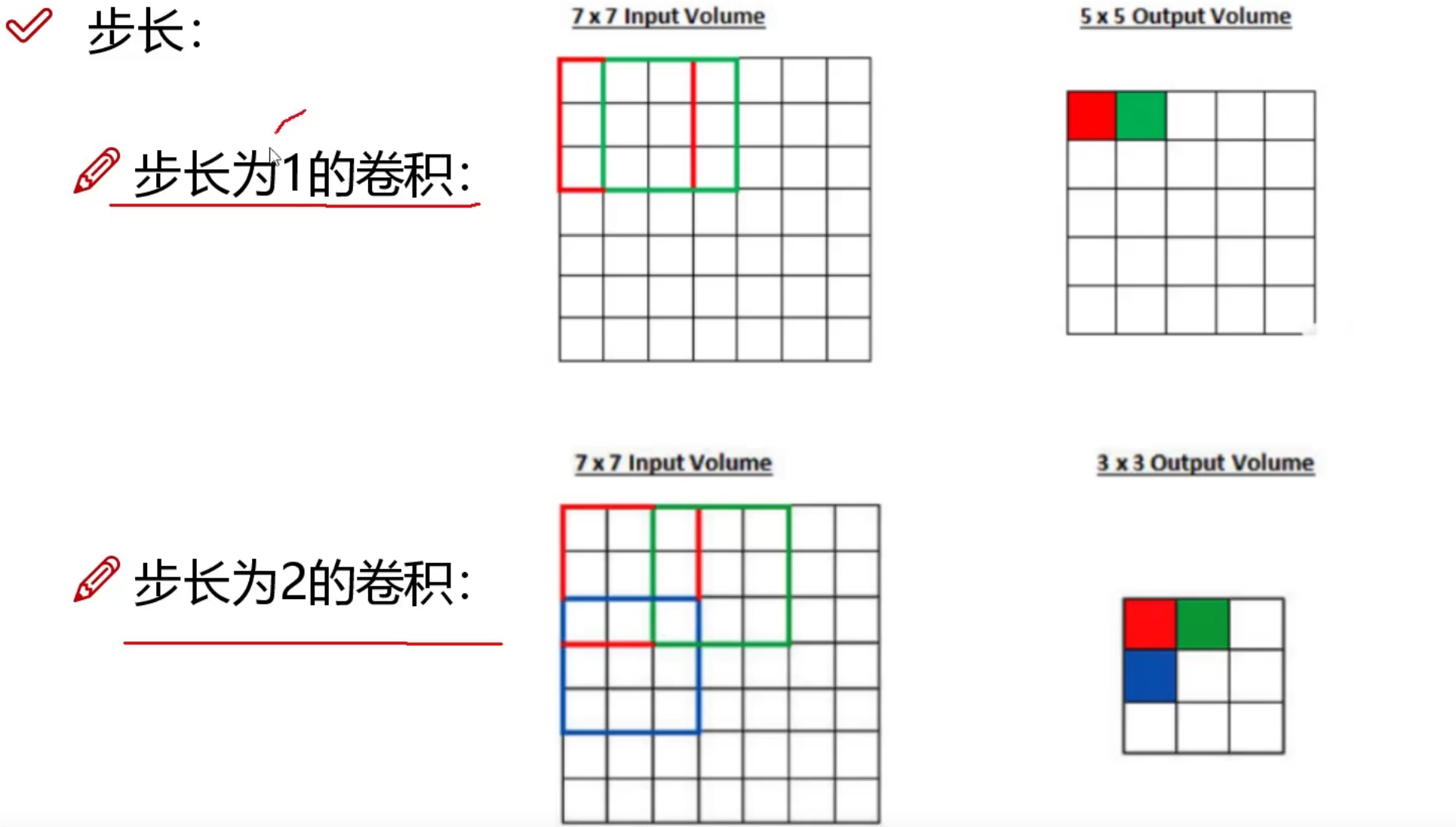
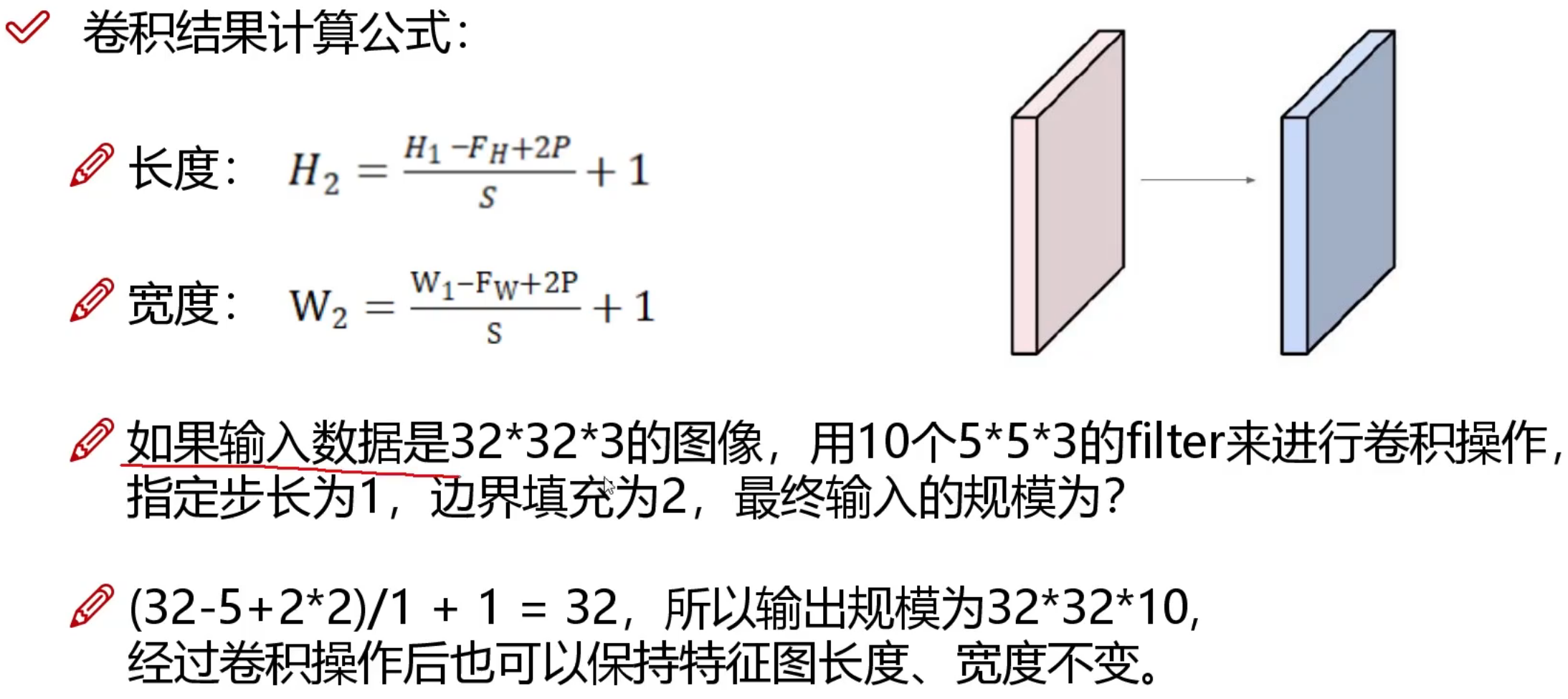
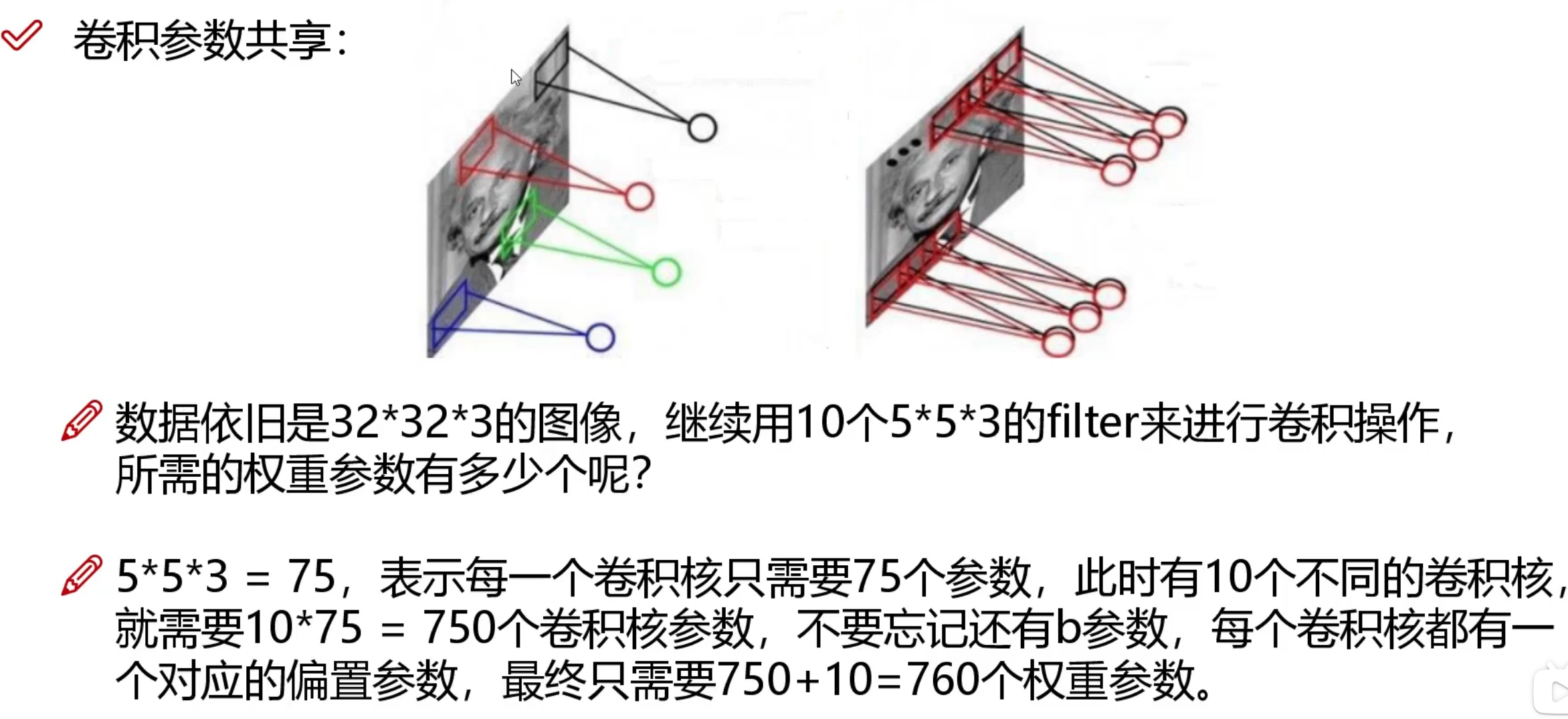
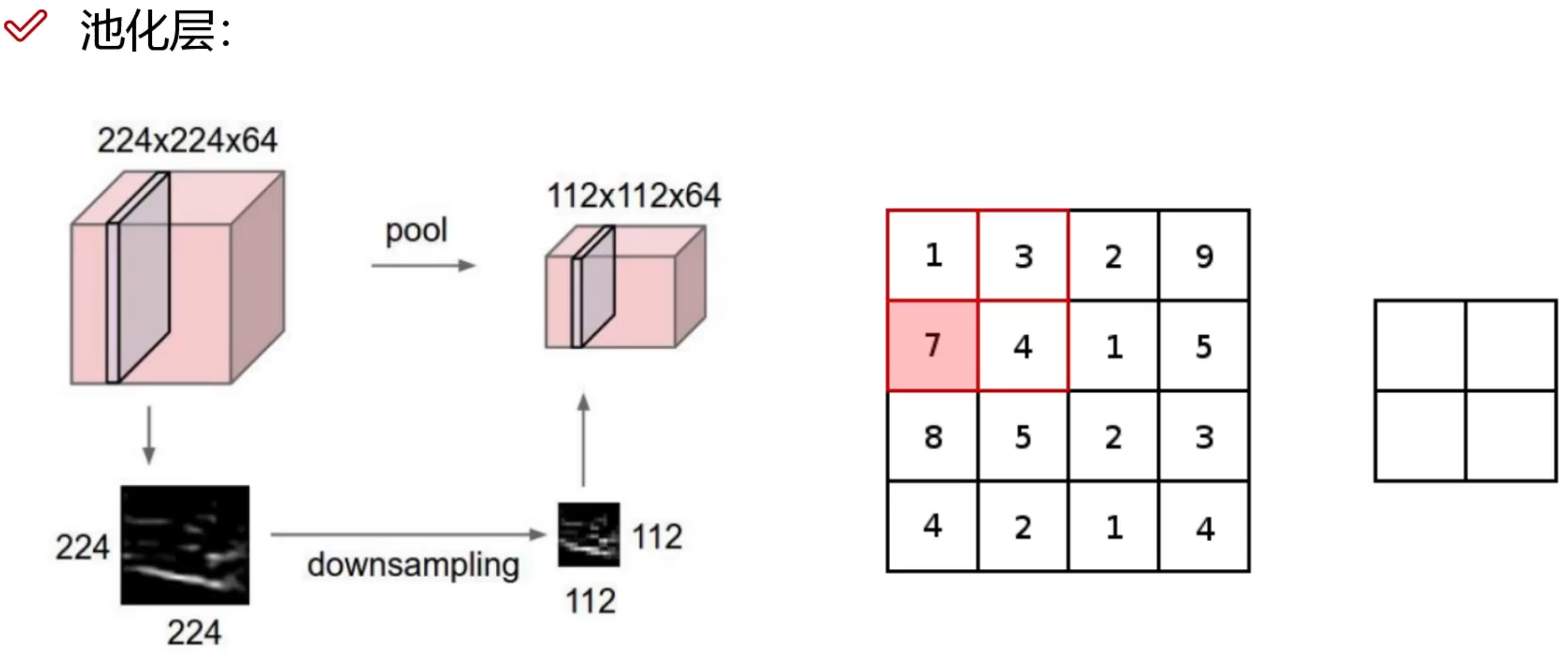
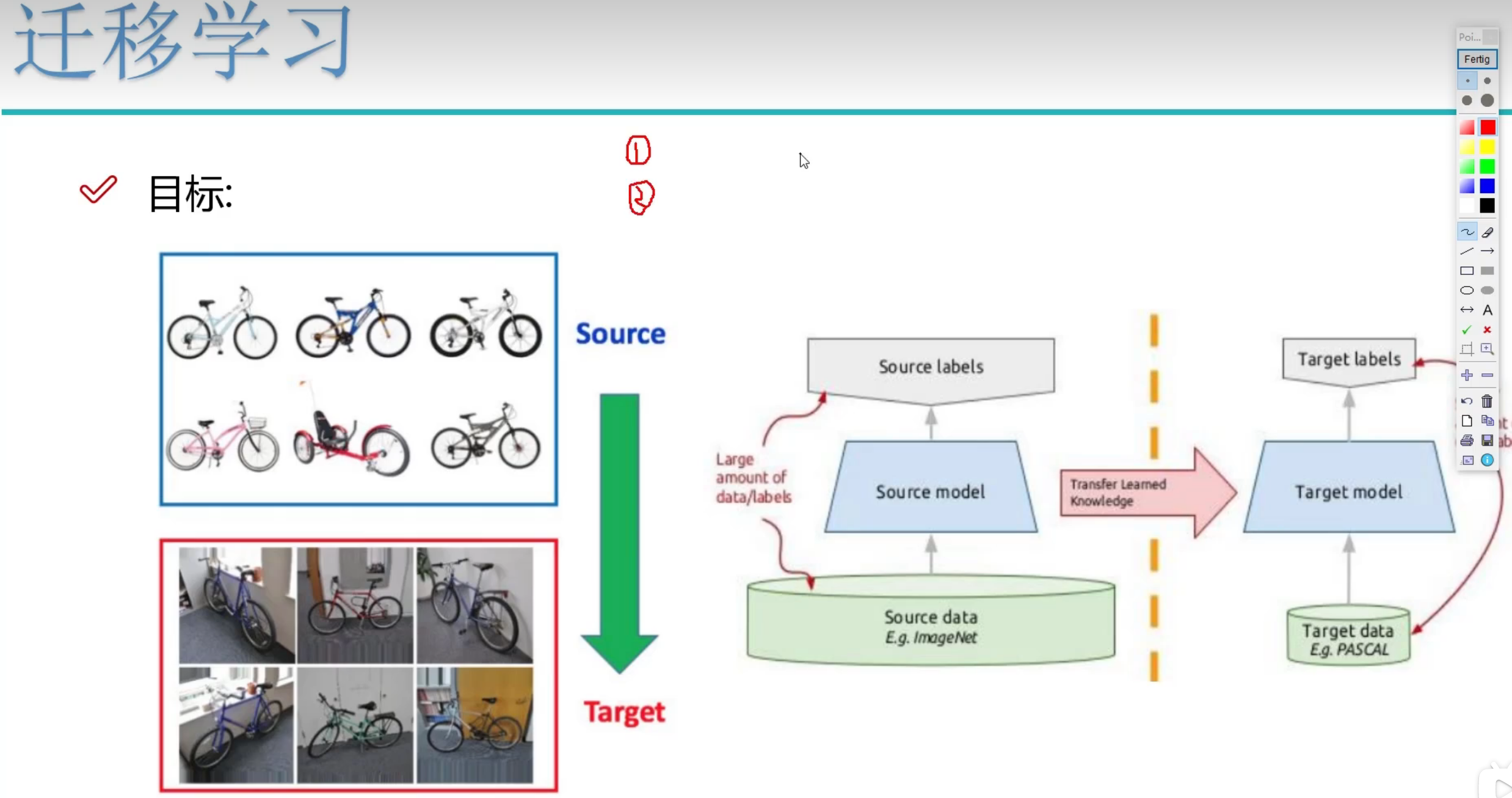
计算机眼中的图像
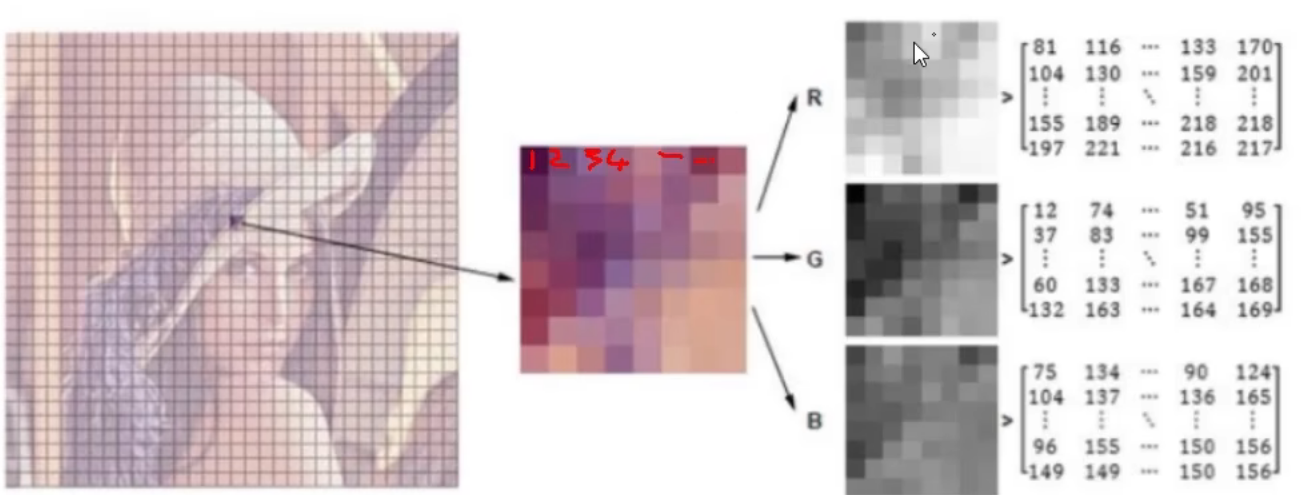
彩色图像 cv2.IMREAD_COLOR
灰度图像 cv2.IMREAD_GRAYSCALE
保存图像 cv2.imwrite()
cv2.VideoCapture(" 视频路径") 可以捕获摄像头
cv2.cvtColor( )进行色彩空间的转换
 截取图像 第一个参数是 高度H 第二个参数是 宽度 W
截取图像 第一个参数是 高度H 第二个参数是 宽度 W
颜色通道获取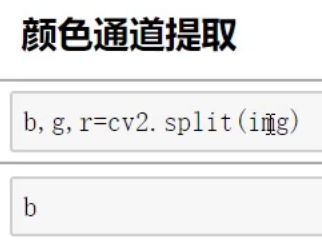
仅保留 不同的颜色通 [ :, :, 0] 表示 取0维的所有X值和Y值
对于X[:,0];
是取二维数组中第一维的所有数据
对于X[:,1]
是取二维数组中第二维的所有数据
对于X[:,m:n]
是取二维数组中第m维到第n-1维的所有数据
对于X[:,:,0]
是取三维矩阵中第一维的所有数据
对于X[:,:,1]
是取三维矩阵中第二维的所有数据
对于X[:,:,m:n]
是取三维矩阵中第m维到第n-1维的所有数据 这样的讲解可能还是有点抽象,下面我们用具体的实例来讲解,相信会更加容易理解,具体如下:
from __future__ import division
'''
__Author__:沂水寒城
学习Python中的X[:,0]、X[:,1]、X[:,:,0]、X[:,:,1]、X[:,m:n]和X[:,:,m:n]
'''
import numpy as np
def simple_test():
'''
简单的小实验
'''
data_list=[[1,2,3],[1,2,1],[3,4,5],[4,5,6],[5,6,7],[6,7,8],[6,7,9],[0,4,7],[4,6,0],[2,9,1],[5,8,7],[9,7,8],[3,7,9]]
# data_list.toarray()
data_list=np.array(data_list)
print 'X[:,0]结果输出为:'
print data_list[:,0]
print 'X[:,1]结果输出为:'
print data_list[:,1]
print 'X[:,m:n]结果输出为:'
print data_list[:,0:1]
data_list=[[[1,2],[1,0],[3,4],[7,9],[4,0]],[[1,4],[1,5],[3,6],[8,9],[5,0]],[[8,2],[1,8],[3,5],[7,3],[4,6]],
[[1,1],[1,2],[3,5],[7,6],[7,8]],[[9,2],[1,3],[3,5],[7,67],[4,4]],[[8,2],[1,9],[3,43],[7,3],[43,0]],
[[1,22],[1,2],[3,42],[7,29],[4,20]],[[1,5],[1,20],[3,24],[17,9],[4,10]],[[11,2],[1,110],[3,14],[7,4],[4,2]]]
data_list=np.array(data_list)
print 'X[:,:,0]结果输出为:'
print data_list[:,:,0]
print 'X[:,:,1]结果输出为:'
print data_list[:,:,1]
print 'X[:,:,m:n]结果输出为:'
print data_list[:,:,0:1]
if __name__ == '__main__':
simple_test()
==========================结果=============================
X[:,0]结果输出为:
[1 1 3 4 5 6 6 0 4 2 5 9 3]
X[:,1]结果输出为:
[2 2 4 5 6 7 7 4 6 9 8 7 7]
X[:,m:n]结果输出为:
[[1]
[1]
[3]
[4]
[5]
[6]
[6]
[0]
[4]
[2]
[5]
[9]
[3]]
X[:,:,0]结果输出为:
[[ 1 1 3 7 4]
[ 1 1 3 8 5]
[ 8 1 3 7 4]
[ 1 1 3 7 7]
[ 9 1 3 7 4]
[ 8 1 3 7 43]
[ 1 1 3 7 4]
[ 1 1 3 17 4]
[11 1 3 7 4]]
X[:,:,1]结果输出为:
[[ 2 0 4 9 0]
[ 4 5 6 9 0]
[ 2 8 5 3 6]
[ 1 2 5 6 8]
[ 2 3 5 67 4]
[ 2 9 43 3 0]
[ 22 2 42 29 20]
[ 5 20 24 9 10]
[ 2 110 14 4 2]]
X[:,:,m:n]结果输出为:
[[[ 1]
[ 1]
[ 3]
[ 7]
[ 4]]
[[ 1]
[ 1]
[ 3]
[ 8]
[ 5]]
[[ 8]
[ 1]
[ 3]
[ 7]
[ 4]]
[[ 1]
[ 1]
[ 3]
[ 7]
[ 7]]
[[ 9]
[ 1]
[ 3]
[ 7]
[ 4]]
[[ 8]
[ 1]
[ 3]
[ 7]
[43]]
[[ 1]
[ 1]
[ 3]
[ 7]
[ 4]]
[[ 1]
[ 1]
[ 3]
[17]
[ 4]]
[[11]
[ 1]
[ 3]
[ 7]
[ 4]]]
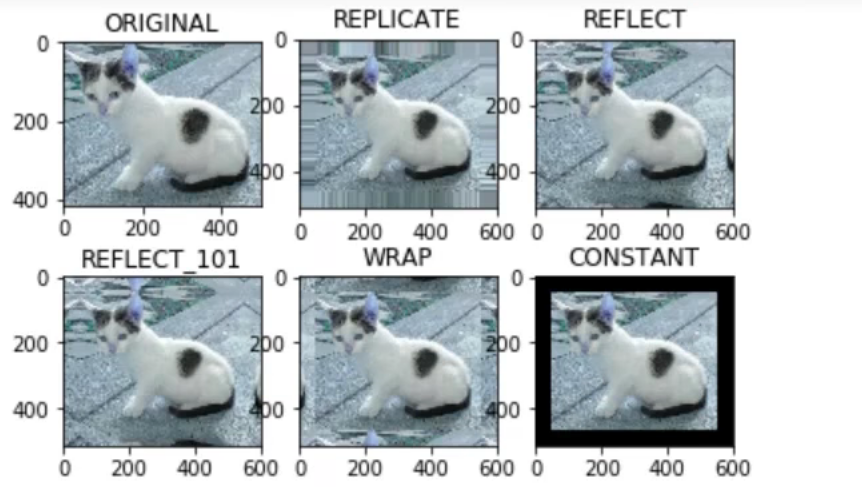
[Finished in 0.6s]10.边界填充


