



1. 微服务的概念
微服务(Microservices)是一种架构风格,它将应用程序拆分成一组小的、独立的、自治的服务,每个服务都实现一个特定的业务功能,并且通过轻量级的通信机制(通常是 HTTP 或消息队列)与其他服务进行交互。
每个微服务通常具有自己的数据存储、业务逻辑、以及应用程序生命周期,这使得每个服务可以独立部署、扩展和维护。微服务架构的核心理念是通过解耦,简化应用程序的开发、部署和运维。
关键特点:
自治:每个微服务是独立部署和管理的,可以自主选择技术栈。
聚焦单一功能:每个微服务实现一组特定的功能,通常围绕某个业务领域(如用户管理、支付处理等)构建。
分布式:各个微服务通过网络通信进行协作,可以运行在不同的服务器或容器中。
弹性和可扩展性:微服务允许每个服务独立扩展,提高系统的可伸缩性。
2. 为什么需要微服务
微服务架构的出现是为了解决传统单体应用架构在扩展、开发和维护方面的一些挑战。以下是一些微服务架构的重要优势:
解耦:传统的单体应用中,代码往往是紧密耦合的,任何一部分的改动都会影响整个系统。微服务通过将应用拆分为多个小服务,降低了不同模块之间的耦合度,简化了修改和更新过程。