腐蚀操作
 itterrtions 迭代的次数
itterrtions 迭代的次数
ones(x, y) 表示腐蚀的卷积和大小
膨胀操作
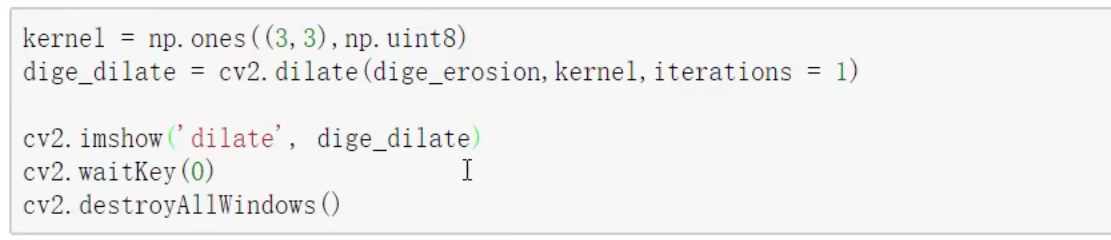
开运算. 闭运算

梯度运算


可以把边界的信息提取出来
梯度运算补充
一:什么是梯度?
在高等数学中我们了解到梯度不是一个实数,他是一个向量,是有方向有大小的。现在以一个二元函数来举例,假设一二元函数f(x,y),在某点的梯度有:
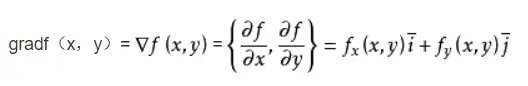
整理后得到:
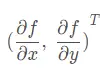
其实也就是他的方向导数。梯度的方向是函数变化最快的方向,沿着梯度的方向容易找到最大值。
二:图像梯度
在一幅模糊图像中的物体的轮廓不明显,轮廓边缘灰度变化不强烈,从而导致层次感不强,而在清晰图片中的物体轮廓边缘灰度变化明显,层次感强。那么这种灰度变化明显不明显怎么去定义呢?
可以使用导数(梯度),衡量图像灰度的变化率,因为图像就是函数。正因如此,我们引入的图像梯度可以把图像看成二维离散函数,图像梯度其实就是这个二维离散函数的求导。
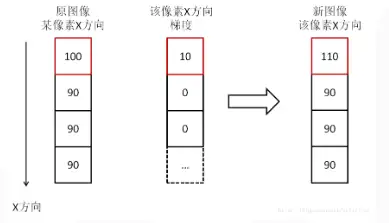
在上边这幅图中可以看出,如果一副图像的相邻灰度值有变化,那么梯度就存在,如果图像相邻的像素没有变化,那么梯度就是0,把梯度值和相应的像素相加,那么灰度值没有变化的,像素就没有变化,灰度值变了,像素值也就变了。我们看到,相加后的新图像,原图像像素点100与90亮度只相差10,现在是110与90,亮度相差20了,对比度显然增强了,尤其是图像中物体的轮廓和边缘,与背景大大加强了区别,这就是用梯度来增强图像的原理。将图像函数f(x,y)梯度表达式表示出来:
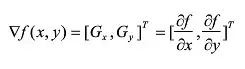
幅度
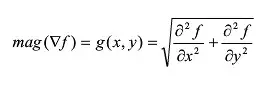
方向角:

对于数字图像来说,相当于是二维离散函数求梯度,使用差分来近似导数:
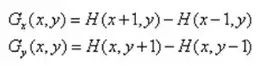
因此,像素点(x,y)处的梯度值和梯度方向分别是:
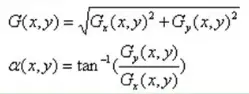
这里的平方+开方的,计算量太大,于是一般用绝对值来近似平方和平方根的操作,来降低计算量:
![]()
在上述的推论中我们得到,梯度的方向是函数变化最快的方向,所以当函数中存在边缘时,一定有较大的梯度值,相反,当图像中有比较平滑的部分时,灰度值变化较小,则相应的梯度也较小,图像处理中把梯度的模简称为梯度,由图像梯度构成的图像成为梯度图像。
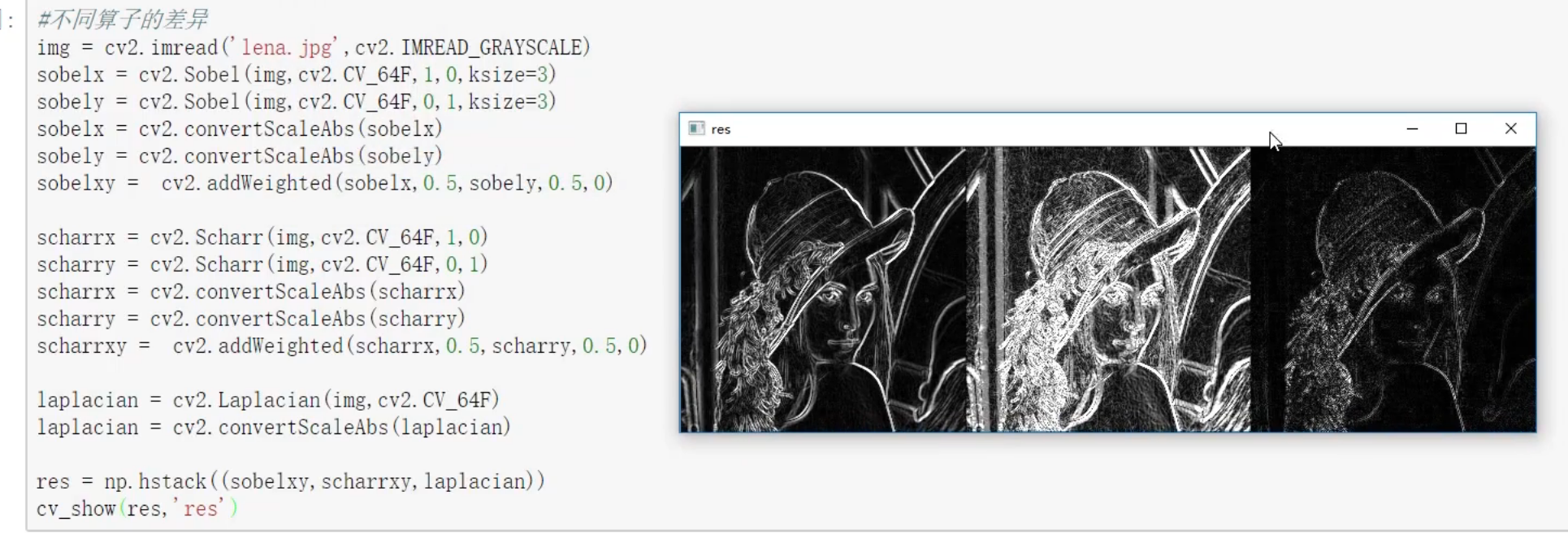
一些经典的图像梯度算法是考虑图像的每个像素的某个邻域内的灰度变化,利用边缘临近的一阶或二阶导数变化规律,对原始图像中像素某个邻域设置梯度算子,通常我们用小区域模板进行卷积来计算,有Sobel算子、Robinson算子、Laplace算子等。
礼帽和黑帽
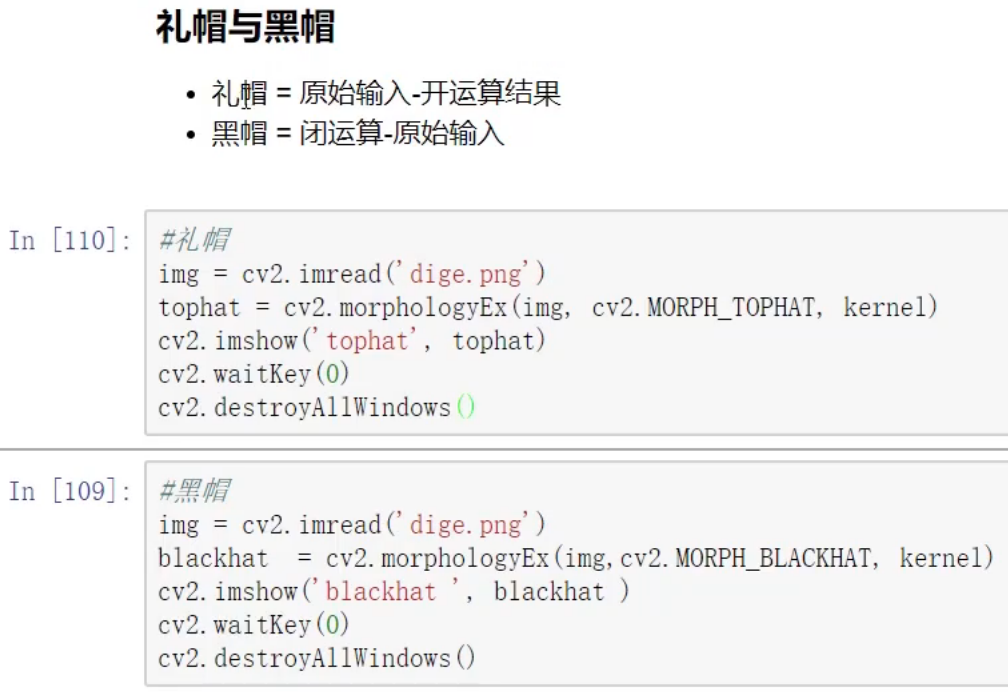
图像梯度-Sobel 算子
 ddepth 通常指定为-1 写成 cv2.CV.64F 可以保留负值
ddepth 通常指定为-1 写成 cv2.CV.64F 可以保留负值
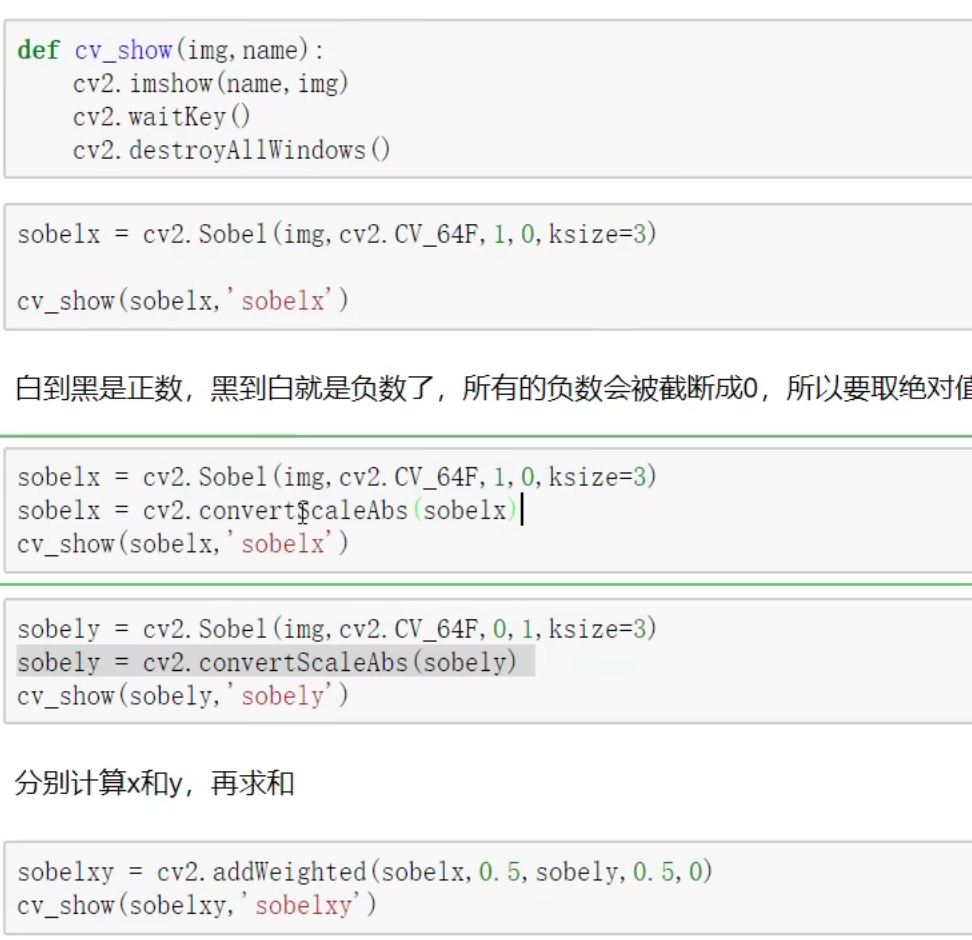 这样可以把所有的轮廓提取出来
这样可以把所有的轮廓提取出来
不同算子的差异
图像平滑处理
均值滤波
 方框滤波
方框滤波
 里面的 -1 表示自适应填充对应的值,这里的 - 1 表示与颜色通道数自适应一样
里面的 -1 表示自适应填充对应的值,这里的 - 1 表示与颜色通道数自适应一样
高斯滤波
 高斯滤波: 高斯函数赋予当前像素点周围像素点不同的权重(与距离成反比), 来对当前像素点进行滤波,而非均值滤波那样权重相同
高斯滤波: 高斯函数赋予当前像素点周围像素点不同的权重(与距离成反比), 来对当前像素点进行滤波,而非均值滤波那样权重相同
中值滤波

总结: 中值滤波的效果是最好的
图像阈值
 ret 输出阈值, dst 输出对应的方法输出的图
ret 输出阈值, dst 输出对应的方法输出的图

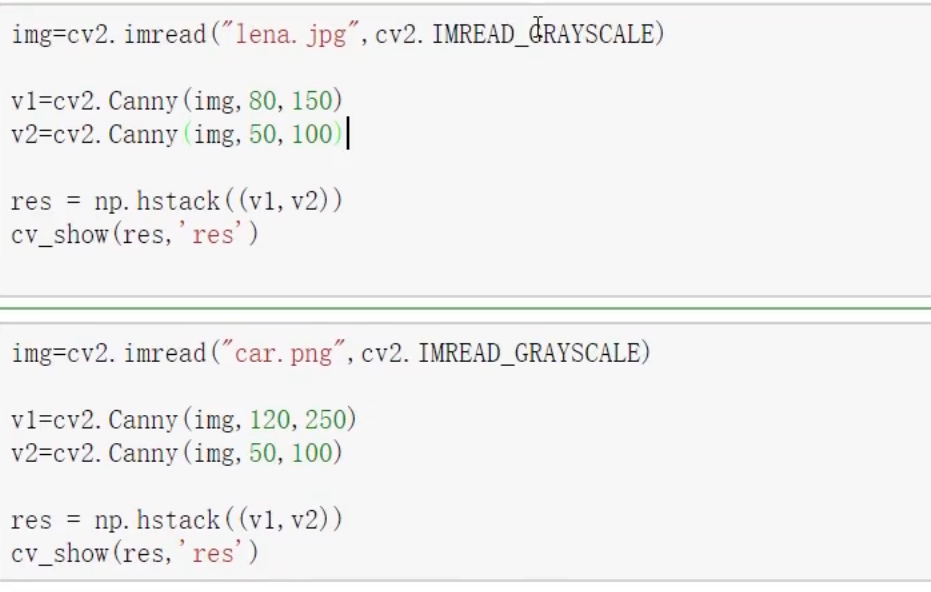
 Canny 边缘检测
Canny 边缘检测



非极大值抑制

梯度越大,表示四周颜色的差异越大
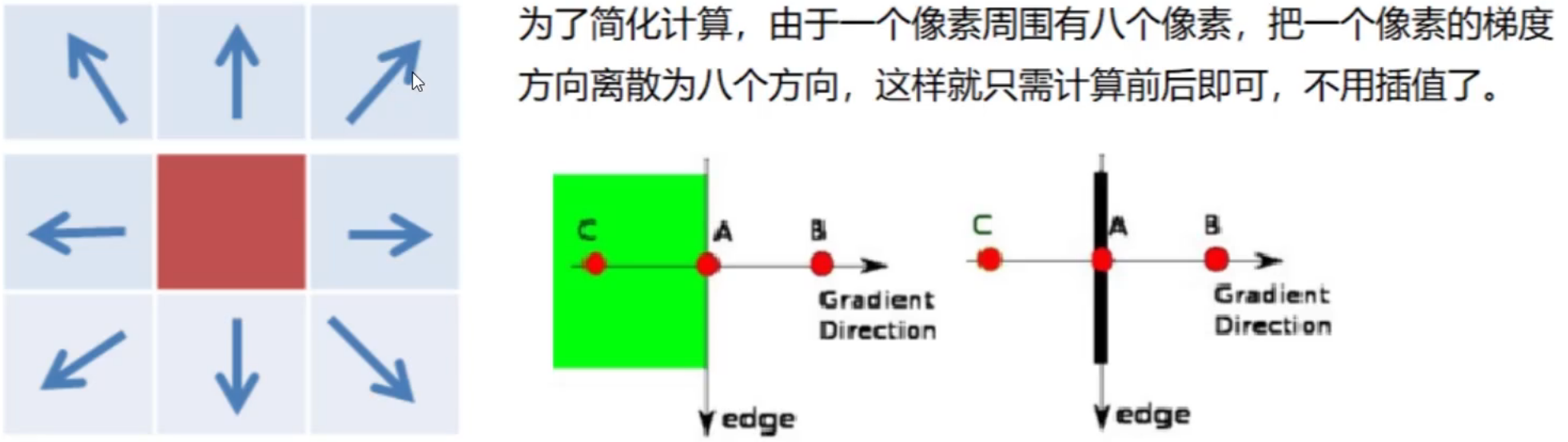
双阈值检测

代码实现
 min值不能设置太小,否则中间值可能也被纳入边界
min值不能设置太小,否则中间值可能也被纳入边界
阈值指定的适合,边缘检测越准确
图像轮廓

一般建议用最后一个
轮廓近似

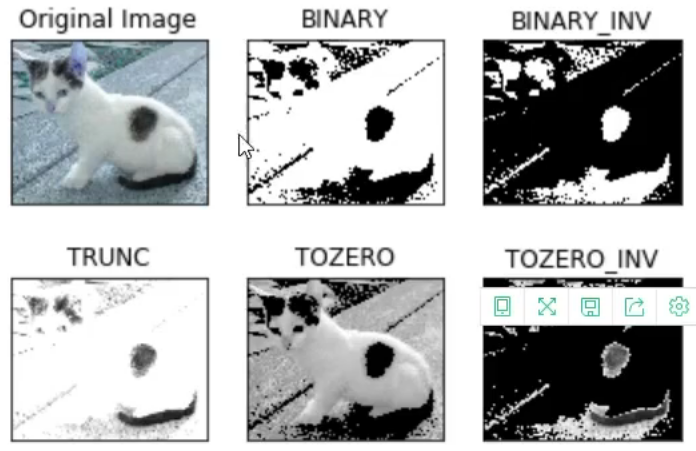
二值图像
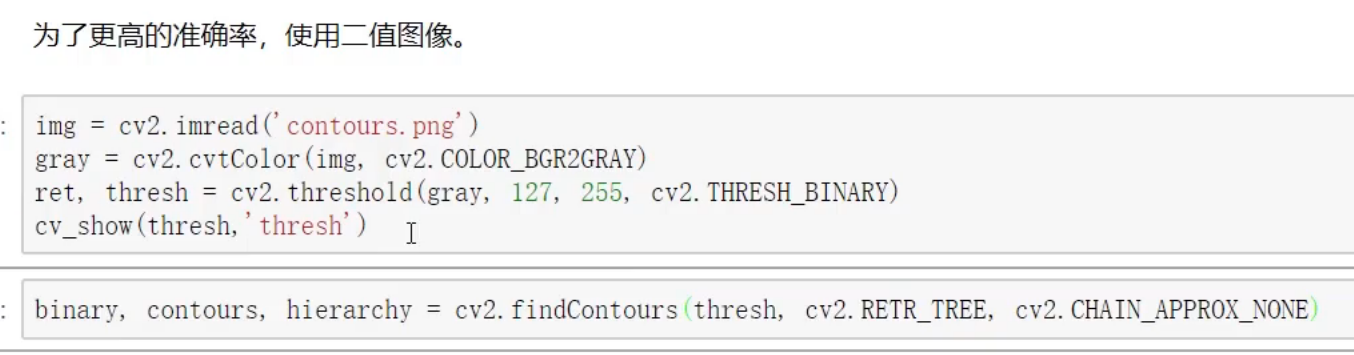 常用值为0(cv2.THRESH_BINARY)
常用值为0(cv2.THRESH_BINARY)
第四个是一个方法选择参数,常用的有:
• cv2.THRESH_BINARY(黑白二值)
• cv2.THRESH_BINARY_INV(黑白二值反转)
• cv2.THRESH_TRUNC (得到的图像为多像素值)
• cv2.THRESH_TOZERO
• cv2.THRESH_TOZERO_INV
该函数有两个返回值,retVal:得到的阈值,dst:阈值化后的图像
绘制轮廓
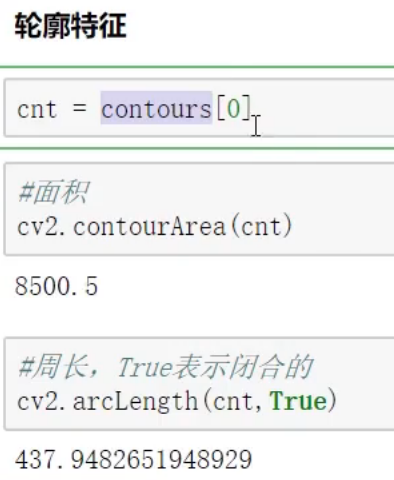
 轮廓特征
轮廓特征
 轮廓近似
轮廓近似
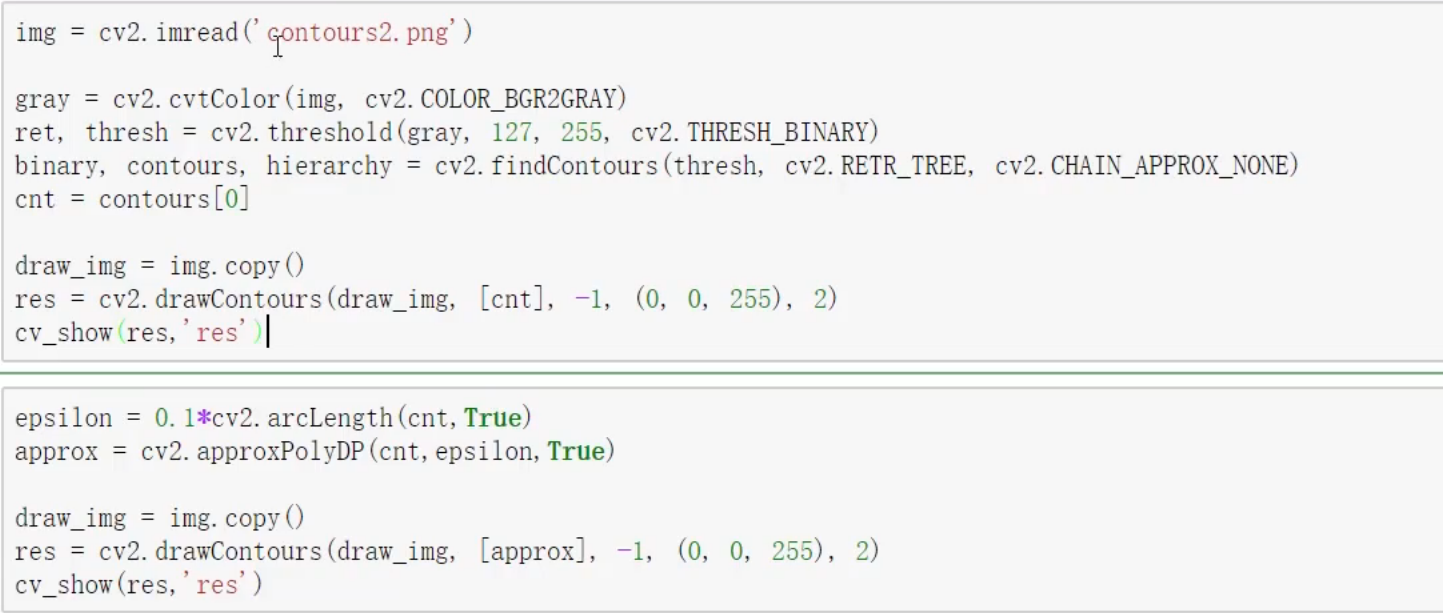 需要把 binary 删除
需要把 binary 删除
espilon 一般情况下需要用周长的百分比来 这个参数要经过调试
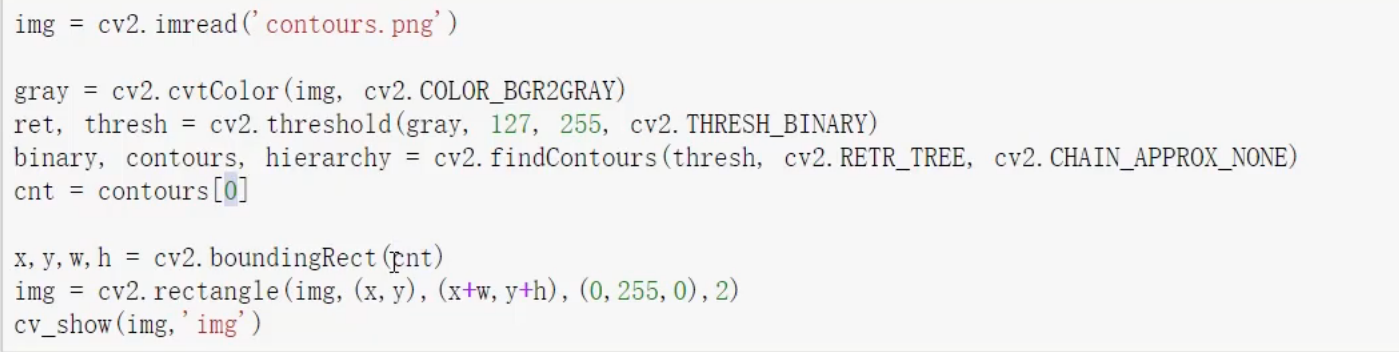
边界矩形(外接矩形 )
 模板匹配
模板匹配


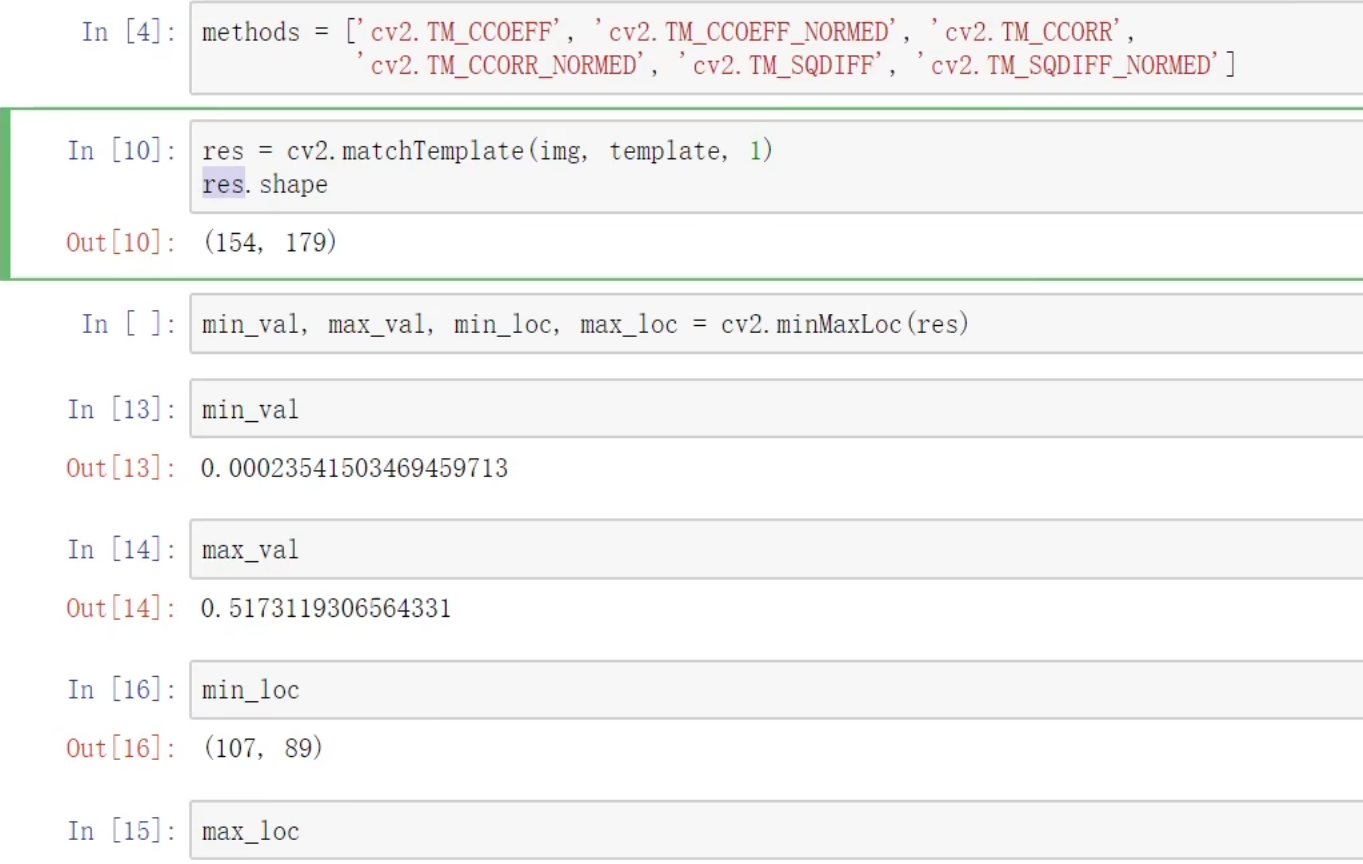
匹配多个对象
 图像金字塔
图像金字塔
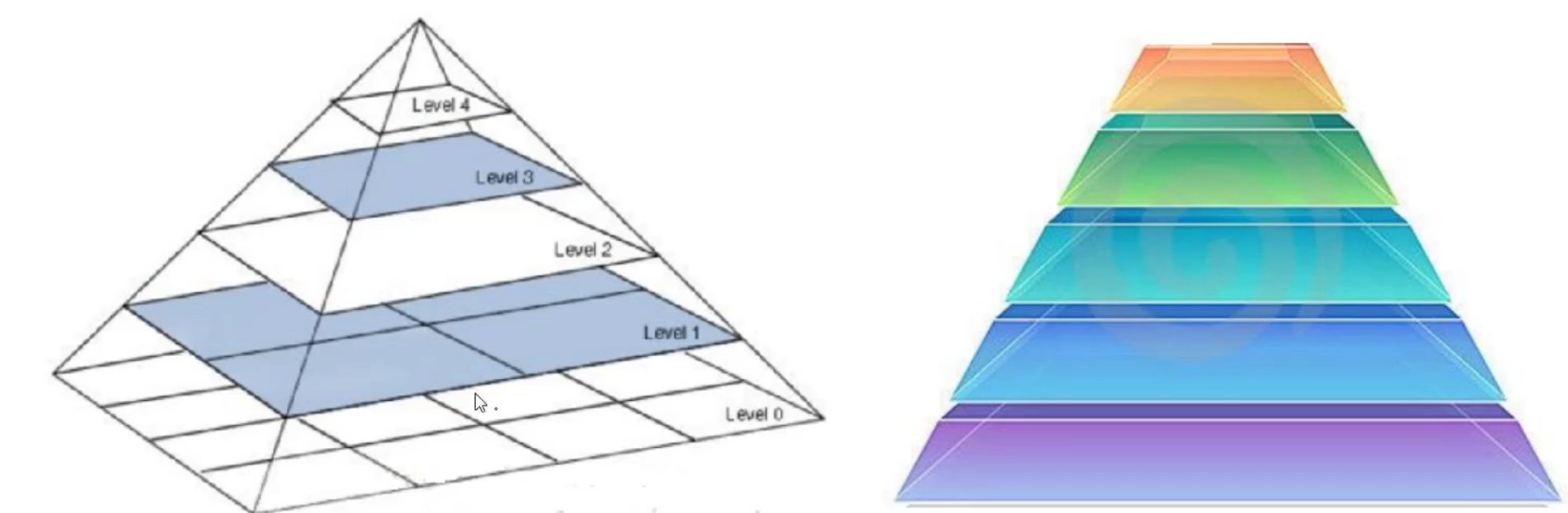


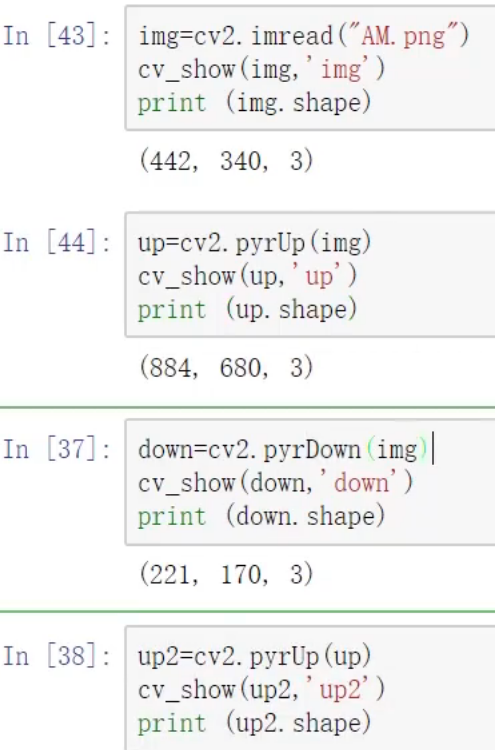
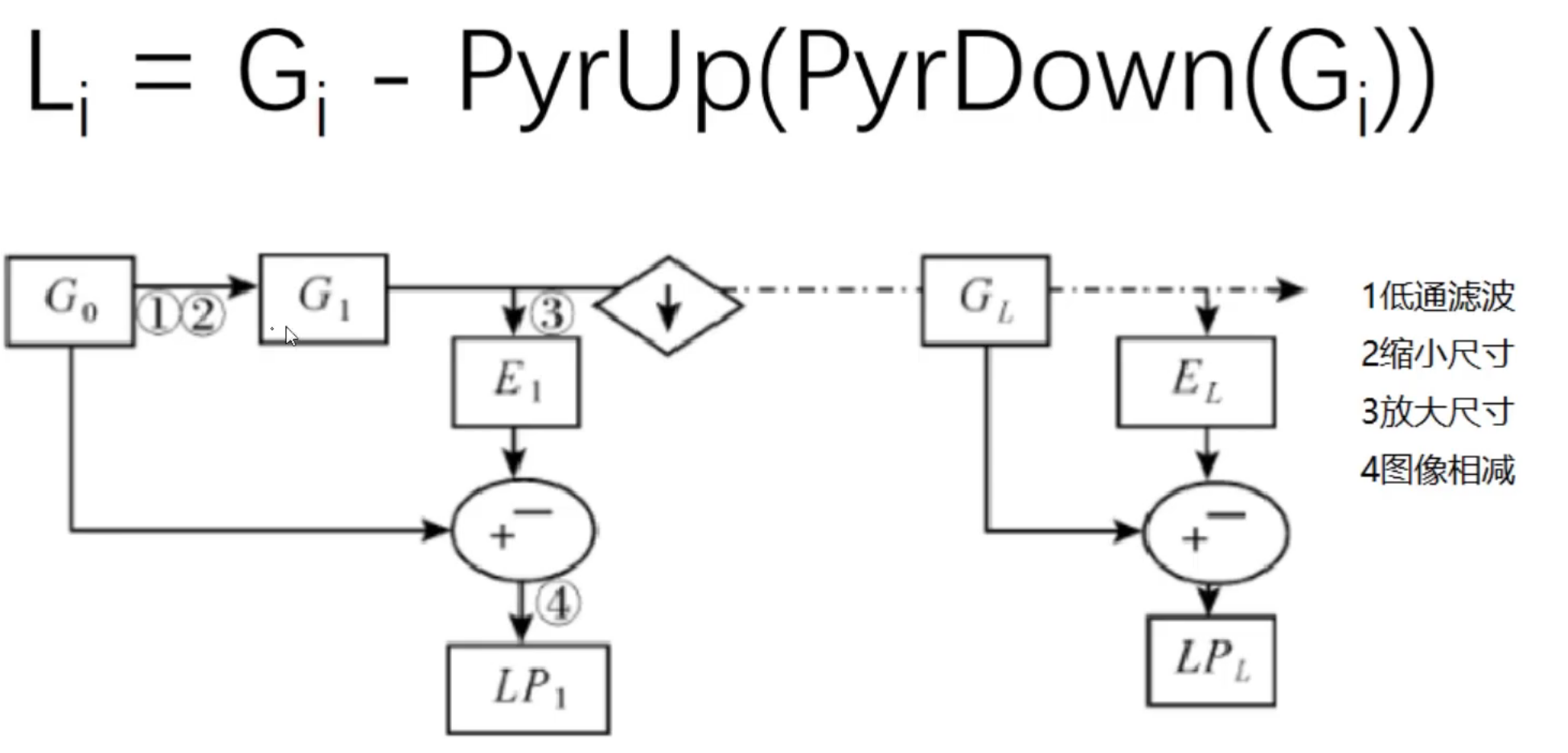
拉普拉斯金字塔
 银行卡识别
银行卡识别
import matplotlib.pyplot as plt
import numpy
import numpy as np
import argparse
import imutils
import cv2
import myutils
from imutils import contours
# 设置参数
# 设置参数
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-t", "--template", required=True,
help="path to template OCR-A image")
args = vars(ap.parse_args())
# 指定信用卡类型
FIRST_NUMBER = {
"3": "American Express",
"4": "Visa",
"5": "MaterCard",
"6": "Discover Card"
}
def cv_show(name, img):
cv2.imshow(name, img)
cv2.waitKey(1000)
cv2.destroyAllWindows()
# 获取一个模板图像
img = cv2.imread(args["template"])
cv_show('img', img)
# 灰度图
ref = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cv_show('ref', ref)
# 二值图像
ref = cv2.threshold(ref, 10, 255, cv2.THRESH_BINARY_INV)[1]
cv_show('ref', ref)
# 计算轮廓
# cv2.RETR_EXTERNAL 只检测外轮廓, cv2.CHAIN_APPROX_SIMPLE只保留终点坐标
ref, refCnts, hierarchy = cv2.findContours(ref.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(img, refCnts, -1, (0, 0, 255), 3)
cv_show('img', img)
print(refCnts)
refCnts = myutils.sort_contours(refCnts, method = "left-to-right")[0]
digits = {}
# 遍历每一个轮廓
for (i, c) in enumerate(refCnts):
(x, y, w, h) = cv2.boundingRect(c)
roi = ref[y:y + h, x:x + w]
roi = cv2.resize(roi, (57, 88))
digits[i] = roi
# 初始化卷积核
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 3))
sqKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
# 读取输入图像, 预处理
image = cv2.imread(args["image"])
cv_show('img', img)
image = myutils.resize(image, width=300)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv_show('gray', gray)
# 礼帽操作 ,突出更明亮的区域
tophat = cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, rectKernel)
cv_show('tophat', tophat)
gradX = cv2.Sobel(tophat, ddepth=cv2.CV_32F, dx=1, dy=0, ksize=-1)
gradX = np.absolute(gradX)
(minVal, maxVal) = (np.min(gradX)), np.max(gradX)
gradX = (255 * ((gradX - minVal) / (maxVal - minVal)))
gradX = gradX.astype("uint8")
print(np.array(gradX).shape)
cv_show("gradX", gradX)
# 通过闭操作(先膨胀,再腐蚀)将数字连在一起
gradX = cv2.morphologyEx(gradX, cv2.MORPH_CLOSE, rectKernel)
cv_show('gradX', gradX)
# THRESH_OTSU会自动寻找合适的阈值,适合双峰,需把阈值参数设置为0
thresh = cv2.threshold(gradX, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
cv_show('thresh', thresh)
# 再来一个闭操作
thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, sqKernel) # 再来一个闭操作
cv_show('thresh', thresh)
# 计算轮廓
ret, threshCnts, hierarchy = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = threshCnts
cur_img = image.copy()
cv2.drawContours(cur_img, cnts, -1, (0, 0, 255), 3)
cv_show('img', cur_img)
locs = []
# 遍历轮廓
for (i, c) in enumerate(cnts):
# 计算矩形
(x, y, w, h) = cv2.boundingRect(c)
ar = w / float(h)
# 选择合适的区域,根据实际任务来,这里的基本都是四个数字一组
if ar > 2.5 and ar < 4.0:
if (w > 40 and w < 55) and (h > 10 and h < 20):
# 符合的留下来
locs.append((x, y, w, h))
# 将符合的轮廓从左到右排序
locs = sorted(locs, key=lambda x: x[0])
output = []
# 遍历每一个轮廓中的数字
for (i, (gX, gY, gW, gH)) in enumerate(locs):
# initialize the list of group digits
groupOutput = []
# 根据坐标提取每一个组
group = gray[gY - 5:gY + gH + 5, gX - 5:gX + gW + 5]
cv_show('group', group)
# 预处理
group = cv2.threshold(group, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
cv_show('group', group)
# 计算每一组的轮廓
ret, digitCnts, hierarchy = cv2.findContours(group.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
digitCnts = contours.sort_contours(digitCnts,
method="left-to-right")[0]
# 计算每一组中的每一个数值
for c in digitCnts:
# 找到当前数值的轮廓,resize成合适的的大小
(x, y, w, h) = cv2.boundingRect(c)
roi = group[y:y + h, x:x + w]
roi = cv2.resize(roi, (57, 88))
cv_show('roi', roi)
# 计算匹配得分
scores = []
# 在模板中计算每一个得分
for (digit, digitROI) in digits.items():
# 模板匹配
result = cv2.matchTemplate(roi, digitROI,
cv2.TM_CCOEFF)
(_, score, _, _) = cv2.minMaxLoc(result)
scores.append(score)
# 得到最合适的数字
groupOutput.append(str(np.argmax(scores)))
# 画出来
cv2.rectangle(image, (gX - 5, gY - 5),
(gX + gW + 5, gY + gH + 5), (0, 0, 255), 1)
cv2.putText(image, "".join(groupOutput), (gX, gY - 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0, 0, 255), 2)
# 得到结果
output.extend(groupOutput)
# 打印结果
print("Credit Card Type: {}".format(FIRST_NUMBER[output[0]]))
print("Credit Card #: {}".format("".join(output)))
cv2.imshow("Image", image)
cv2.waitKey(0)透视变换