技术异构性:每个微服务可以使用最适合该服务的技术栈(例如 Java、Python、Node.js),与其他服务的技术栈无关。这为技术选型提供了灵活性。
独立部署:微服务可以独立部署和更新,减少了全系统重新部署的频率。服务的独立性使得开发和运维更加高效。
高可用性和容错性:由于各个微服务是独立的,一个服务的失败不会导致整个系统崩溃。系统可以容忍部分服务的不可用,从而提高了系统的稳定性和可用性。
可扩展性:对于负载较高的业务,微服务可以单独扩展该服务,而无需扩展整个应用系统,节省了资源并提高了响应能力。
敏捷开发:由于微服务通常围绕业务功能划分,团队可以围绕某个业务功能进行开发和测试,实现快速迭代和敏捷开发。
适应 DevOps 和持续交付:微服务架构便于自动化部署和持续集成,支持 DevOps 实践,缩短开发周期。
3. 微服务的实现
微服务的实现涉及多个方面,包括服务拆分、服务间通信、数据管理、部署方式等。下面是实现微服务架构的常见步骤和技术:
(1) 服务拆分
首先,需要根据业务需求将单体应用拆分为多个小服务。拆分原则包括:
功能划分:根据不同的业务功能划分服务,例如订单服务、支付服务、用户管理服务等。
领域驱动设计(DDD):通过领域驱动设计,按照业务领域模型来划分微服务。