参数一: 传入图片
OCR识别
深度学习

K近邻

 神经网络
神经网络
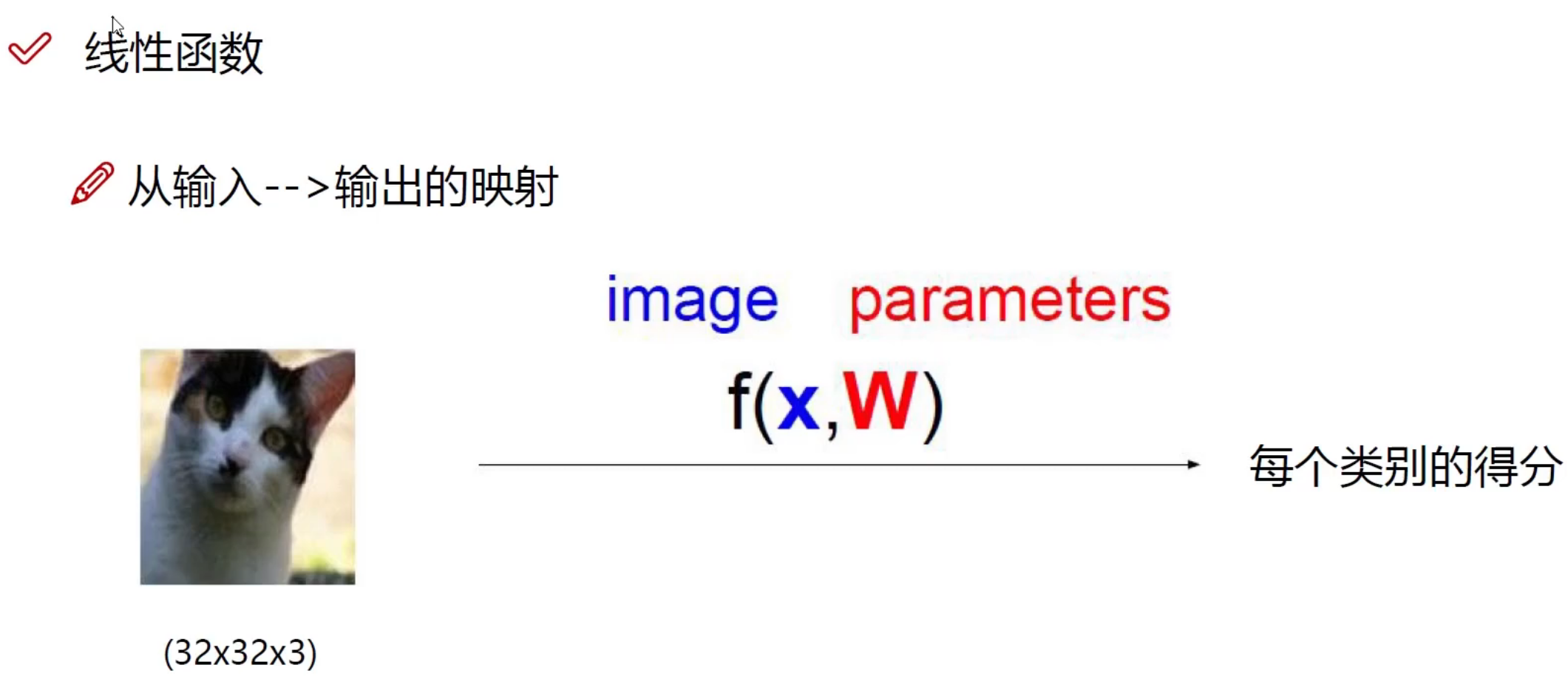
W 权重参数

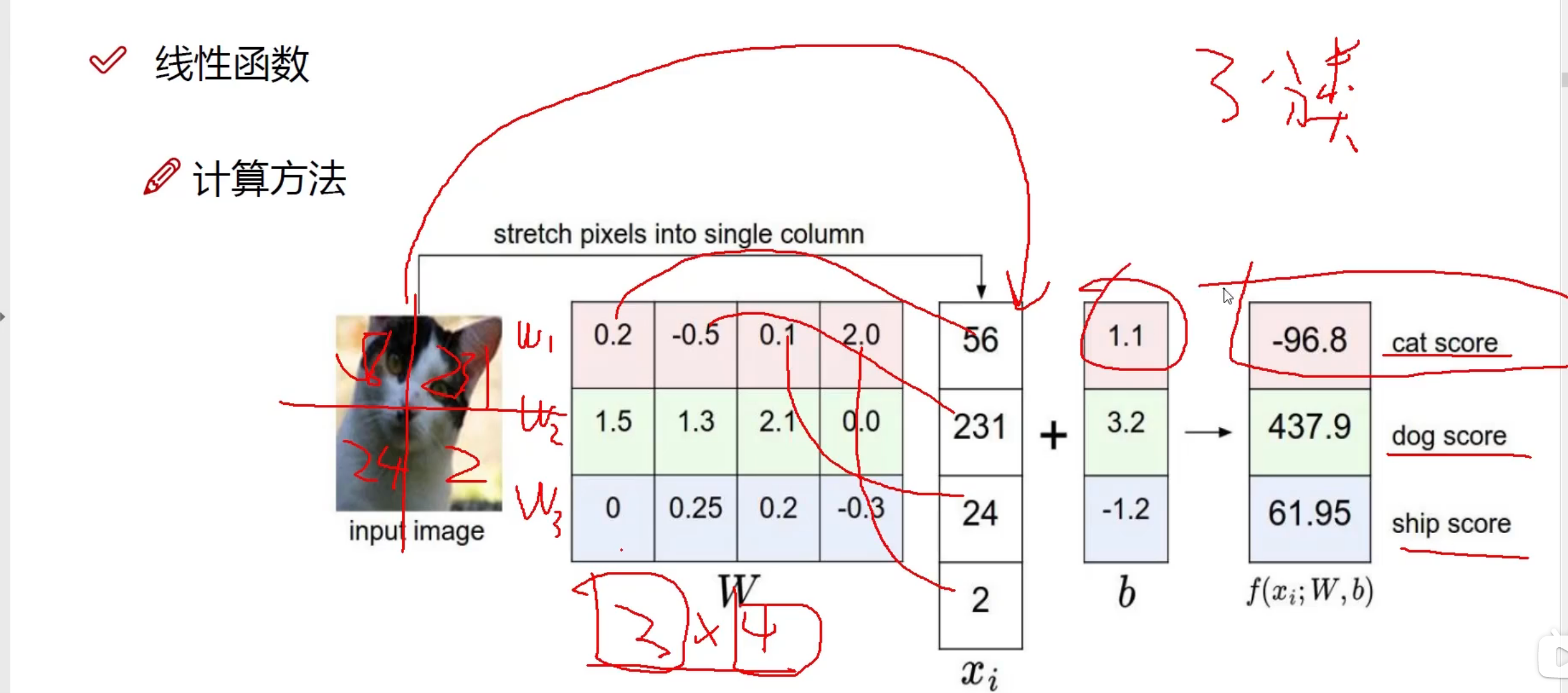
损失函数

 这里的 Δ 就是 1,代表容忍程度
这里的 Δ 就是 1,代表容忍程度


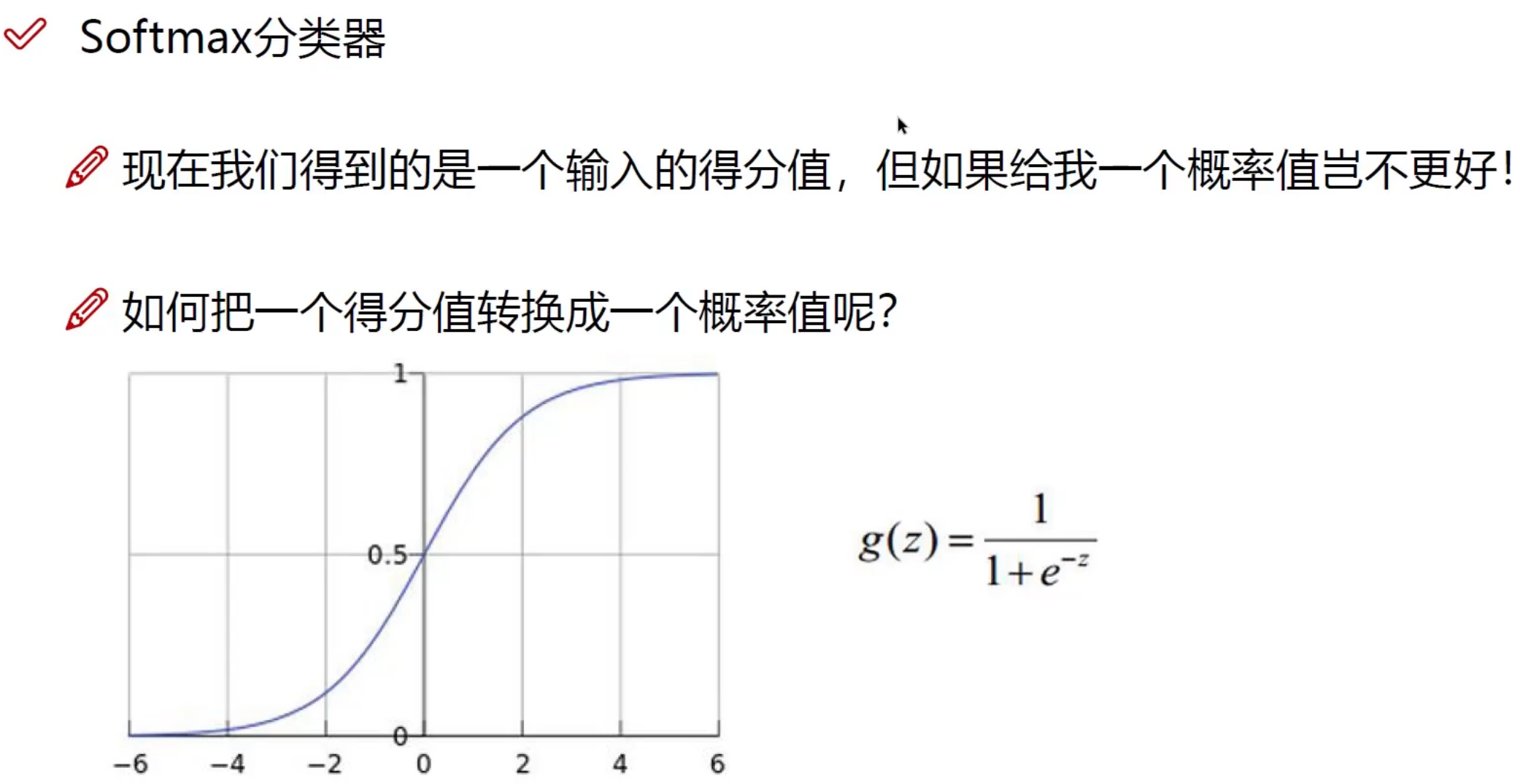
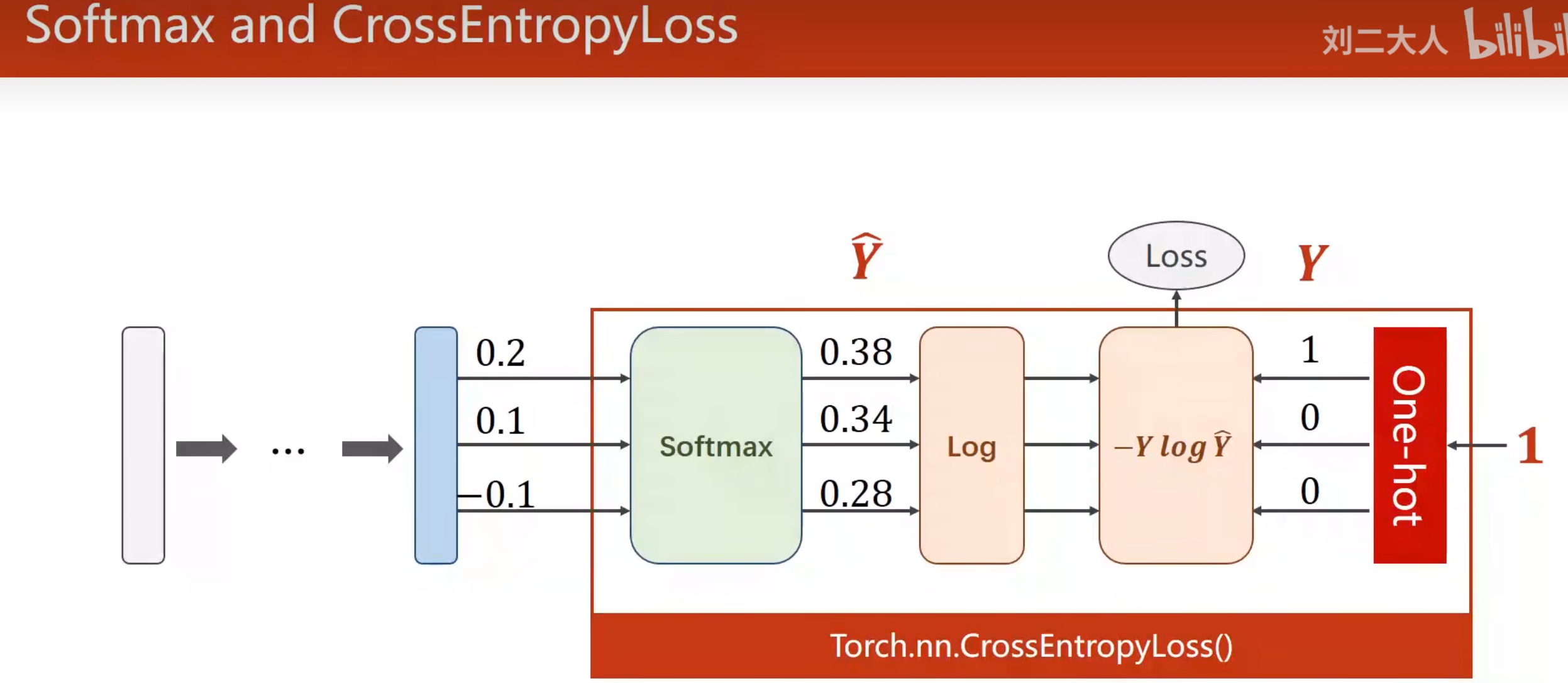
Softmax 分类器

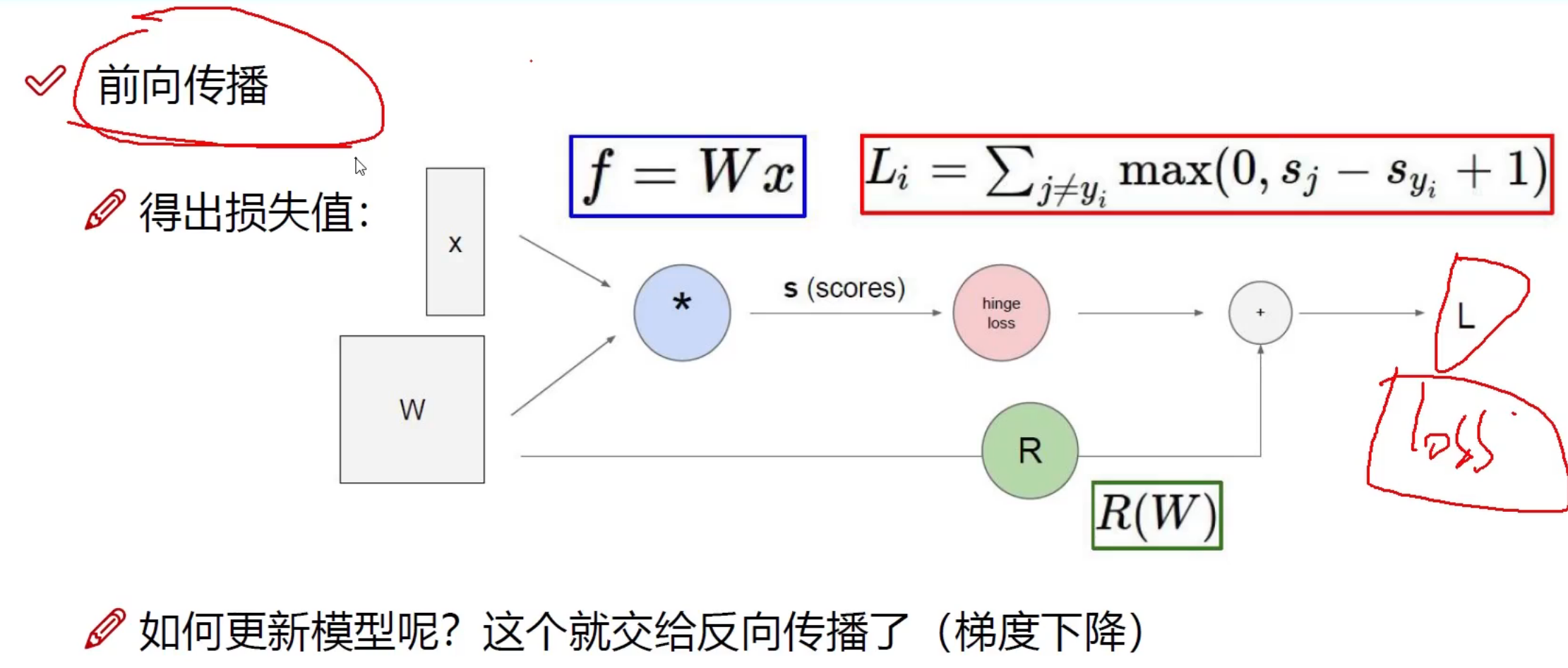
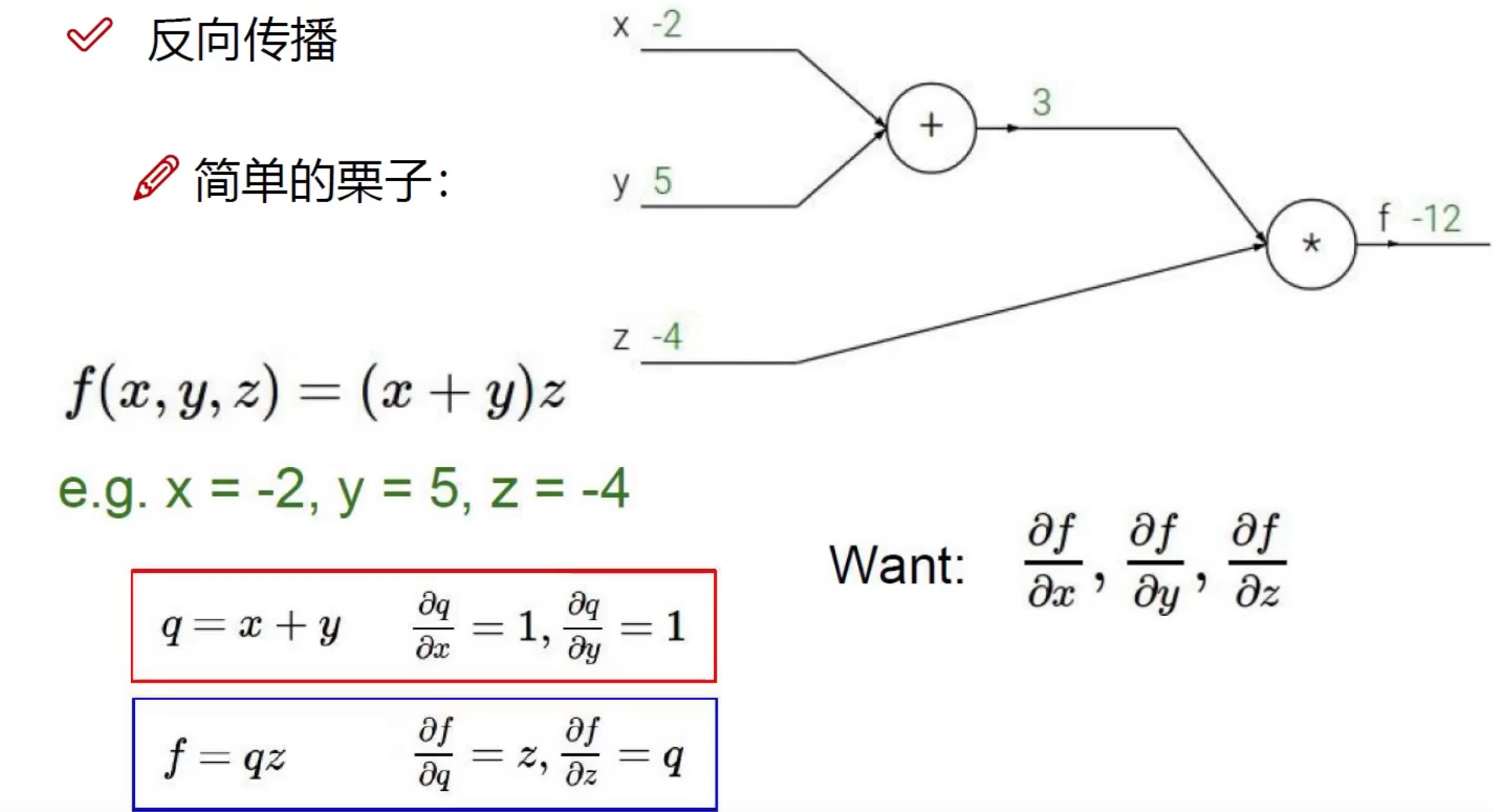
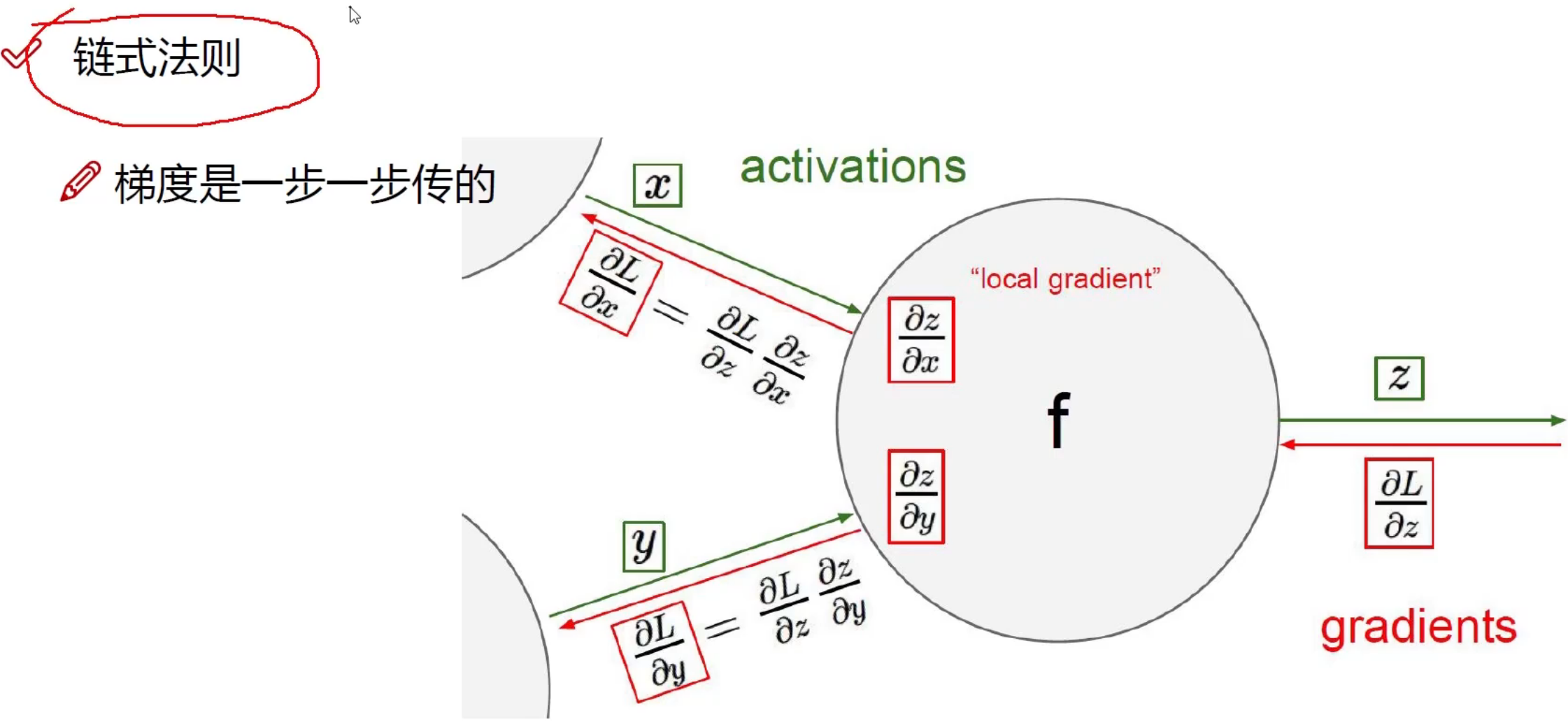
梯度下降