团队能力:可以考虑根据团队结构来拆分服务,每个团队负责一个或多个微服务。
(2) 服务间通信
微服务之间需要通过网络通信进行数据交换。常见的通信方式包括:
RESTful API:基于 HTTP 协议的标准通信方式,使用 JSON 格式传输数据,简洁、易用,是最常见的方式。
gRPC:一种高效的开源 RPC 框架,通常用于高性能的微服务通信。
消息队列:如 Kafka、RabbitMQ 等消息中间件,通过异步的消息传递解耦服务间的调用。
GraphQL:通过查询语言来获得复杂的业务数据,适用于多种微服务聚合数据的场景。
(3) 数据管理
在微服务架构中,每个服务通常都有自己的数据库,避免多个服务共用一个数据库。常见的数据管理方式包括:
数据库分片:每个微服务持有独立的数据库或表,避免跨服务的数据库访问。
事件驱动架构:使用事件总线来传递业务事件,实现跨服务的数据同步。
(4) 服务发现
在微服务架构中,服务实例通常是动态变化的(例如,在容器中部署时)。为了使服务能够找到彼此,服务发现机制显得至关重要。常见的服务发现工具有:
Consul:支持服务注册和发现、健康检查、负载均衡等。
Eureka:Netflix 开源的服务发现框架。