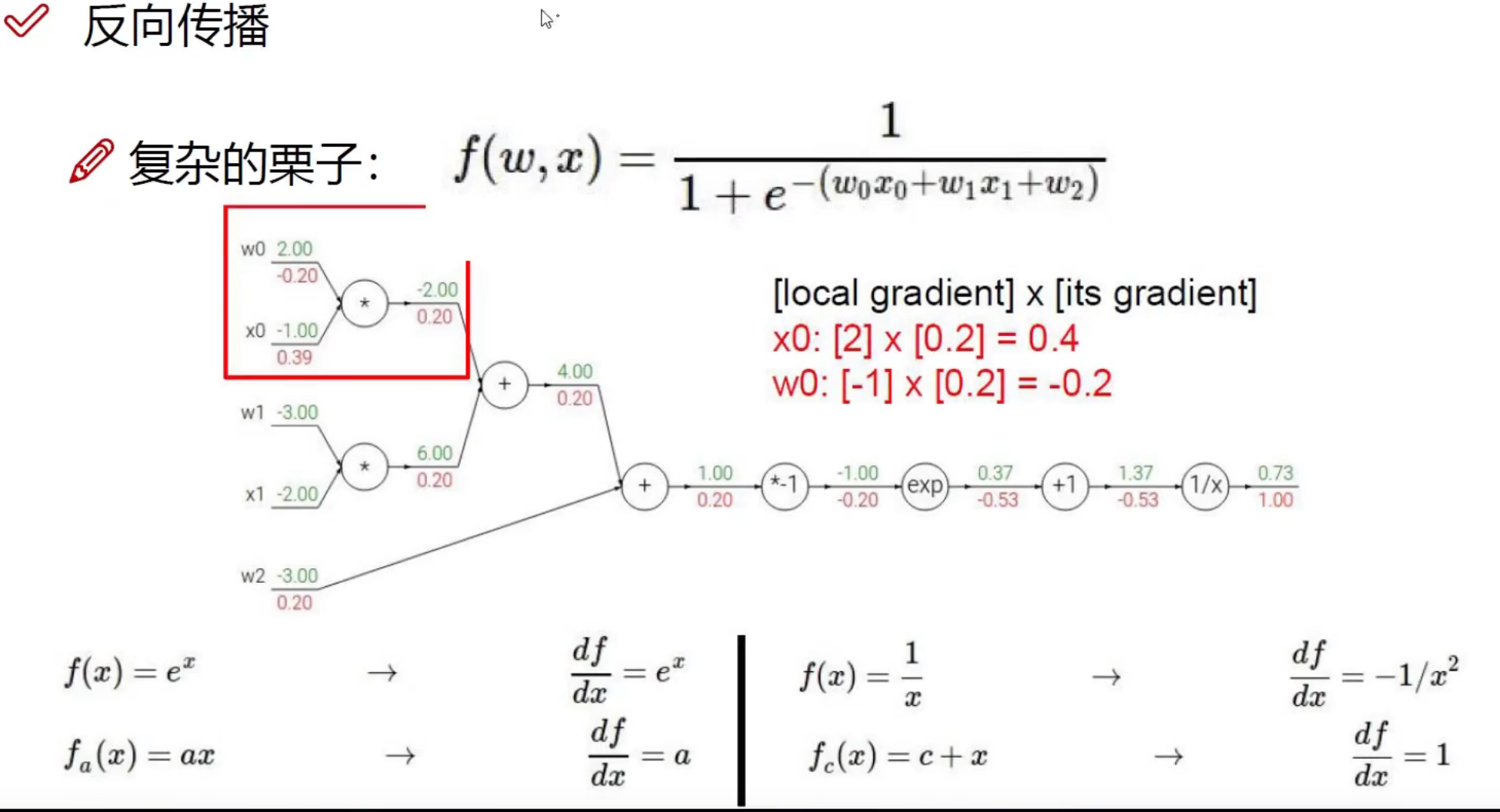
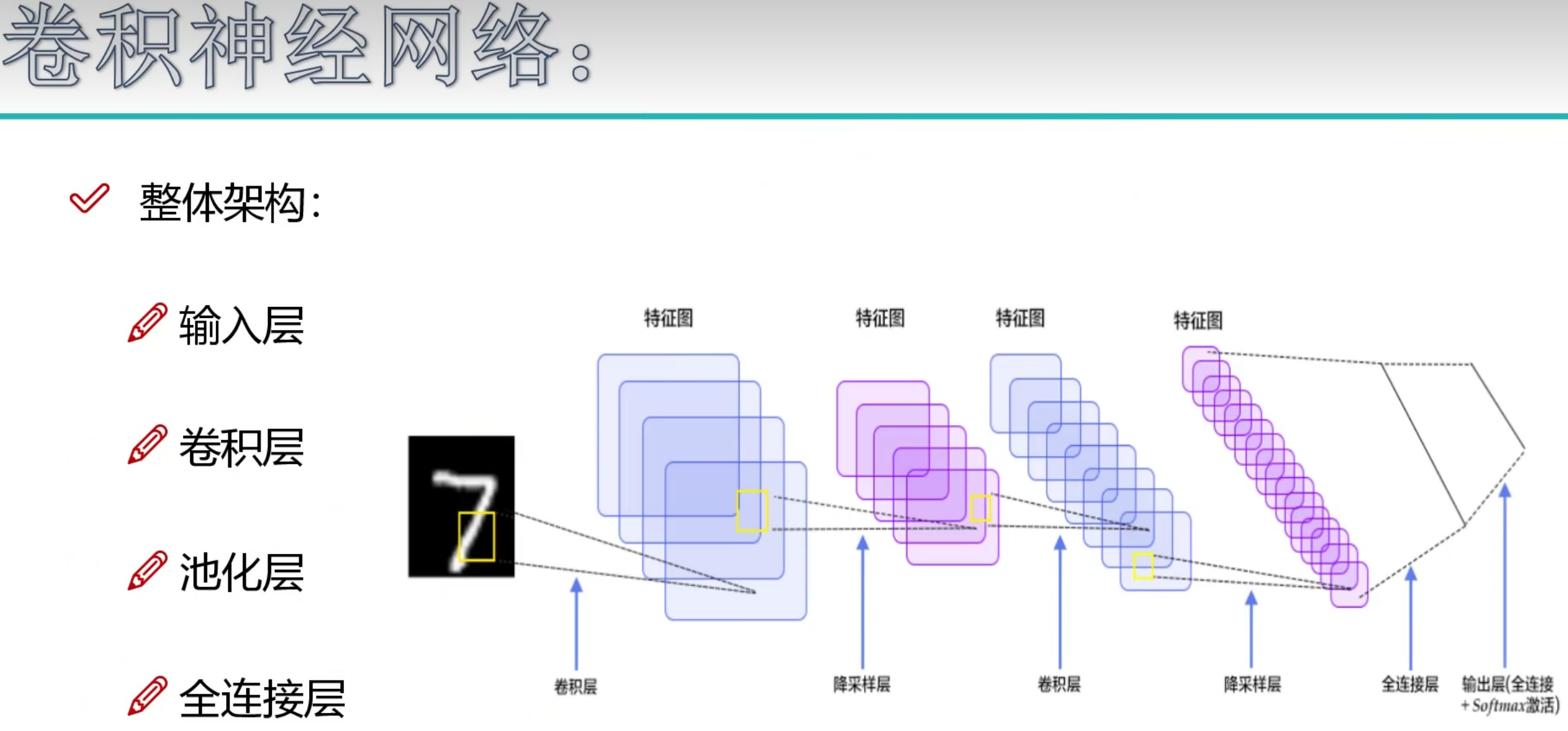
整体架构
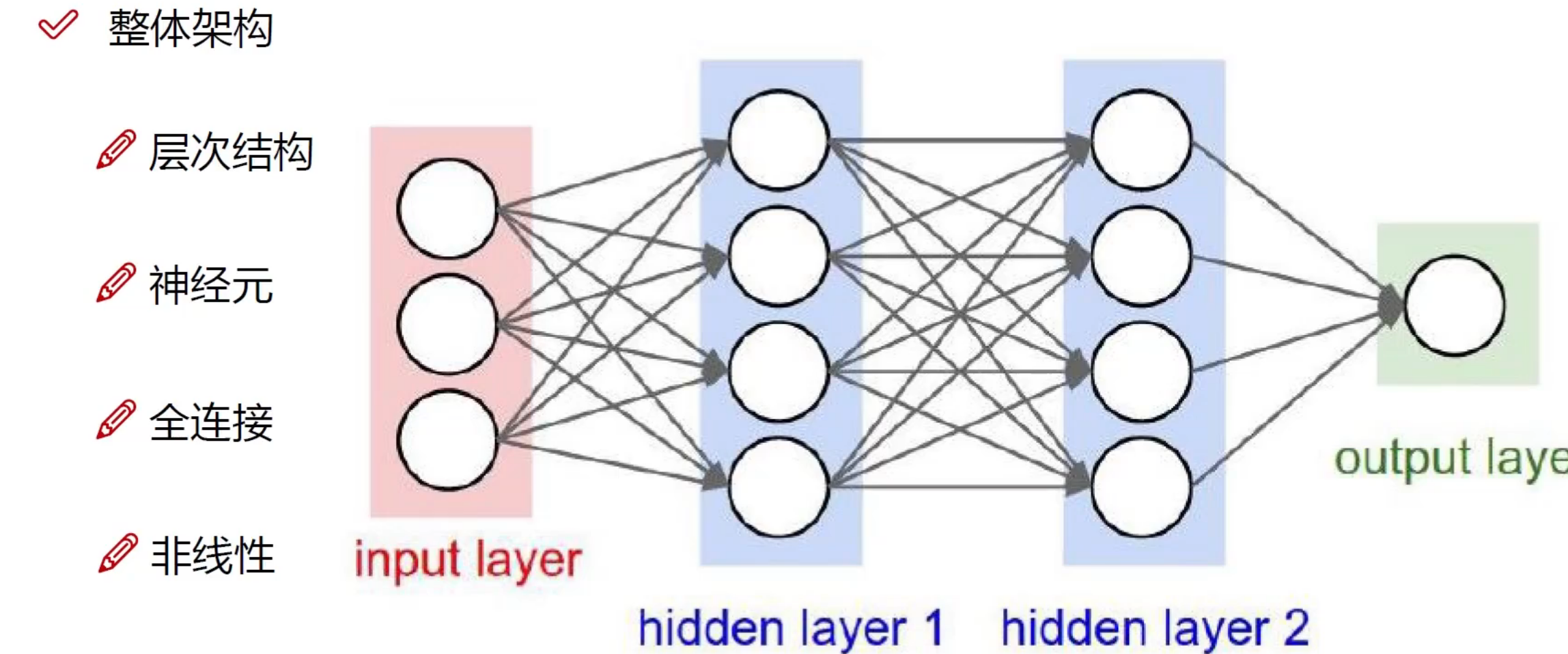
神经元模拟
过拟合的表现以及判定
1、模型过拟合的表现
过拟合(over-fitting),机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在验证数据集以及测试数据集中表现不佳。也就是泛化误差比较大,泛化能力差。从方差和偏差的角度来说,过拟合也就是训练集上高方差,低偏差。为了更加生动形象的表示,我们看一些经典的图:
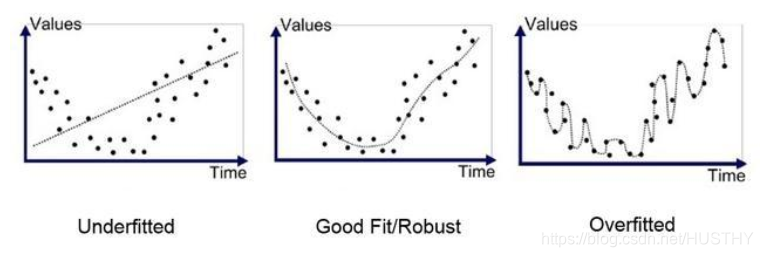
对比这几个图,发现图一的拟合并没有把大体的规律给拟合出来,这个就是欠拟合。图三则是拟合的太细致了,用的拟合函数太复杂了,在这些数据集上的效果很好,但是换到另外的一个数据集效果肯定可预见的不好。只有图二是最好的,把数据的规律拟合出来了,同时在更换数据集后,效果也不会很差。
仔细想想图片三中的模型,拟合函数肯定是一个高次函数,其参数个数肯定肯定比图二的要多,可以说图三的拟合函数比图二的要大,模型更加复杂。这也是过拟合的一个判断经验,模型是否太复杂。另外,针对图三,我们把一些高次变量对应的参数值变小,也就相当于把模型变简单了。这个角度上看,可以减小参数值,也就是一般模型过拟合,参数值整体比较大。从模型复杂性来讲,可以是:
1、模型的参数个数;2、模型的参数值的大小。个数越多,参数值越大,模型就越复杂。
2、模型过拟合的判定
针对模型过拟合这个问题,有没有什么方法来判定模型是否过拟合呢?其实一般都是依靠模型在训练集和验证集上的表现有一个大体的判断就行了。如果要有一个具体的方法,可以参考机器学中,学习曲线来判断模型是否过拟合。如下图:
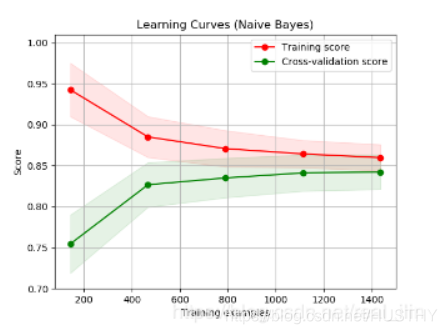
也就是看训练集合验证集随着样本数量的增加,他们之间的差值变化。如果训练集和测试集的准确率都很低,那么说明模型欠拟合;如果训练集的准确率接近于1而验证集还相差甚远,说明模型典型的过拟合。当然具体的差多少这个没有明确的定义,个人看法是,如果训练集95%+,而验证集才60-80直接感觉都是有点过拟合的。
二、过拟合的原因
1、数据量太小
这个是很容易产生过拟合的一个原因。设想,我们有一组数据很好的吻合3次函数的规律,现在我们局部的拿出了很小一部分数据,用机器学习或者深度学习拟合出来的模型很大的可能性就是一个线性函数,在把这个线性函数用在测试集上,效果可想而知肯定很差了。
2、训练集和验证集分布不一致
训练集训练出一个适合训练集那样分布的数据集,当你把模型运用到一个不一样分布的数据集上,效果肯定大打折扣。这个是显而易见的。
3、模型复杂度太大
在选择模型算法的时候,首先就选定了一个复杂度很高的模型,然后数据的规律是很简单的,复杂的模型反而就不适用了。
4、数据质量很差
数据还有很多噪声,模型在学习的时候,肯定也会把噪声规律学习到,从而减小了具有一般性的规律。这个时候模型用来预测肯定效果也不好。
5、过度训练
这个是同第4个是相联系的,只要训练时间足够长,那么模型肯定就会吧一些噪声隐含的规律学习到,这个时候降低模型的性能是显而易见的。
三、过拟合的解决方案
针对过拟合的原因我们可以有针对性的来使用一些方法和技巧来减少过拟合。
1、模型层面
这里主要是减小模型的复杂度,主要是从模型包含的参数个数和参数值。
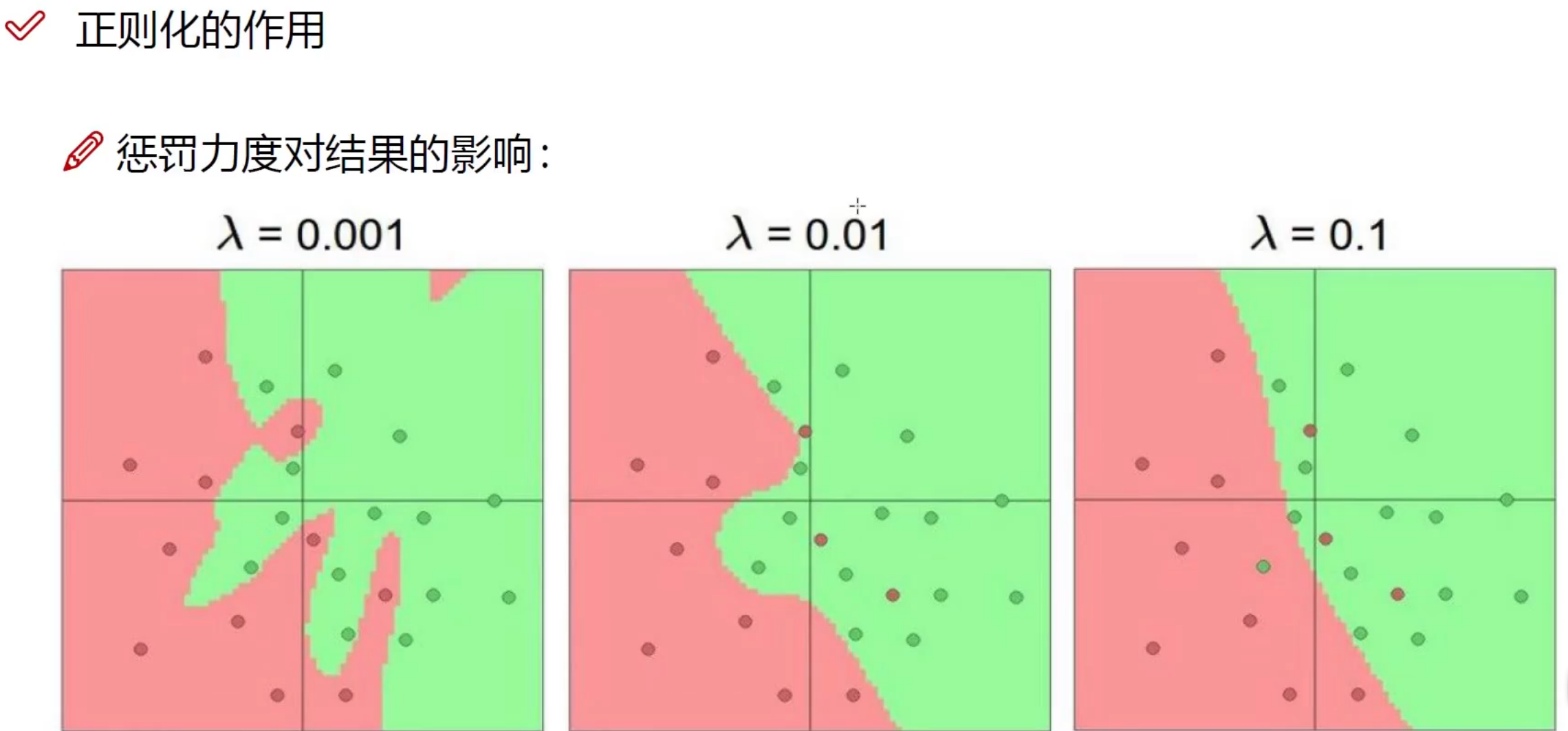
a、正则化
这里包含L1和L2范数,具体的区别去看相关的理论去了解,这里一般使用L1范数,使得模型拟合的参数大部分都为0,这样就可以说从参数值和参数个数的角度减少了模型的复杂度,从而降低了过拟合。
b、权值共享
这个方法常用于深度学习中,一般在网络中,某些层可能会使用同样的参数,那么这样就在参数个数上减小了——模型复杂度也随之降低
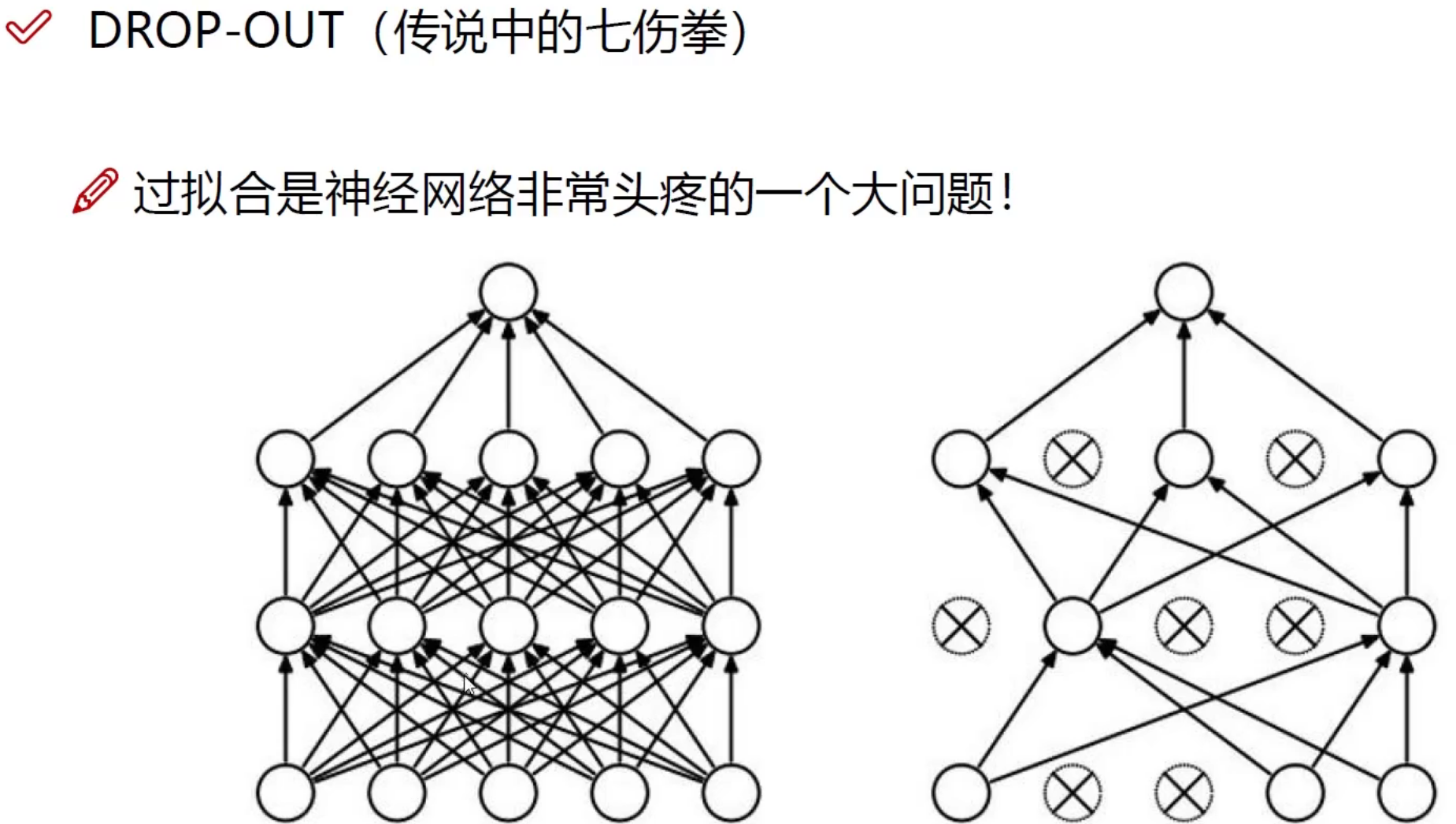
c、dropout
这个方法也很常见,在神经网络中以一定的概率使得神经元不工作。这种方法的本质上是没一个step中,使用的模型都是不一样的,并且模型参数在一定程度上也是减少了。
torch.nn.Dropout(0.5)
在pytorch中,这里的0.5的意思就是神经元不保留的概率,这个与tf框架不同。
d、Batch Normalization
这个批归一化处理层,是一个作用非常大的。我自己在写网络中也尝试在使用这个BN层,其作用是:使得每一层的数据分布不变,做归一化处理,加快了模型的收敛速度,避免梯度消失、提高准确率。反正就是优点很多!
e、权值衰减
权值衰减——weight_decay,简单的理解就是乘在正则项的前面的系数,目的是为了使得权值衰减到很小的值,接近如0。一般在深度学习好中,pytorch的提供的优化器都可以设置的:
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum=0.9,weight_decay=1e-5)2、数据层面
a、保证数据集分布一致性
在切分数据集的时候要保证分布一致性。可以使用sklearn包中,model_selection相关train_text_split来实现数据集切割后分布的一致性。
b、增加数据集的规模
最好的是人工标注高质量的数据,但是成本非常高;可以采用一定的数据增强策略,来实现数据集的扩充。注意的是这里可能会引入一定的噪声,噪声也会影响模型的性能的,要注意利弊的取舍。另外CV和NLP的数据增强是不一样的,NLP数据增强更难。
3、训练层面
这个训练就要看经验了,模型需要到达什么样的一个基线标准。然后参考这个标准对模型实施early-stopping。神经网络的训练过程中我们会初始化一组较小的权值参数,随着模型的训练,这些权值也变得越来越大了。为了减小过拟合的影响,就有可能需要早停止了。我本人没有使用过early-stopping,一般都是设置10个epoch然后看效果来考虑时候增加epochs的次数。
4、其他
集成学习——也就是一个均值的思想,通过集成的思想来减弱过拟合的影响。
正则化的作用
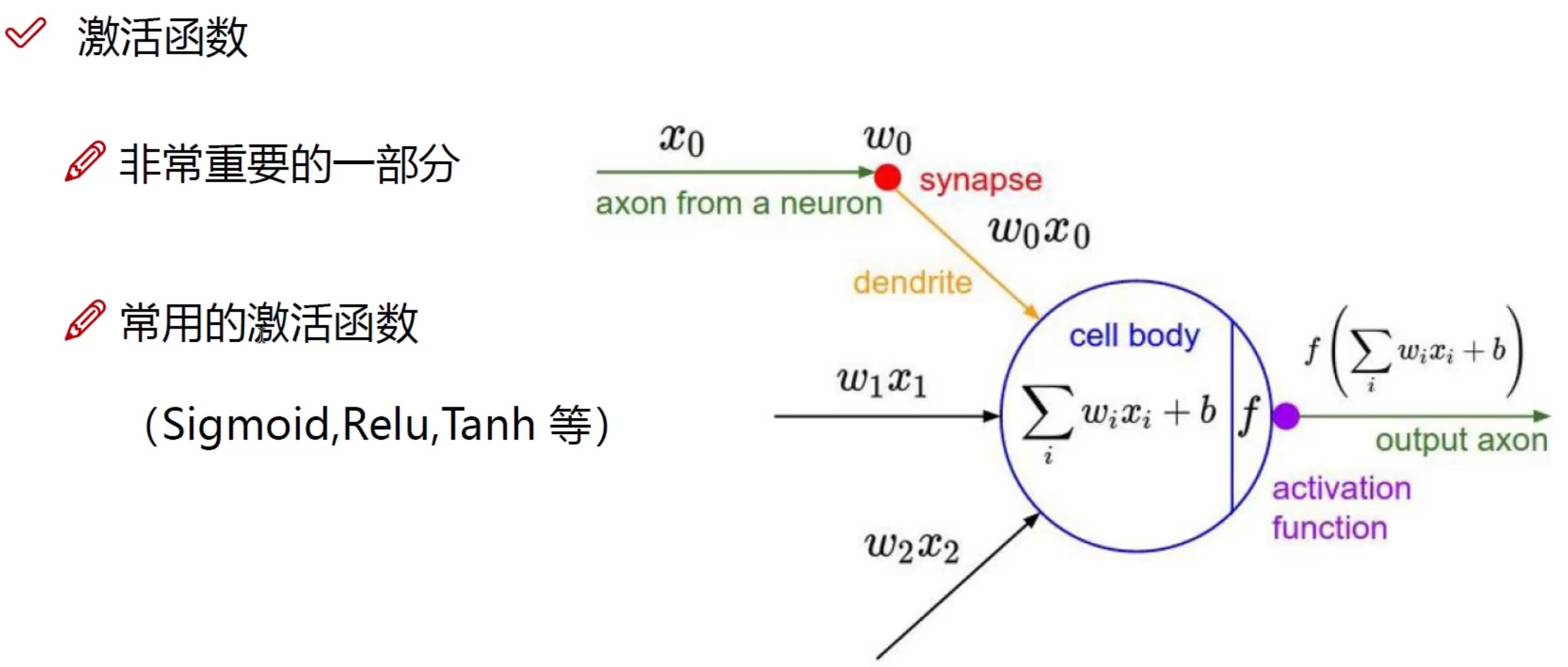
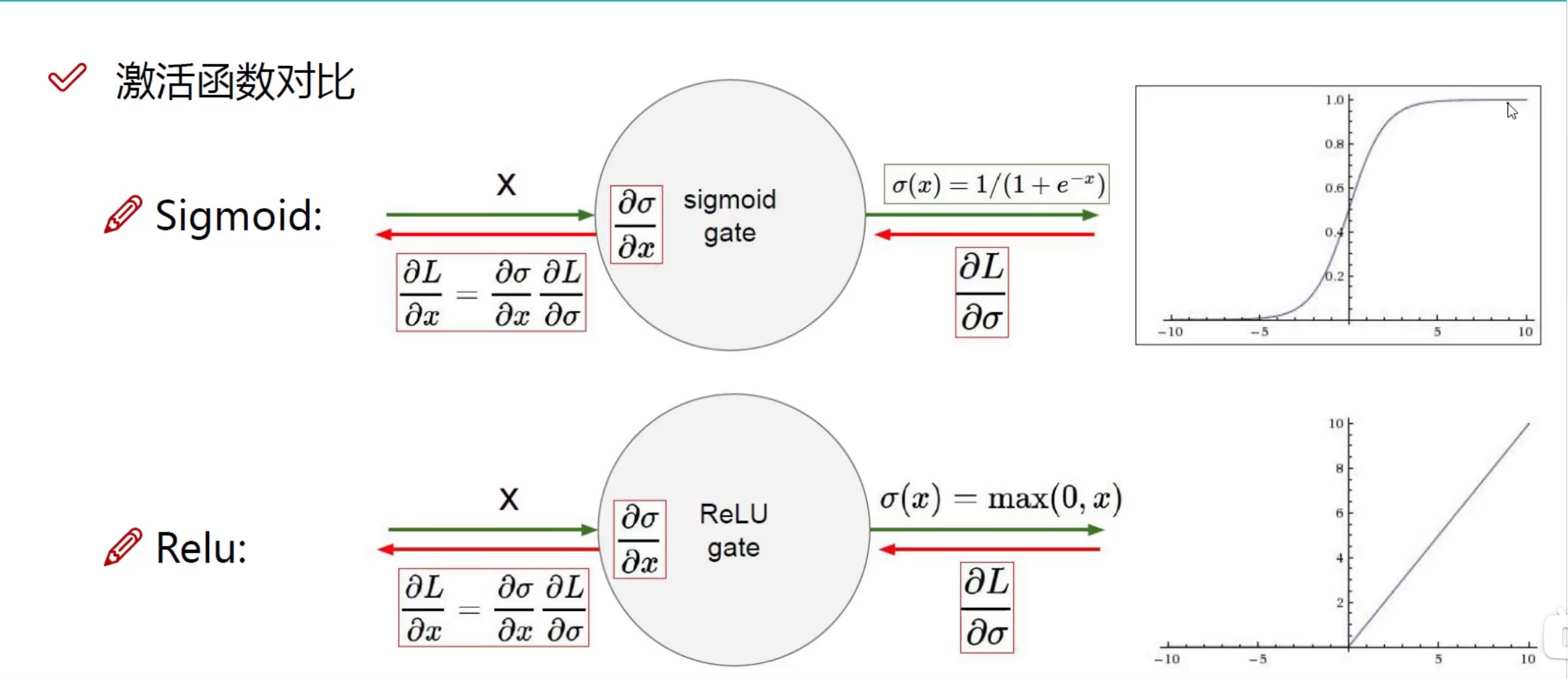
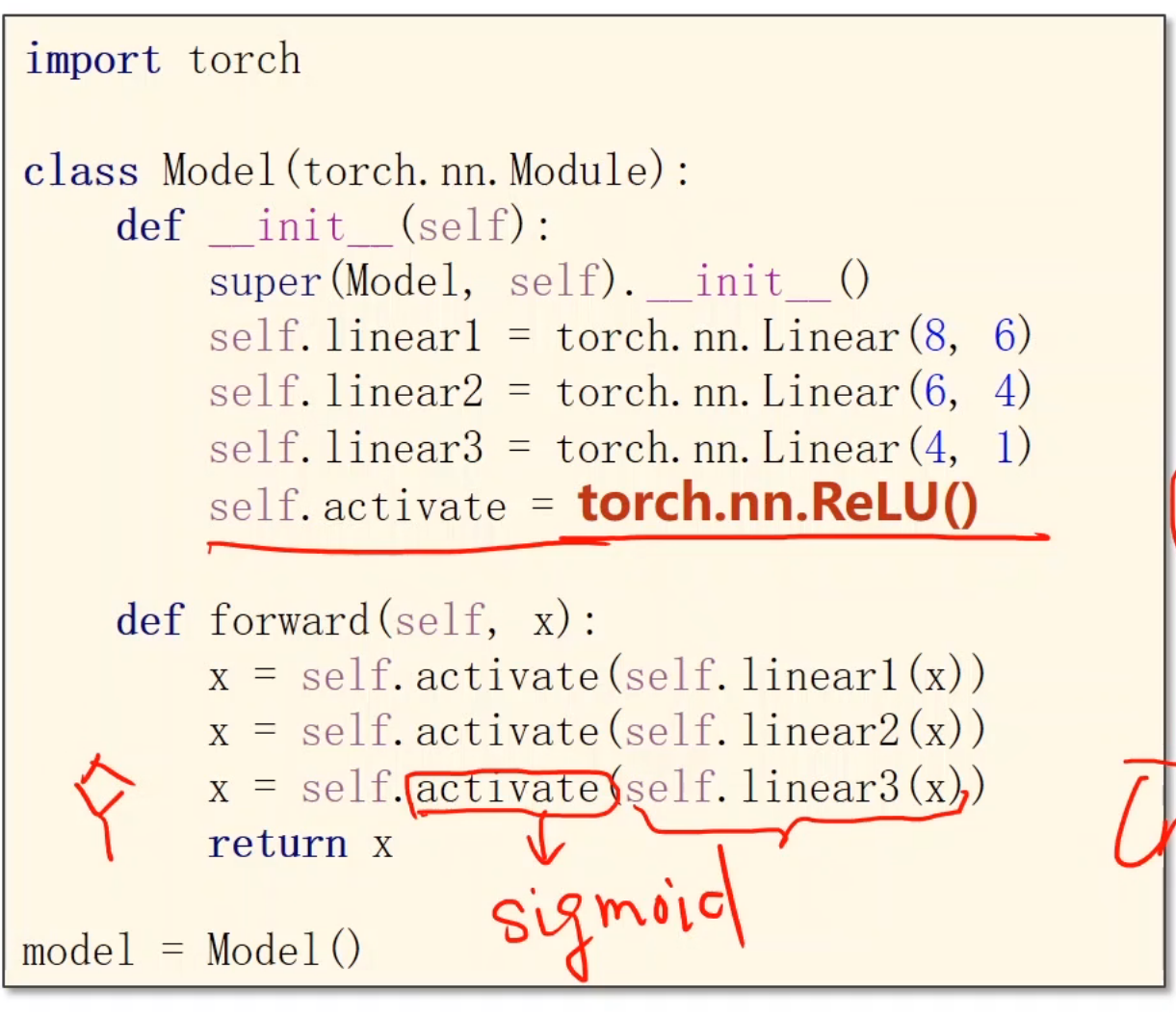
 激活函数
激活函数