Zookeeper:主要用于分布式协调,也可以作为服务发现的工具。
(5) 负载均衡与容错
微服务架构中的负载均衡和容错机制能够确保系统的稳定性和高可用性:
负载均衡:服务请求可以通过负载均衡器分发到不同的微服务实例,如 Nginx、HAProxy、Kubernetes 内置的负载均衡。
熔断机制:例如,Netflix 提供的 Hystrix,可以在服务无法访问时快速失败,避免对整个系统的影响。
(6) 监控和日志管理
微服务的分布式特性意味着你需要集中式的监控和日志管理:
集中式日志系统:例如 ELK(Elasticsearch、Logstash、Kibana)栈,或者是使用 Prometheus 和 Grafana 进行实时监控和数据可视化。
分布式追踪:工具如 Jaeger 或 Zipkin,帮助跟踪请求跨服务的流动路径,分析性能瓶颈。
(7) 部署与容器化
微服务架构最常与容器技术(如 Docker)配合使用,容器化有助于独立部署和隔离微服务的运行环境。常见的容器编排工具有:
Kubernetes:强大的容器编排工具,用于自动化部署、扩展和管理微服务。
Docker Compose:用于定义和运行多容器的应用。
(8) API Gateway
API Gateway 是微服务架构中的一个关键组件,用于处理所有外部请求并将其路由到适当的微服务。API Gateway 还可以处理认证、负载均衡、速率限制等功能。
4. 微服务架构的挑战
尽管微服务带来许多优势,但也面临一些挑战:
复杂性:微服务系统的架构和部署比传统的单体应用更为复杂,需要解决分布式系统的各种问题(如一致性、事务管理等)。
数据一致性:在分布式系统中,保持数据一致性和处理分布式事务是一项技术挑战,通常采用事件驱动和最终一致性方案。
服务间通信开销:微服务之间的通信需要通过网络,可能带来额外的延迟和带宽消耗。
运维复杂性:微服务的部署和监控需要更加精细的管理和自动化工具。
总结
微服务架构通过将应用程序拆分成一组小的、自治的服务,使得开发、测试、部署和运维更为灵活、高效。它适用于大规模的、需要高可扩展性的系统,但也带来了更高的复杂性,需要仔细设计和管理。通过合适的工具和技术,微服务架构可以帮助企业应对快速变化的业务需求和技术环境。
架构的分类
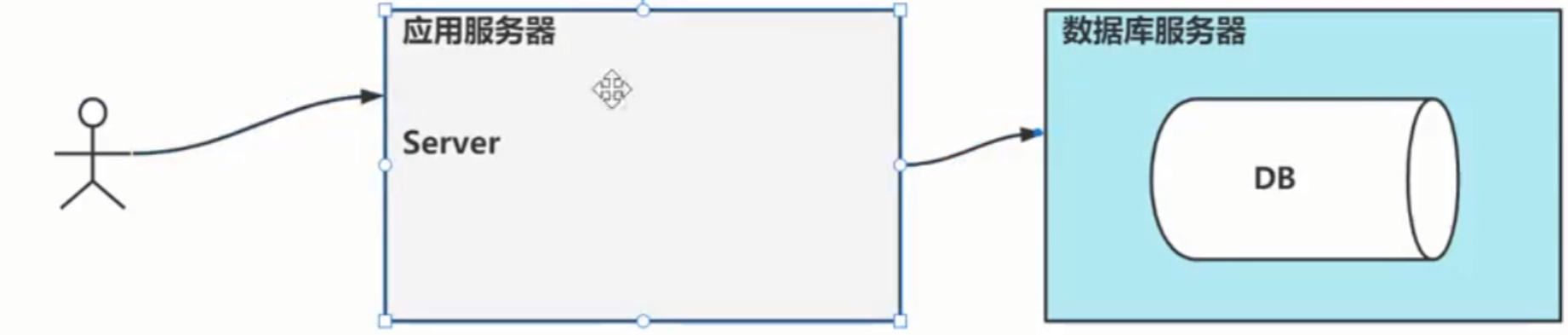
1).单体架构
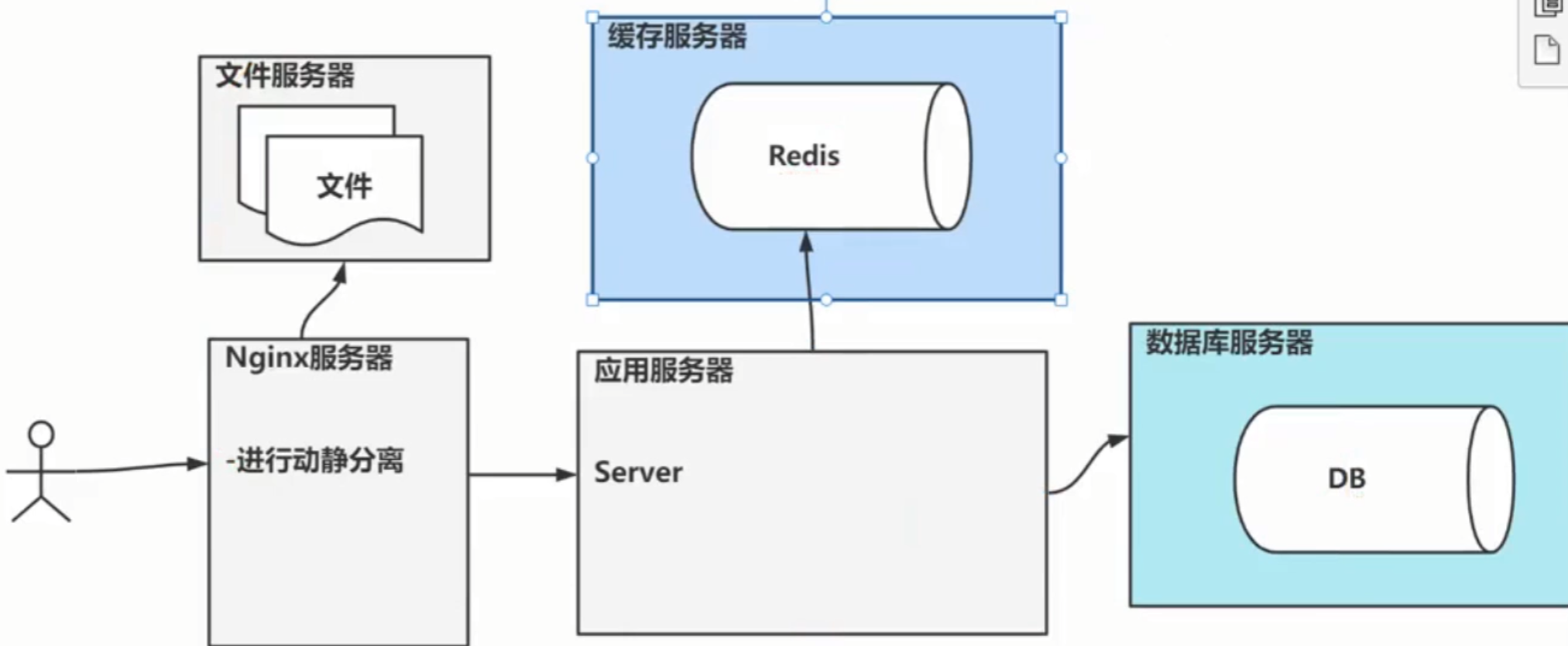
2).动静分离架构
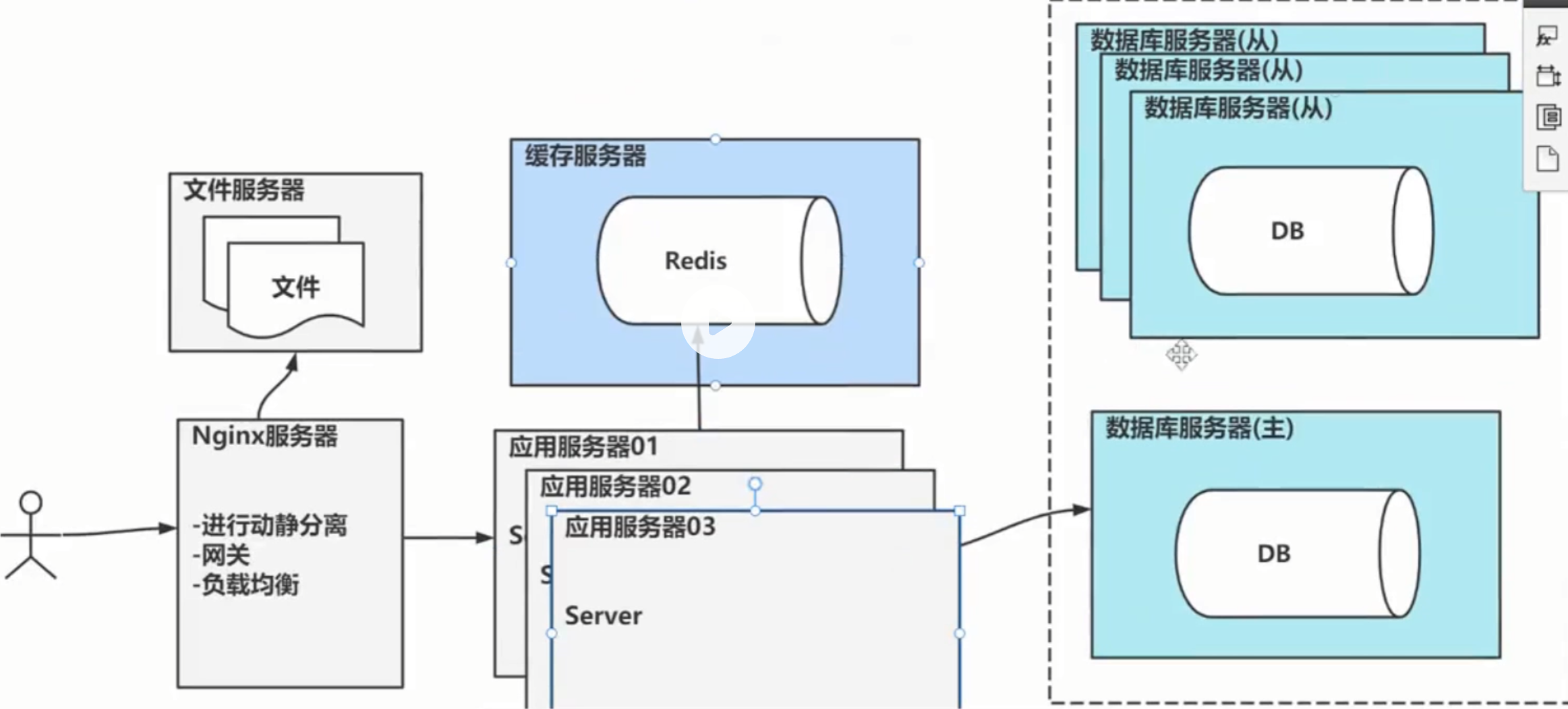
3).分布式架构 (业务拆分+ 负载均衡)
4) springcloud
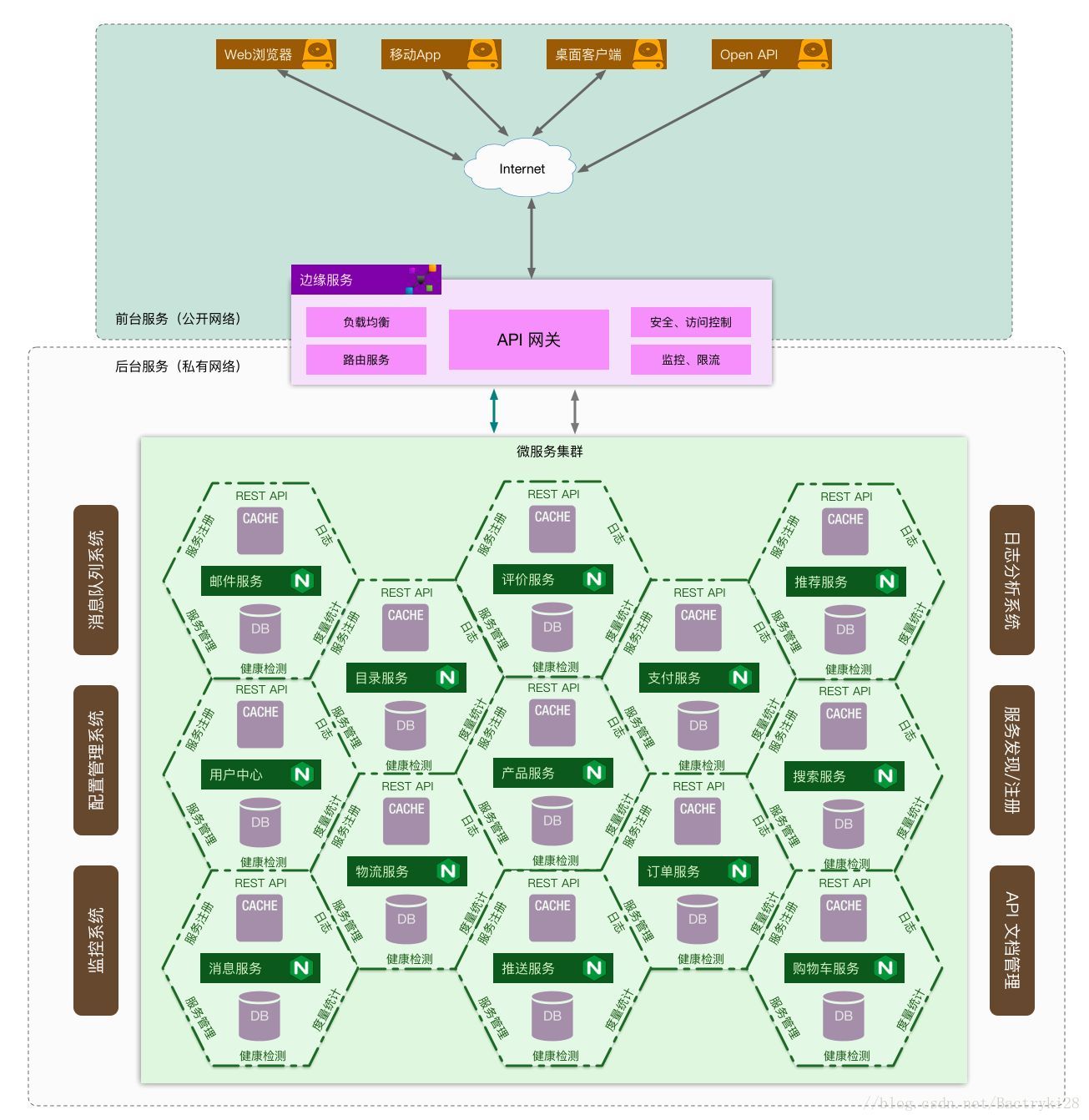
1."微服务"一词源于Martin Fowler 的名为 Microservices 的博文,简单地说, 微服务是系统架构上的一种设计风格,它的主旨是将一个原本独立的系统拆分成多个小型服务,这些小型服务都在各自独立的进程中运行,服务之间通过基于HTTP的RESTfuIAPI进行通信协作。
2.被拆分成的每一个小型服务都围绕着系统中的某一项或一些耦合度较高的业务功能进行构建,并且每个服务都维护着自身的数据存储、业务开发、自动化测试案例以及独立部署机制。 由于有轻量级的通信协作基础,所以这些微服务可以使用不同的语言来编写
SpringCloud 全面说明
1.SpringCloud来源于 Spring,是更高层次的架构视角的综合性大型项目,目标旨在构建一套标准化的微服务解决方案,让架构师在使用微服务理念构建系统的时,面对各环节的问题都可以找到相应的组件来处理