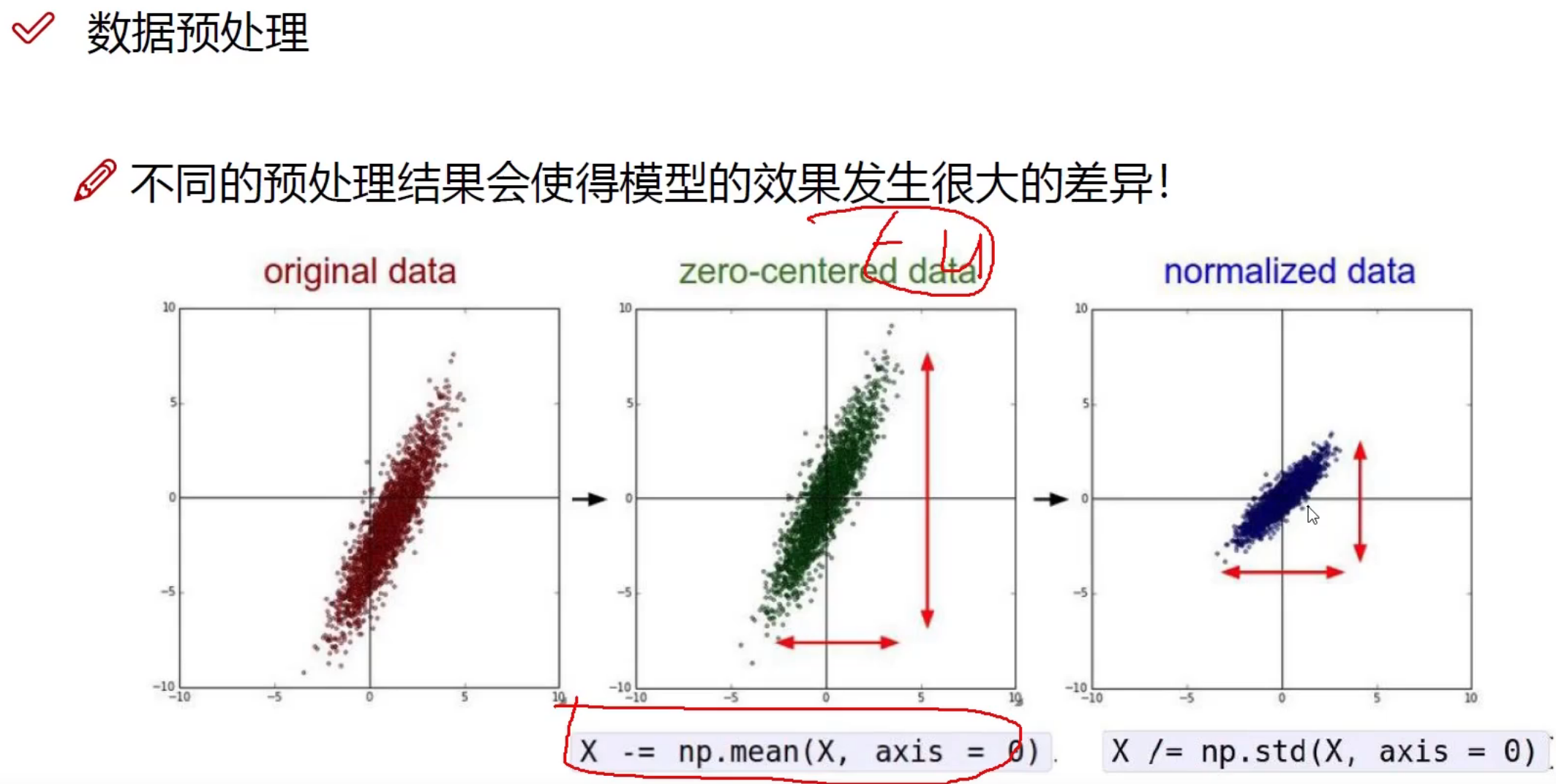
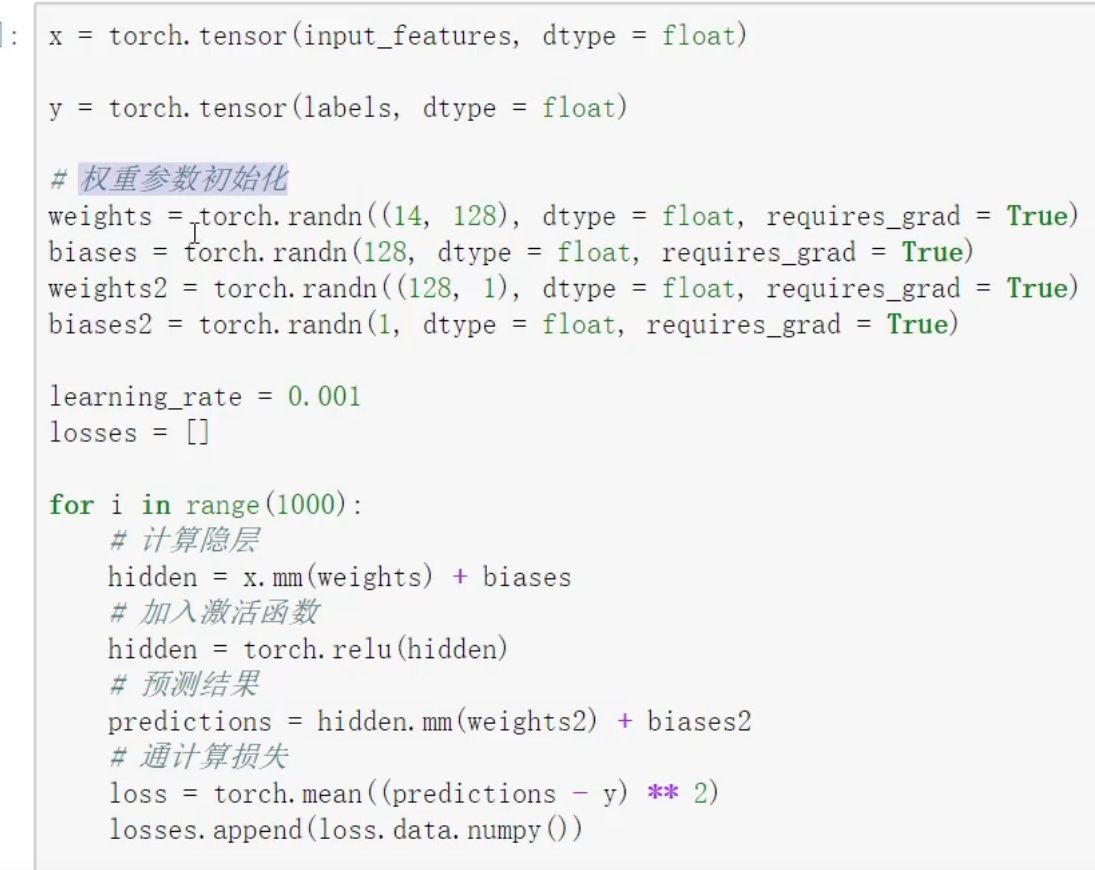
数据预处理
 0.01 : 稳定权重的值
0.01 : 稳定权重的值
D, H : 是权重参数 例如(3x4)
DROP-OUT(抗过拟合)
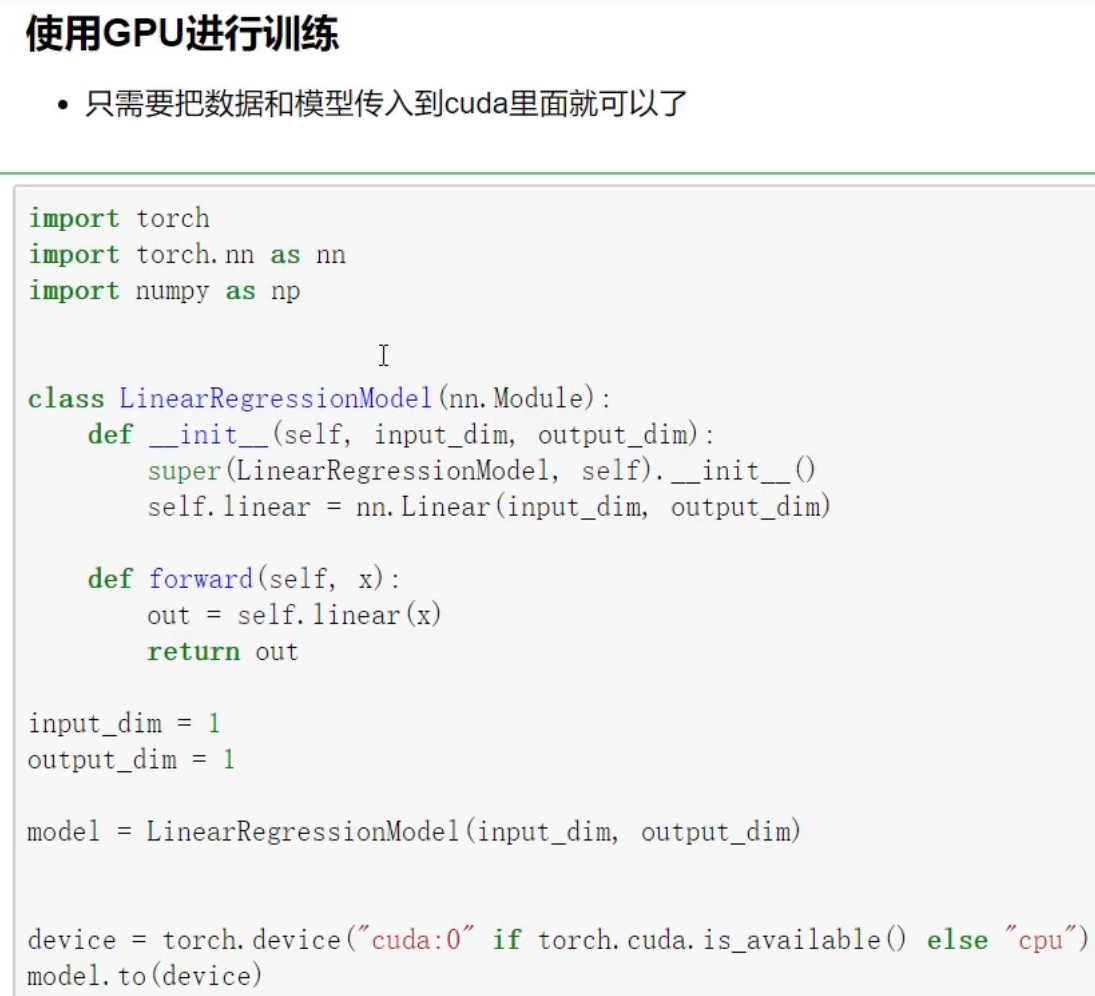
PyTorch
https://pytorch.org/get-started/locally/
反向传播过程
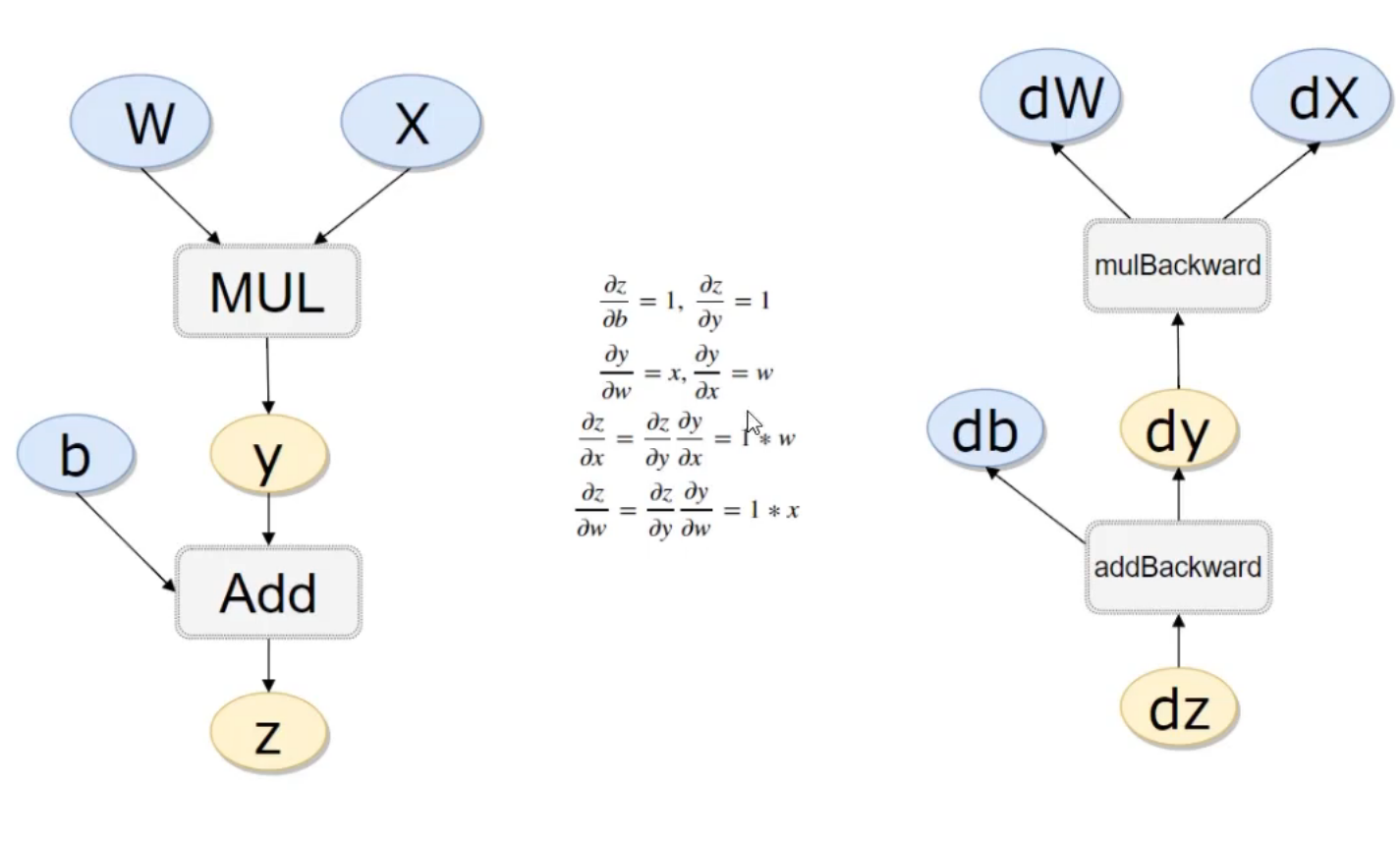

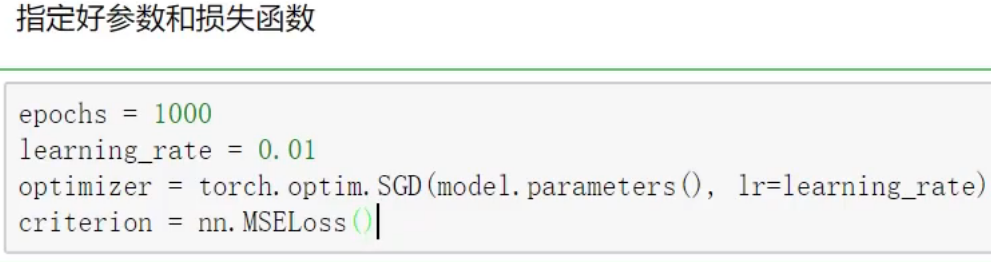
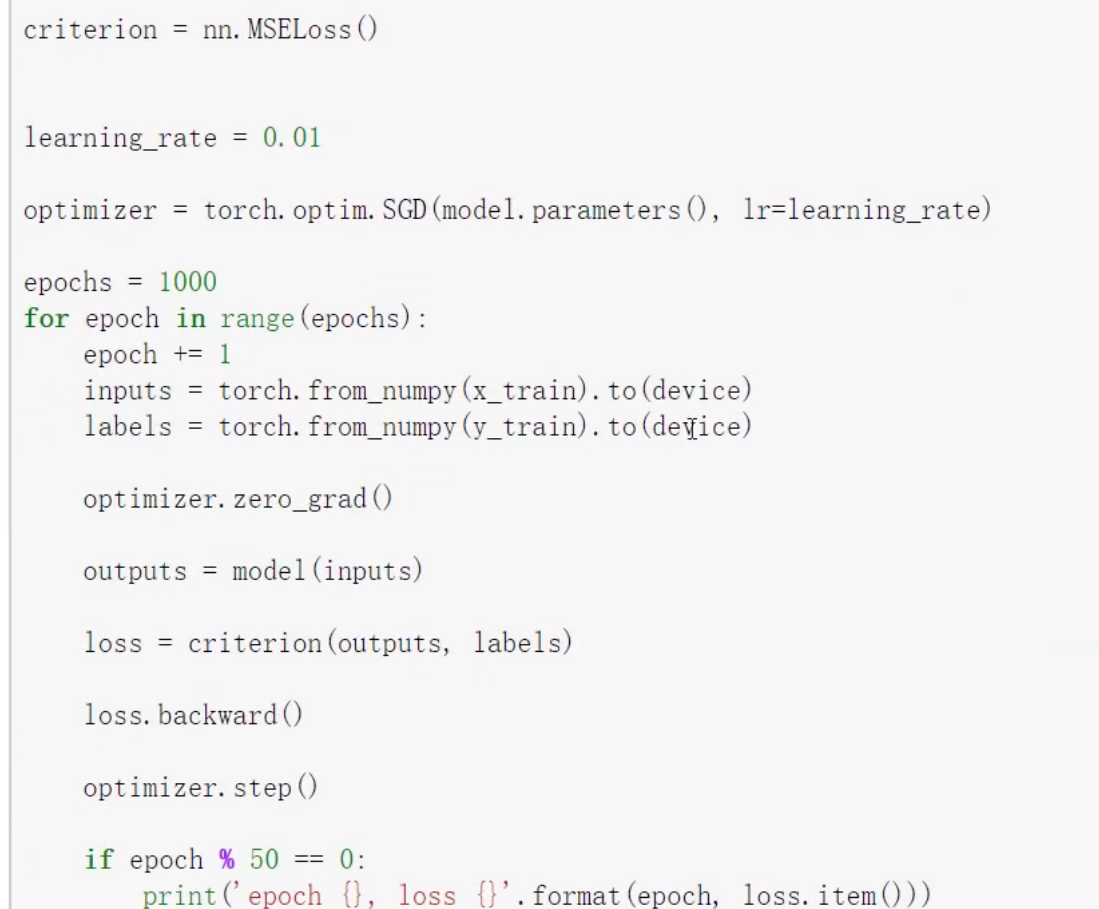
epochs被定义为向前和向后传播中所有批次的单次训练迭代。这意味着一个周期是整个数据的单次向前和向后传递。简单说,epochs指的就是训练过程中数据将被“轮”多少次,就这样。
为了使用torch.optim,你需要构建一个optimizer对象。这个对象能够保持当前参数状态并基于计算得到的梯度进行参数更新。
动手学深度学习-多层感知机中:updater = torch.optim.SGD(params, lr=lr)。其中的updater就是一个optimizer对象。
MSELoss 损失函数
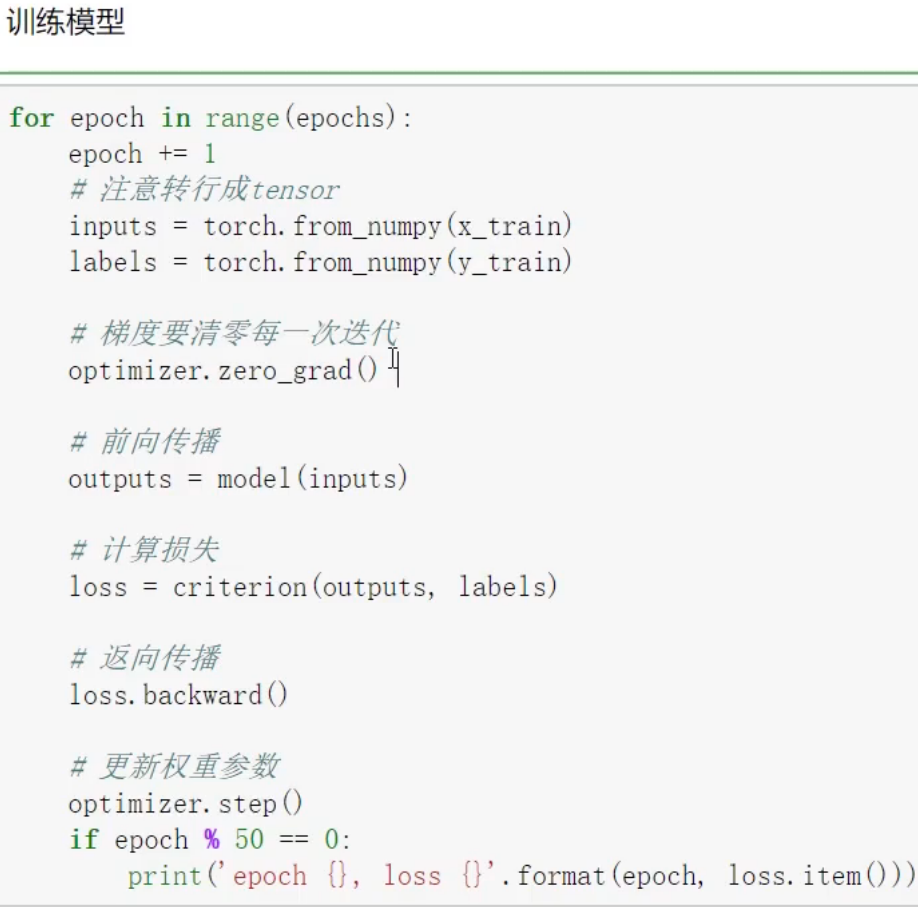

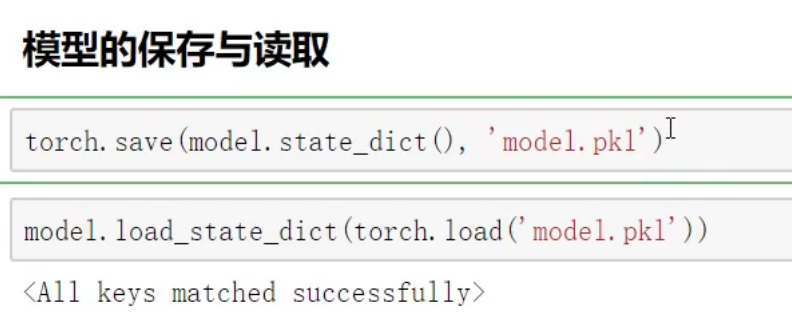 模型里面储存的是 W 和 b
模型里面储存的是 W 和 b




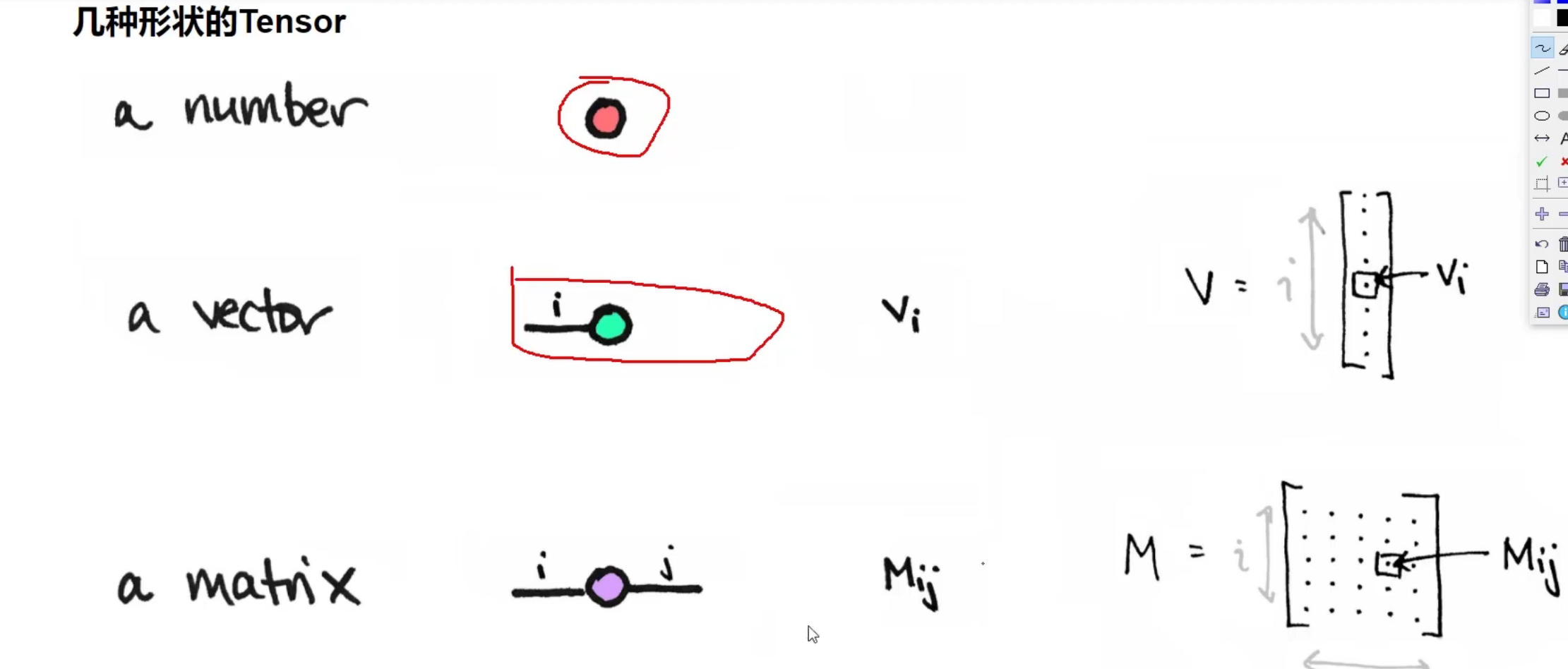
 #求所有元素的平均值:input是要处理的张量;返回值是1个数,张量形式
#求所有元素的平均值:input是要处理的张量;返回值是1个数,张量形式
torch.mean(input, *, dtype=None) → Tensor
#沿张量中某个维度求平均值:input是要处理的张量,dim是想求的维度,keepdim是否保留长度为1的维度;返回值是张量形式,维数默认和原张量一样。
torch.mean(input, dim, keepdim=False, *, dtype=None, out=None) → Tensor