2.Spring Cloud 是 Spring 社区为微服务架构提供的一个"全家桶"套餐。套餐中各个组件之间的配合,可以减少在组件的选型和整合上花费的精力可以快速构建起基础的微服务架构系统,是微服务架构的最佳落地方案
3.spirng Cloud 天然支持 Spring Boot(有版本对应要求),使用门槛较低
4.解决与分布式系统相关的复杂性-网络问题,迟开销,带宽问题,安全问题
5.处理服务发现的能力一服务发现允许集群中的程和服务找到彼此并进行通信中
6.解决几余问题-几余问题经常发生在分布式系乡
7.解决负载平衡-改进跨多个计算资源(例如计机集群,网络链接,中央处理单元)的工作负载分布
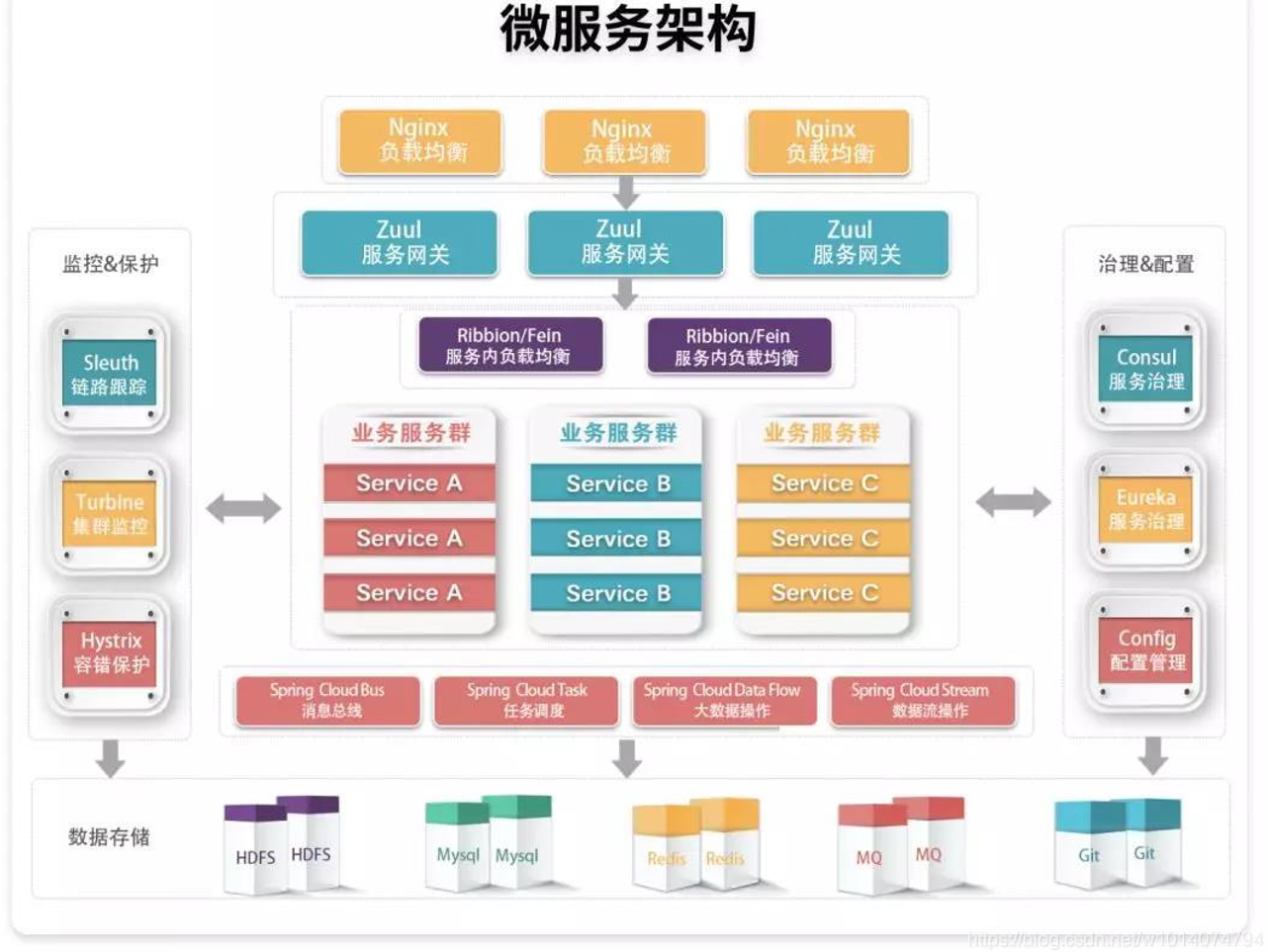
SpringCloud 核心组件

https://spring.io/projects/spring-cloud 文档
中文文档
alibaba/blob/2023.x/README-zh.md
NetFlix
分布示意图
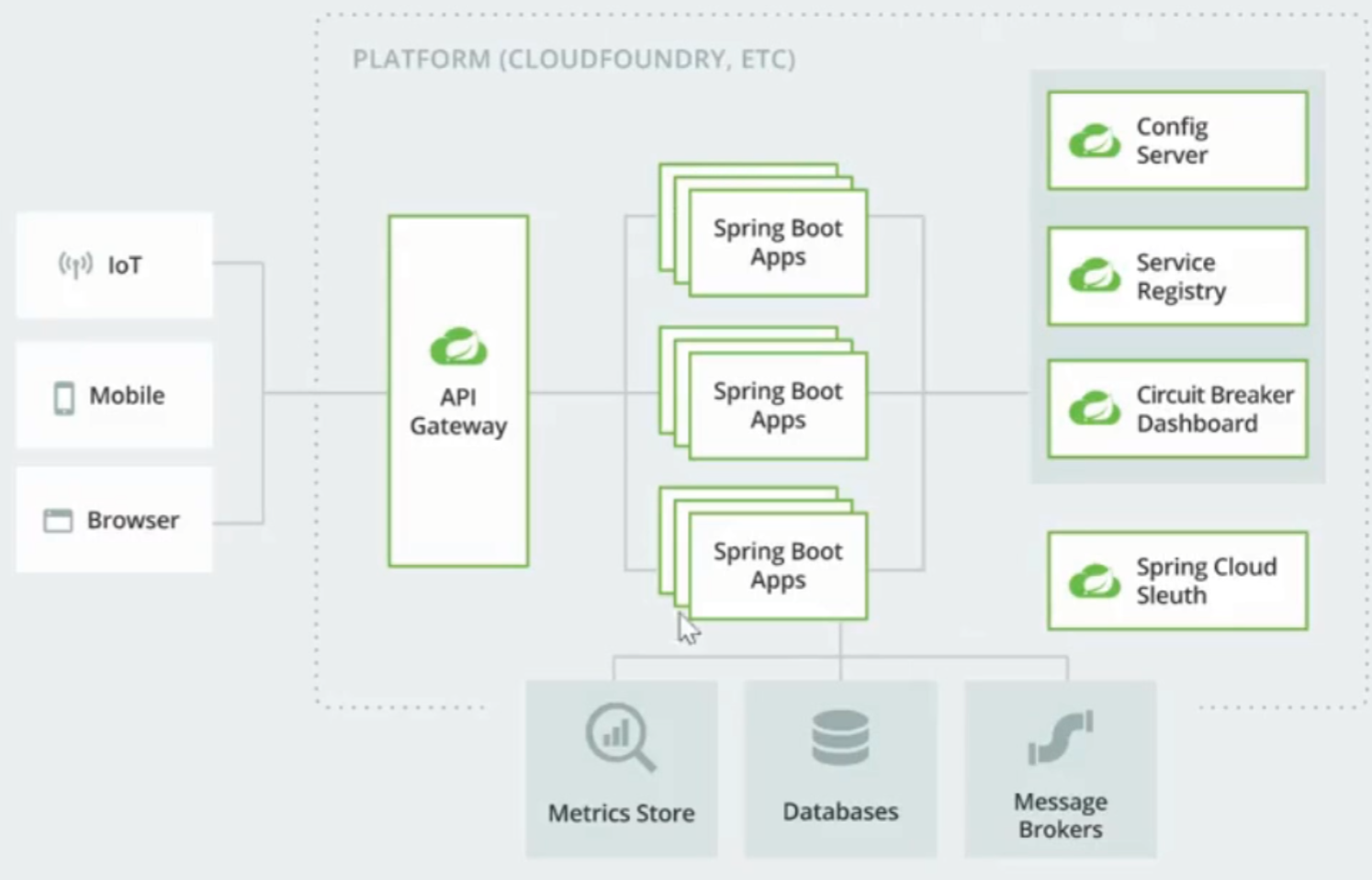
1.Spring Cloud 是微服务的落地
2.Spring Cloud 体现了微服务的弹性设计
3.微服务的工作方式一般是基于分布式的.