optim.Adam() 动态更新学习率
线性回归
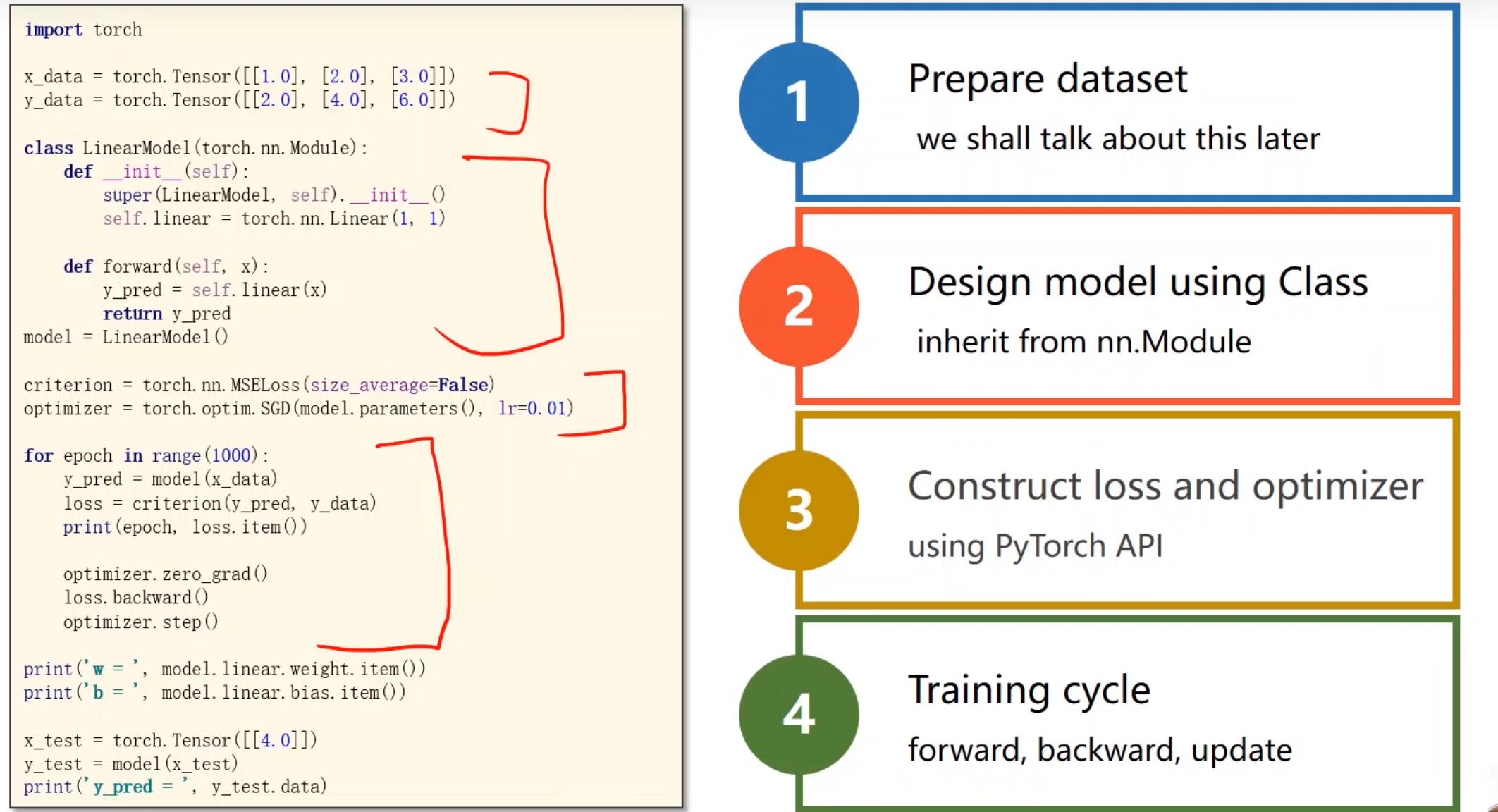
优化器

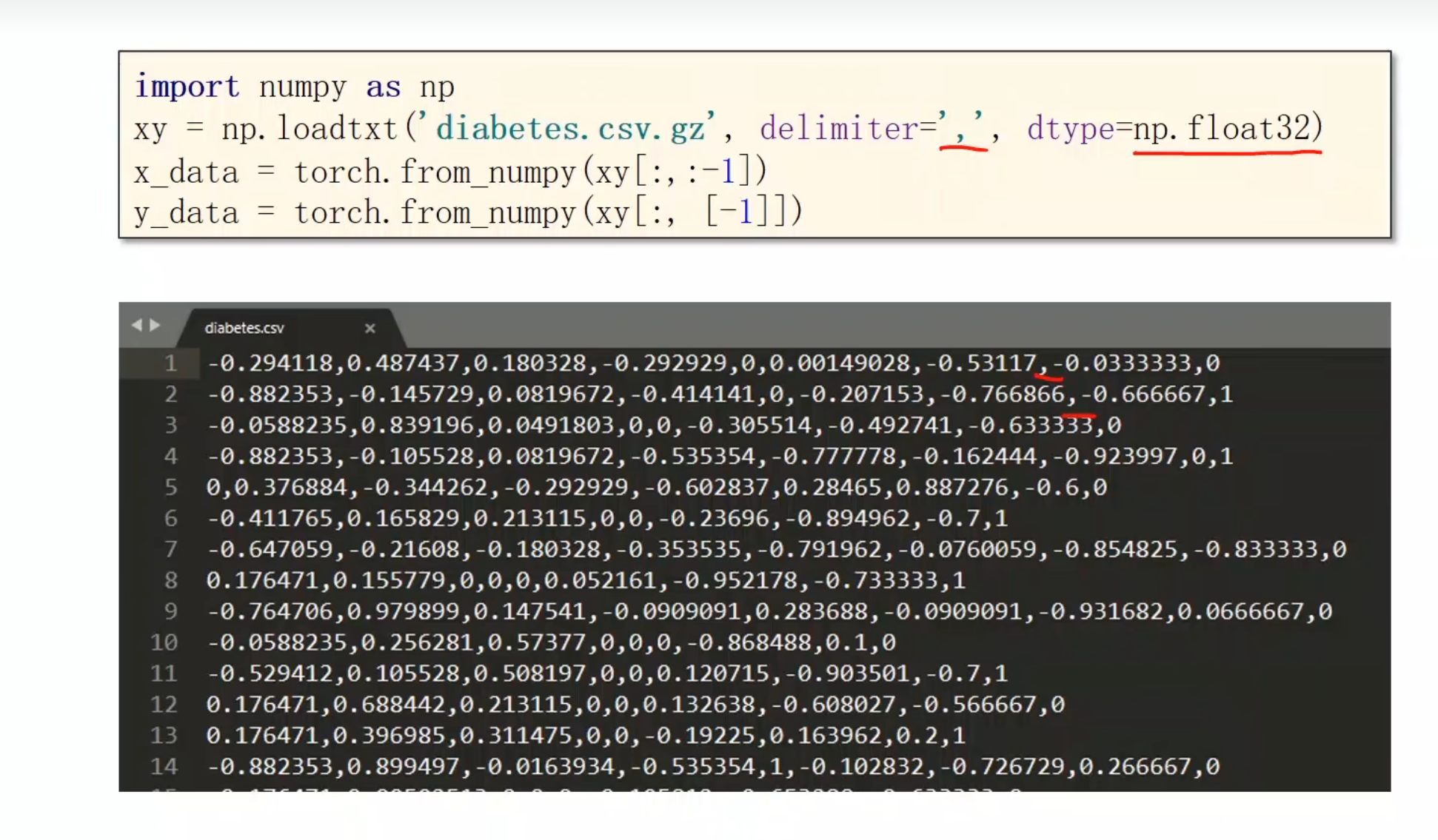
数据读取
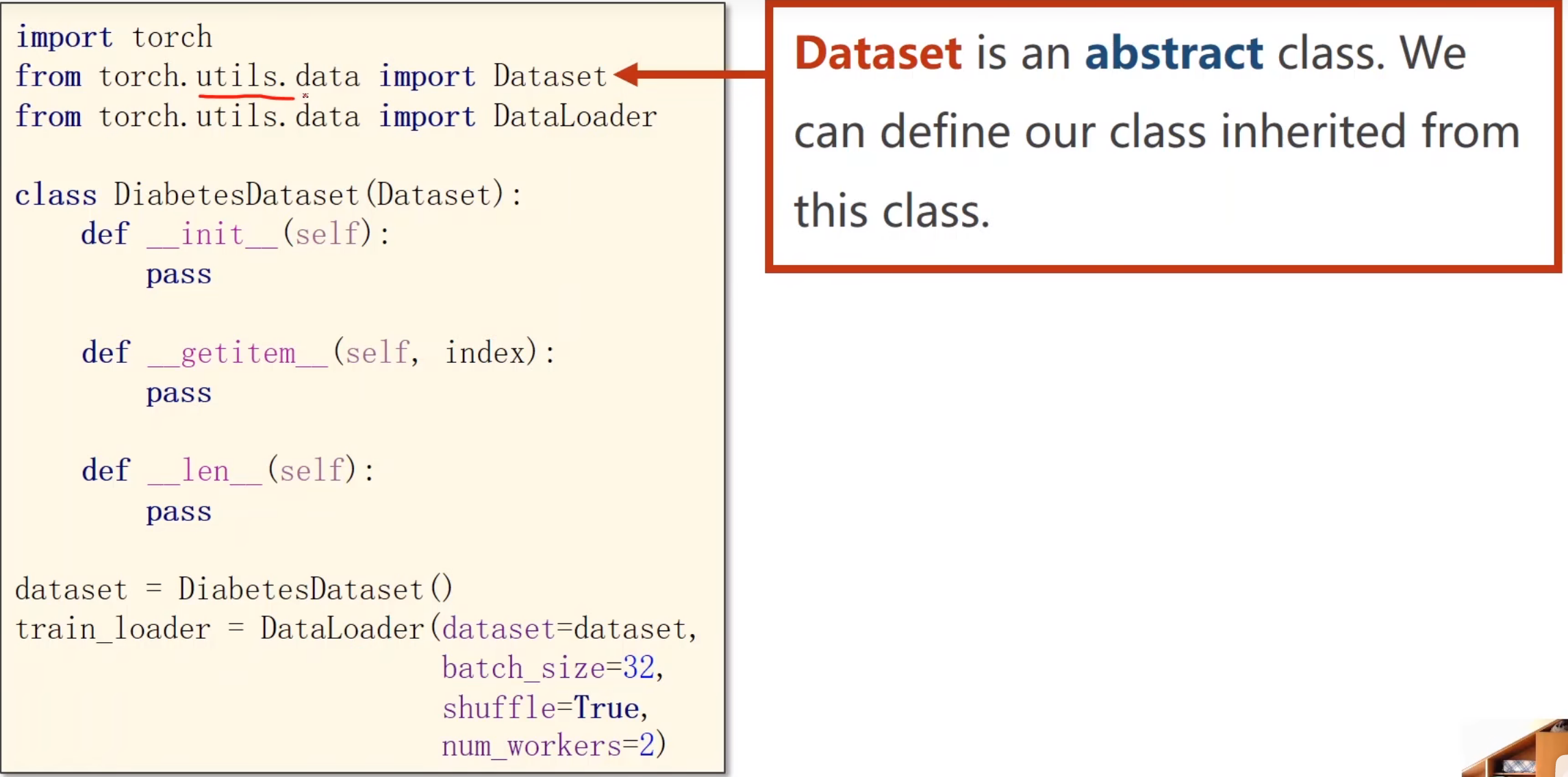
数据集的加载
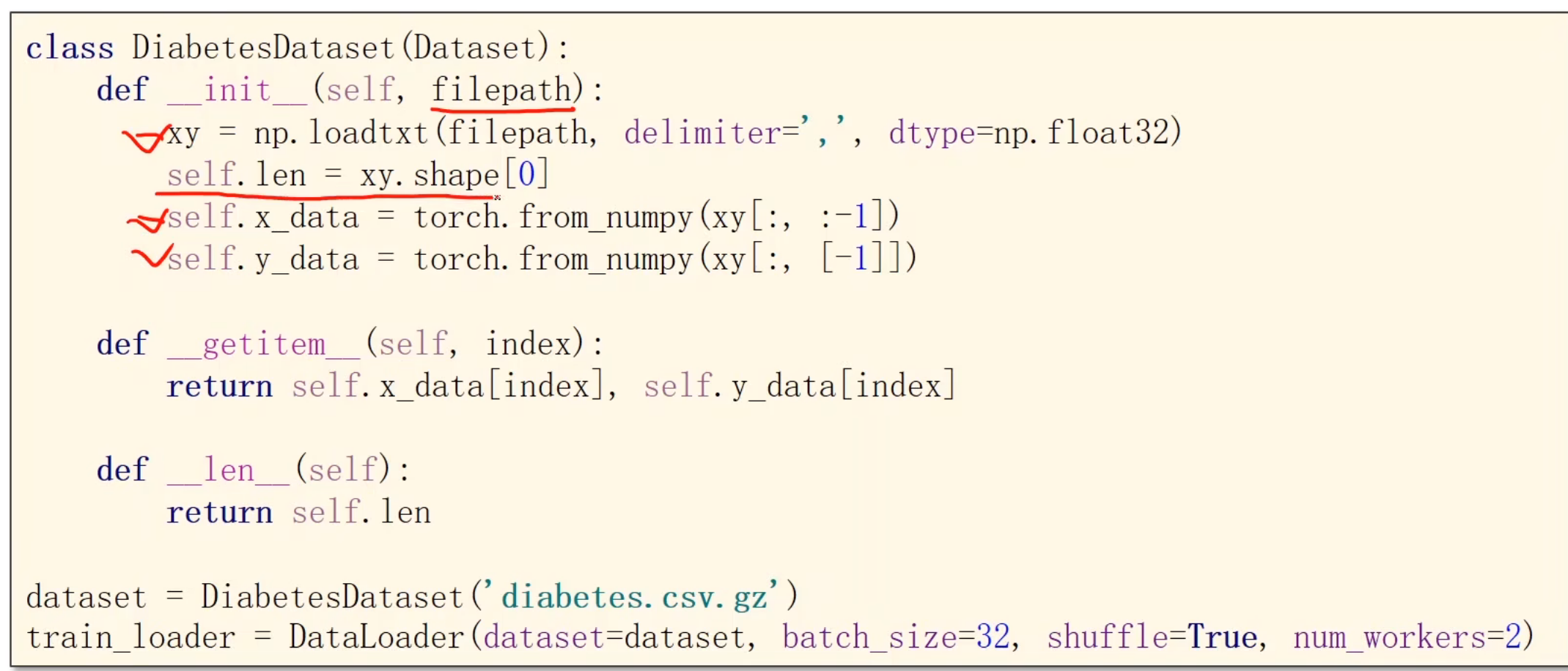
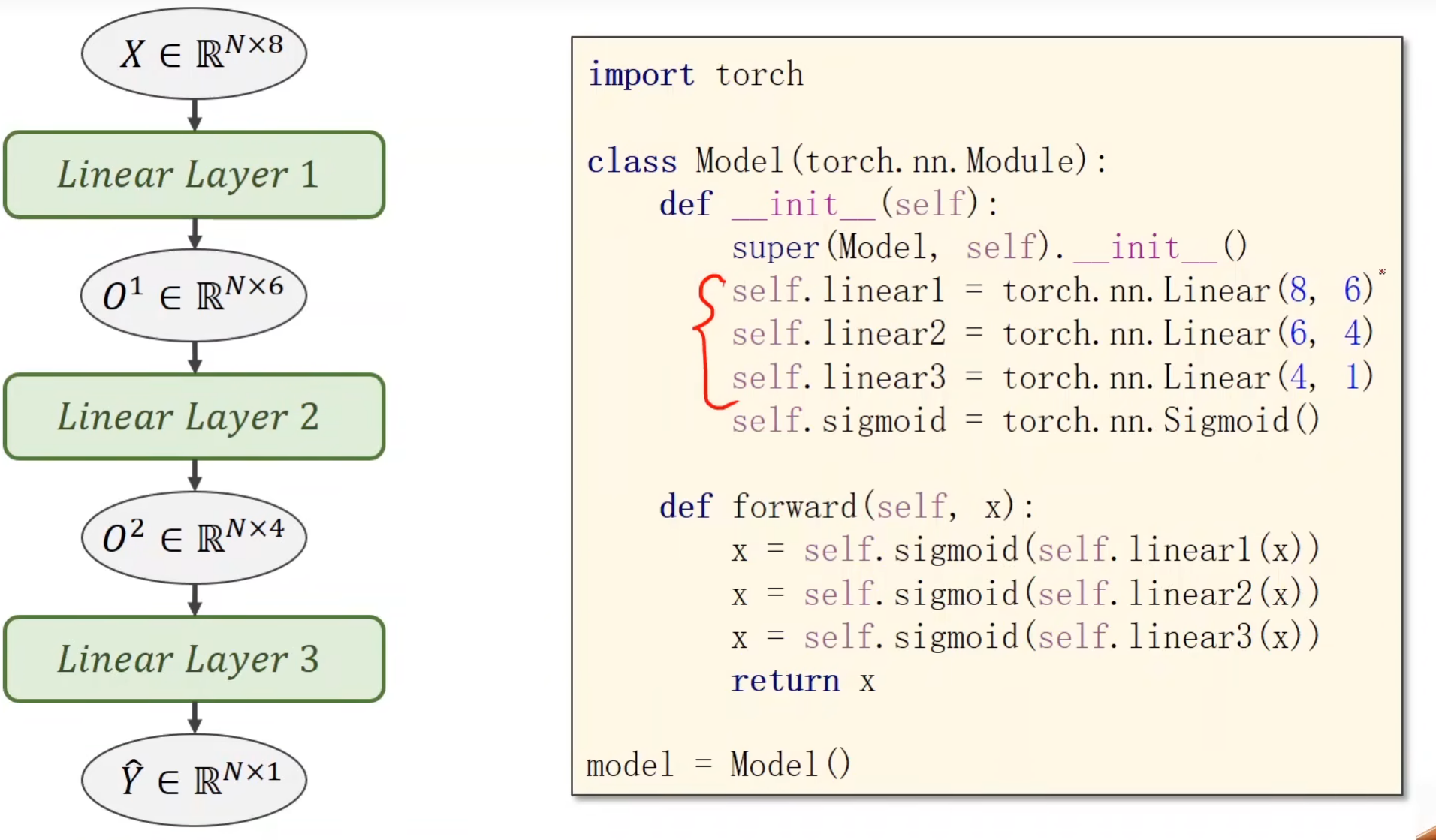
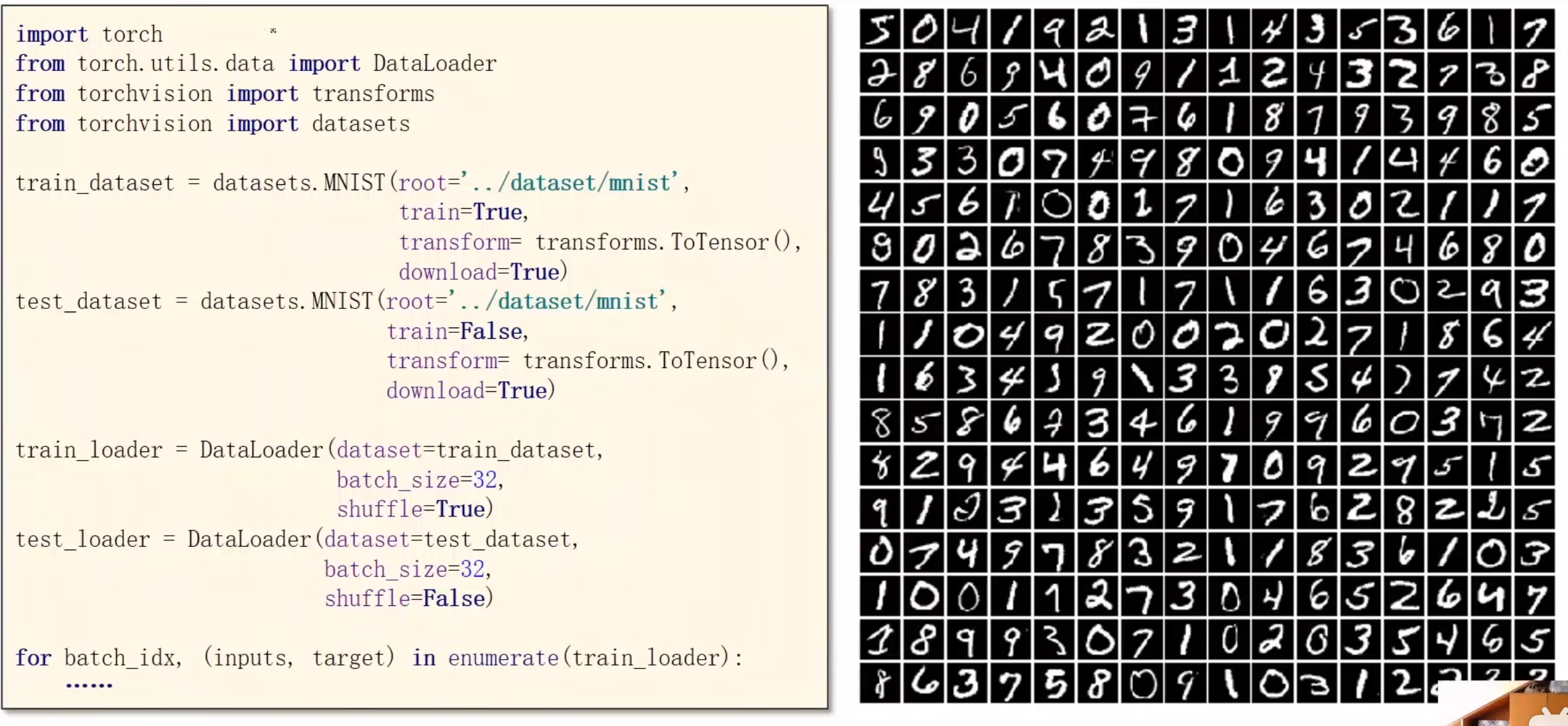 多分类问题
多分类问题
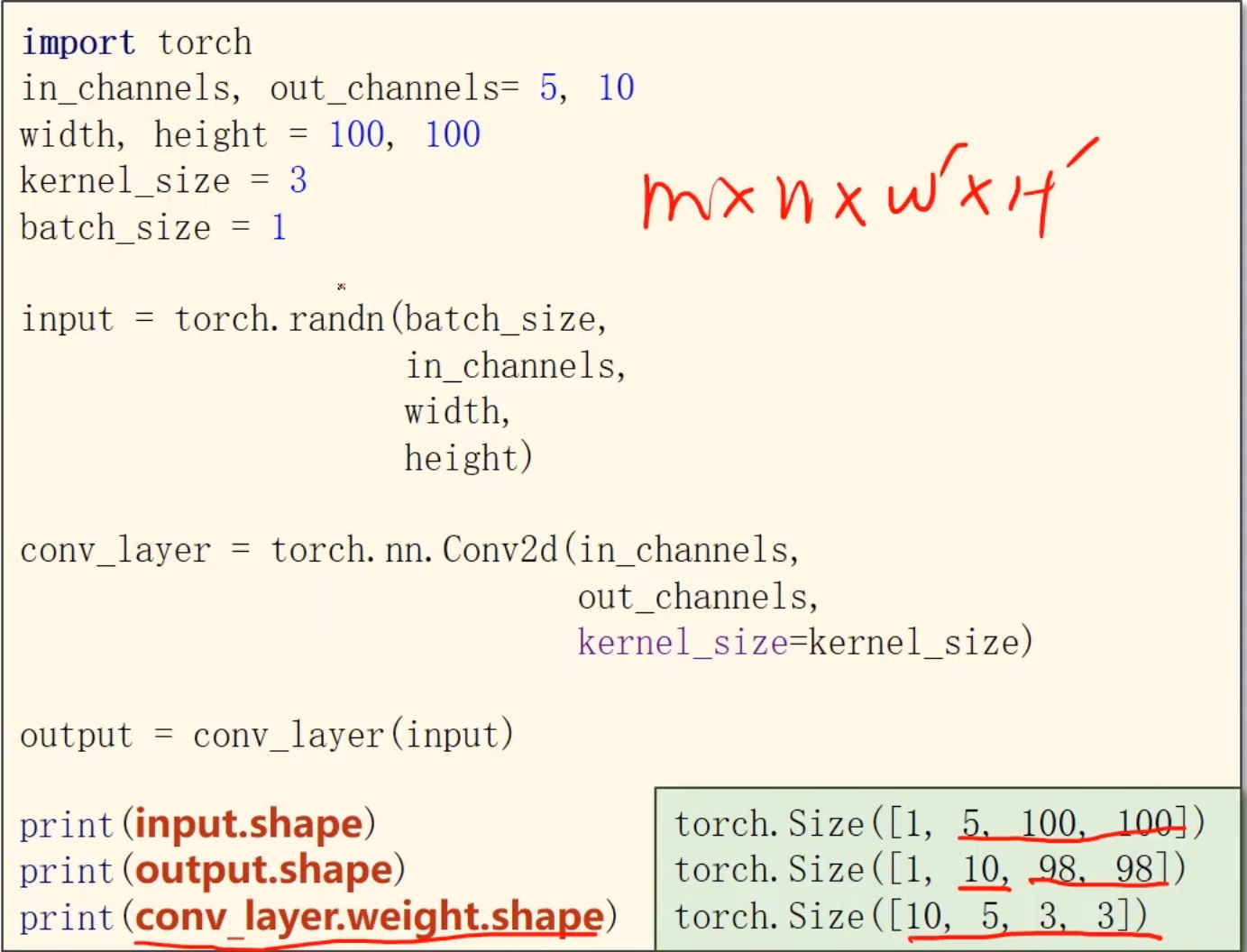
卷积神经
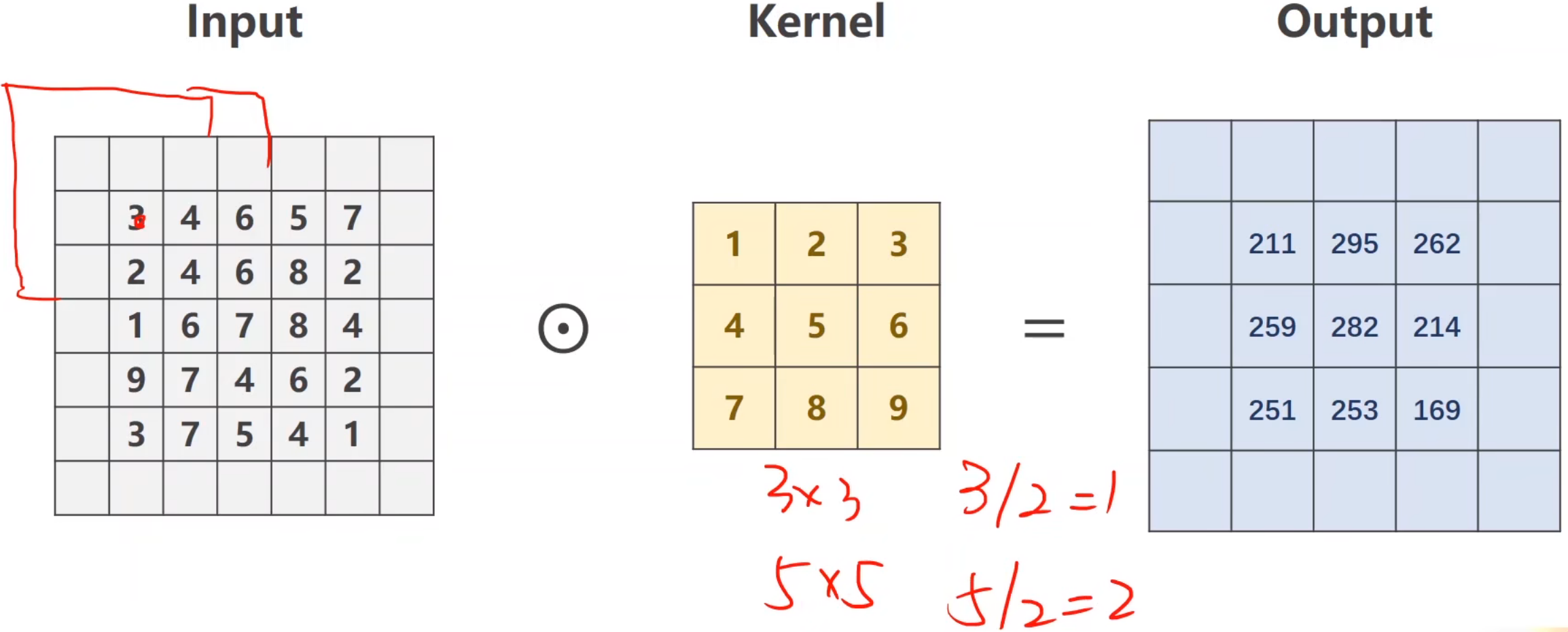
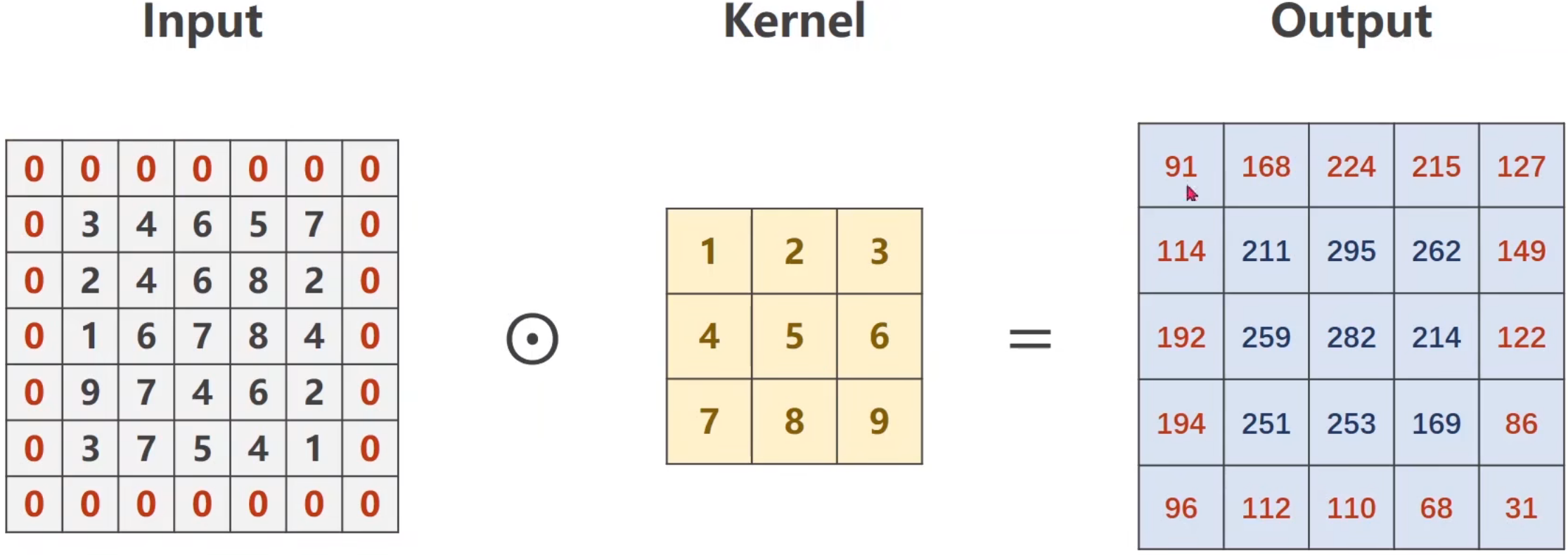

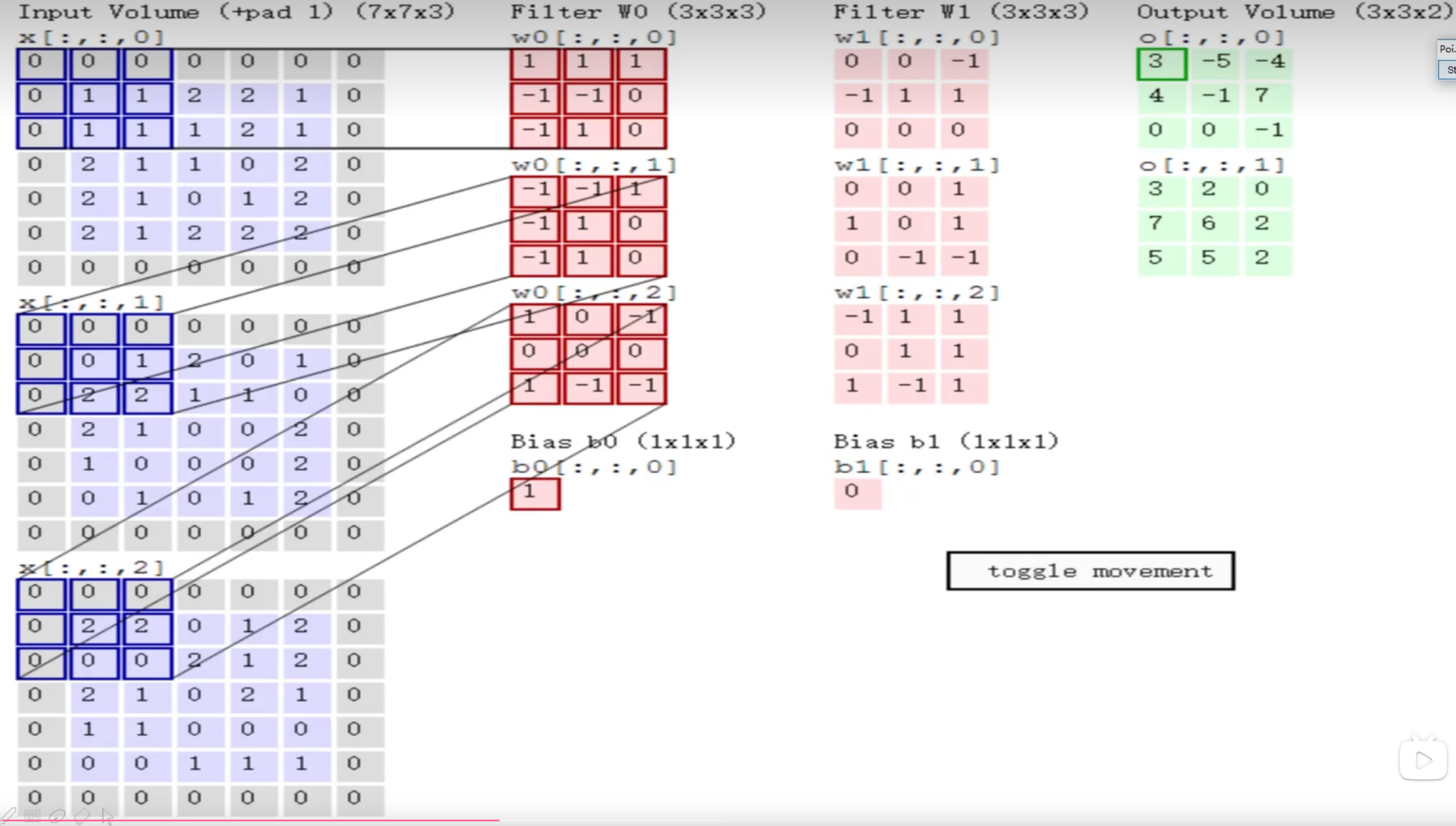

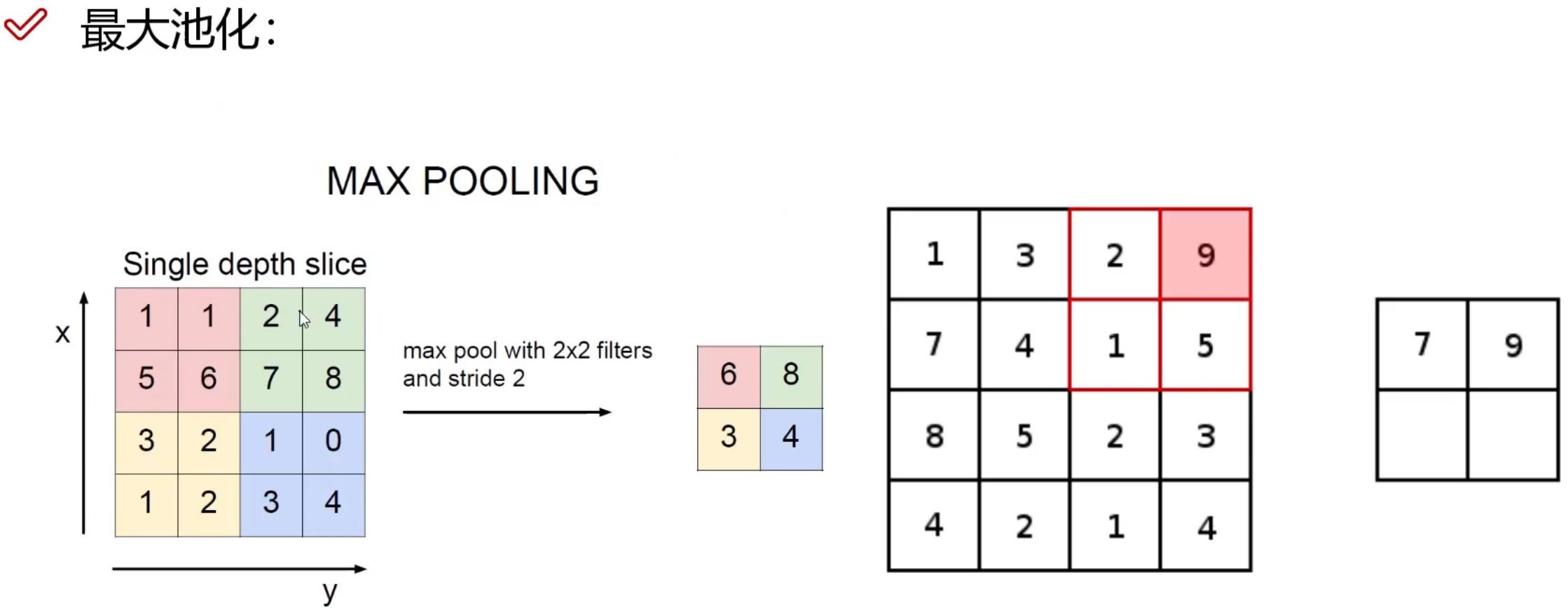
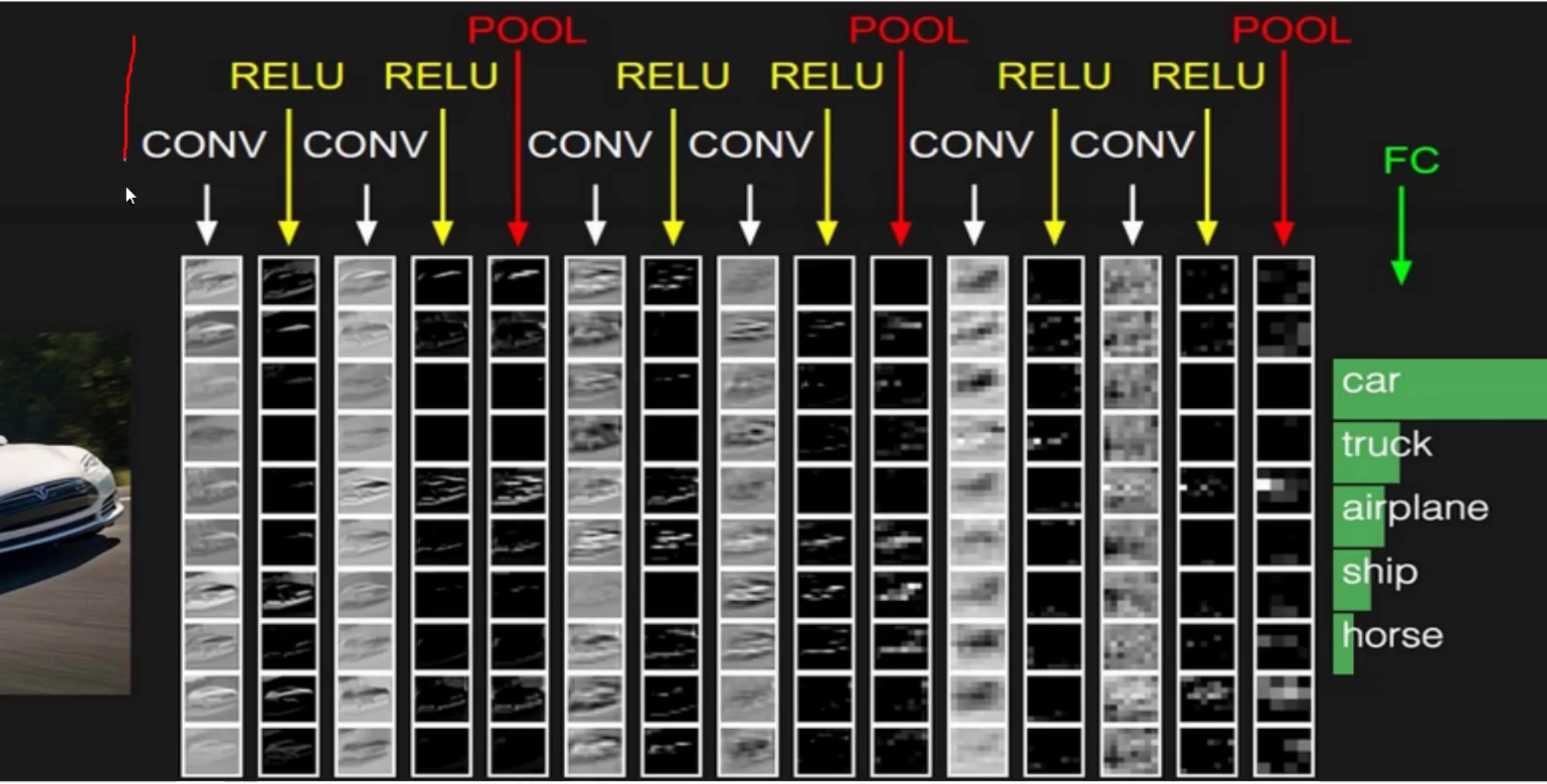
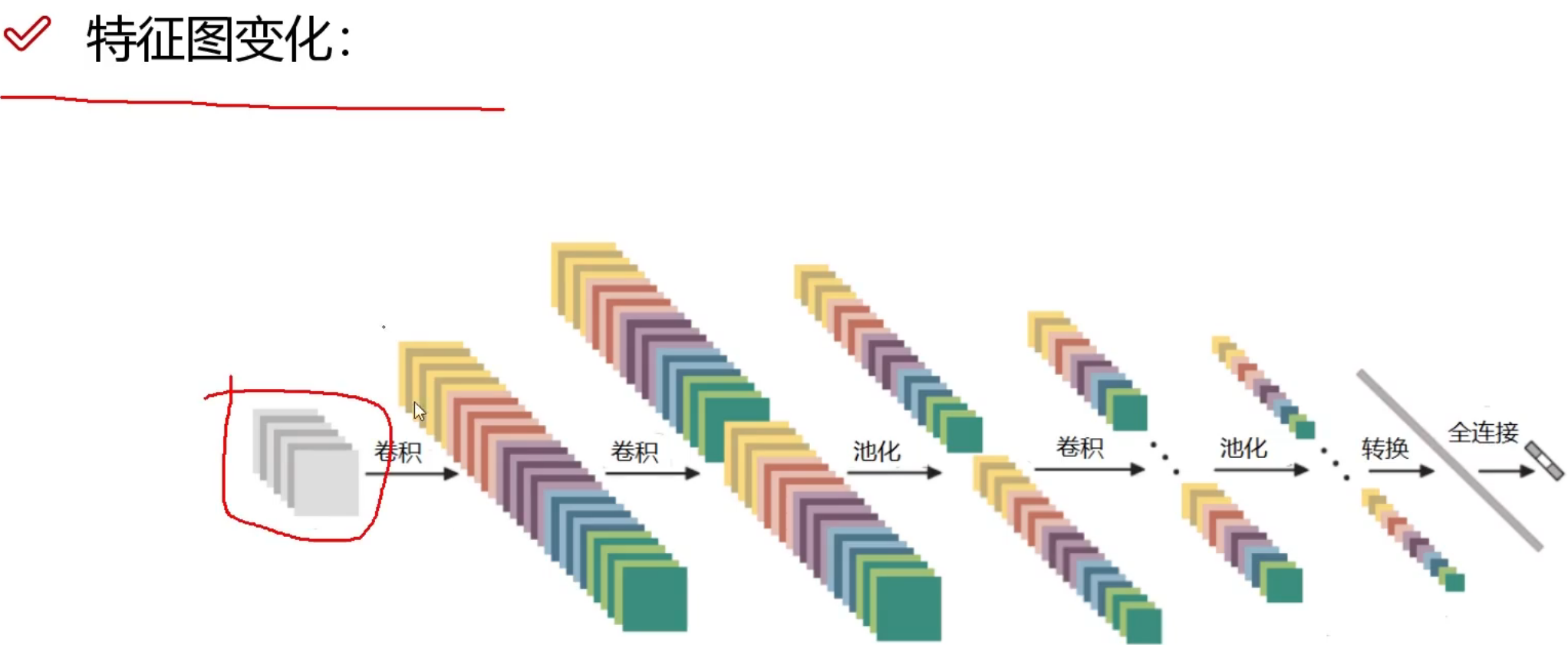
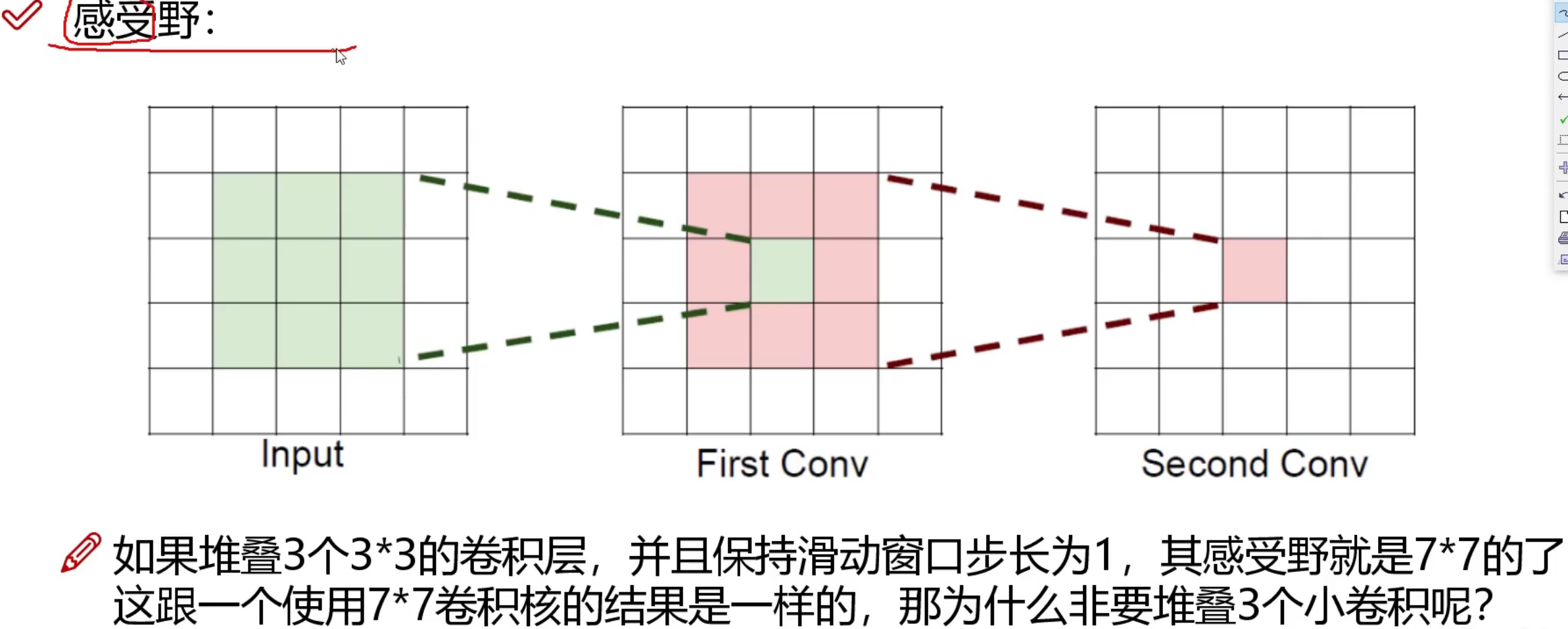



训练集怎么做的数据预处理, 验证集合也要怎么做
 可以在本地ip:6066端口查看学习进度
可以在本地ip:6066端口查看学习进度
写在最后,这是本人改写的一个模型 数据是pytorch的
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torch
# 定义训练设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 1、准备数据集
train_dataset = torchvision.datasets.CIFAR10("./data", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.CIFAR10("./data", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
train_dataset_size = len(train_dataset)
test_dataset_size = len(test_dataset)
print(train_dataset_size)
print(test_dataset_size)
# 2、加载数据集
train_dataset_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_dataset_loader = DataLoader(dataset=test_dataset, batch_size=64)
# 3、搭建神经网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=2),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, kernel_size=3, padding=2),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(64, 128, kernel_size=3, padding=2),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(128, 256, kernel_size=3, padding=2),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(256, 512, kernel_size=3, padding=2),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.fc_layers = nn.Sequential(
nn.Flatten(),
nn.Linear(512 * 2 * 2, 256),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(256, 10),
nn.Softmax(dim=1)
)
def forward(self, x):
x = self.model1(x)
x = self.fc_layers(x)
return x
# 创建网络模型
net = Net()
net = net.to(device)
# 5、设置损失函数、优化器
# 损失函数
loss_fun = nn.CrossEntropyLoss()
loss_fun = loss_fun.to(device)
# 优化器
learning_rate = 0.001
optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate)
# 6、设置网络训练中的一些参数
total_train_step = 0
total_test_step = 0
epoch = int(input("\n训练次数:"))
# 添加tensorboard
writer = SummaryWriter("./logs_self_train")
# 7、开始进行训练
for i in range(epoch):
print("---第{}轮训练开始---".format(i + 1))
net.train()
for data in train_dataset_loader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = net(imgs)
loss = loss_fun(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("---第{}次训练结束, Loss:{})".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 8、开始进行测试
net.eval()
with torch.no_grad():
total_test_loss = 0
correct = 0
total = 0
for batch_idx, (imgs, targets) in enumerate(test_dataset_loader):
imgs = imgs.to(device)
targets = targets.to(device)
outputs = net(imgs)
loss = loss_fun(outputs, targets)
total_test_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += (predicted == targets).sum().item()
accuracy = 100 * correct / total
print("第{}轮测试的总损失为:{}".format(i + 1, total_test_loss))
print("第{}轮测试的准确率为:{}%".format(i + 1, accuracy))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", accuracy, total_test_step)
total_test_step += 1
# 9、保存模型
torch.save(net, 'savemodel/save_path')
# torch.save(net.state_dict(), "./savemodel/self_model_{}.pth".format(i))
print("模型已保存")
模型(验证)
import torch
import torchvision
from PIL import Image
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
image_path = "./img/flying.jpg"
image = Image.open(image_path)
print(image)
image = image.convert('RGB')
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=2),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, kernel_size=3, padding=2),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(64, 128, kernel_size=3, padding=2),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(128, 256, kernel_size=3, padding=2),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(256, 512, kernel_size=3, padding=2),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.fc_layers = nn.Sequential(
nn.Flatten(),
nn.Linear(512 * 2 * 2, 256),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(256, 10)
)
def forward(self, x):
x = self.model1(x)
x = self.fc_layers(x)
return x
model = torch.load(r"D:\model\savemodel\save_path", map_location=torch.device('cpu'))
print(model)
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():
output = model(image)
result = str(output.argmax(1))
# 获取类别概率
probabilities = torch.softmax(output, dim=1)
print(probabilities)
# 获取预测的类别索引和对应的标签
predicted_class_index = torch.argmax(probabilities, dim=1).item() # 2
# 定义类别标签
class_labels = ['飞机', '汽车', '鸟', '猫', '鹿', '狗', '青蛙', '马', '轮船', '卡车']
# 打印预测的类别标签和概率
predicted_label = class_labels[predicted_class_index]
predicted_probability = probabilities[0][predicted_class_index].item()
predicted_probability = probabilities[0][predicted_class_index].item()
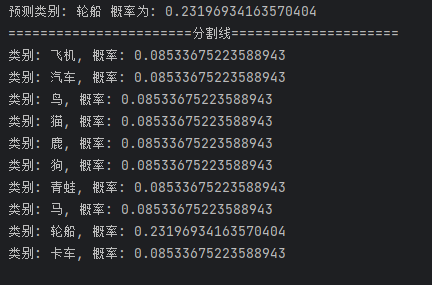
print("预测类别:", predicted_label, "概率为:", predicted_probability)
print("=======================分割线=====================")
# 打印预测的类别标签和概率
for i, prob in enumerate(probabilities[0]):
label = class_labels[i]
predicted_probability = prob.item()
print(f"类别: {label}, 概率: {predicted_probability}")模型精度
OpenCV + 深度学习
本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
评论交流
欢迎留下你的想法