4.Spring Cloud 仍然是Spring 家族一员,可以解决微服务的分布式工作方式带来的各种问题
5.Spring Coud 提供很多组件,比如 服务发现,负载均衡,链路中断,分布式追踪和监控,甚至提供API gateway 功能.
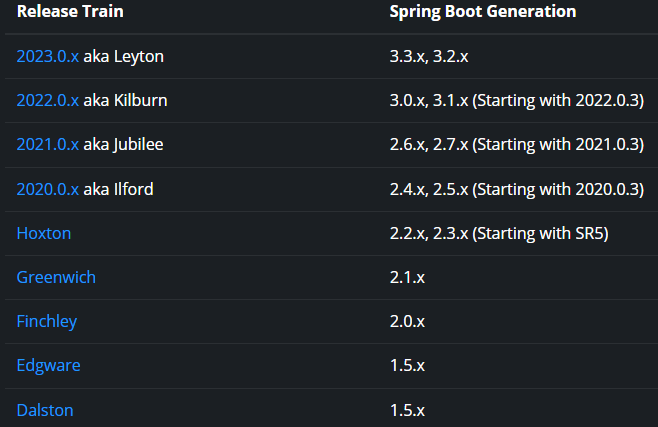
版本对应图
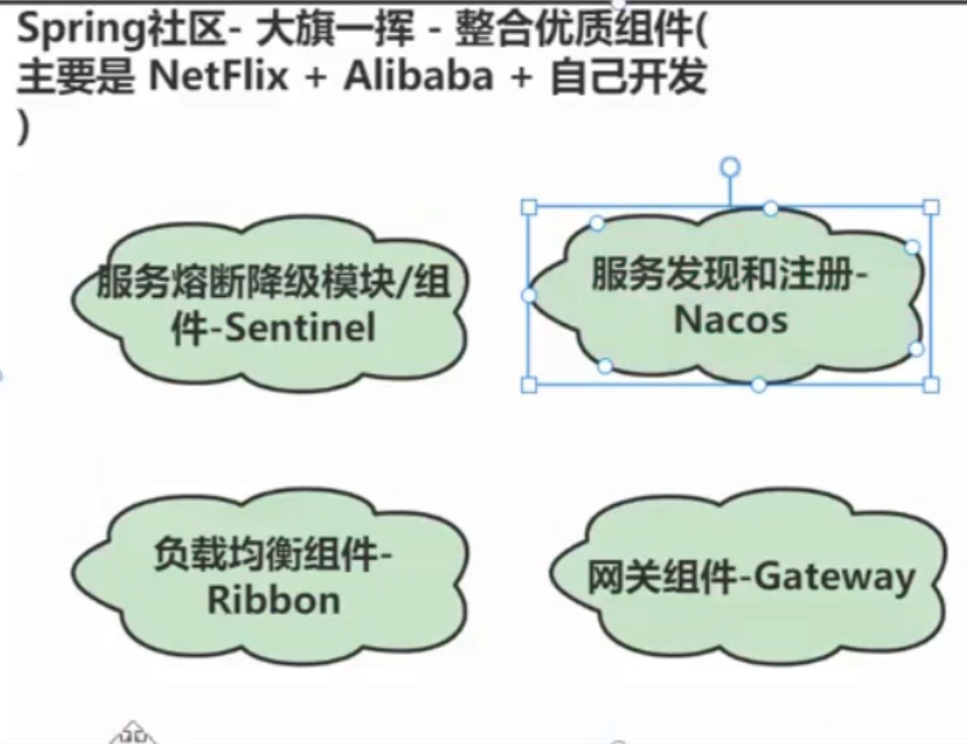
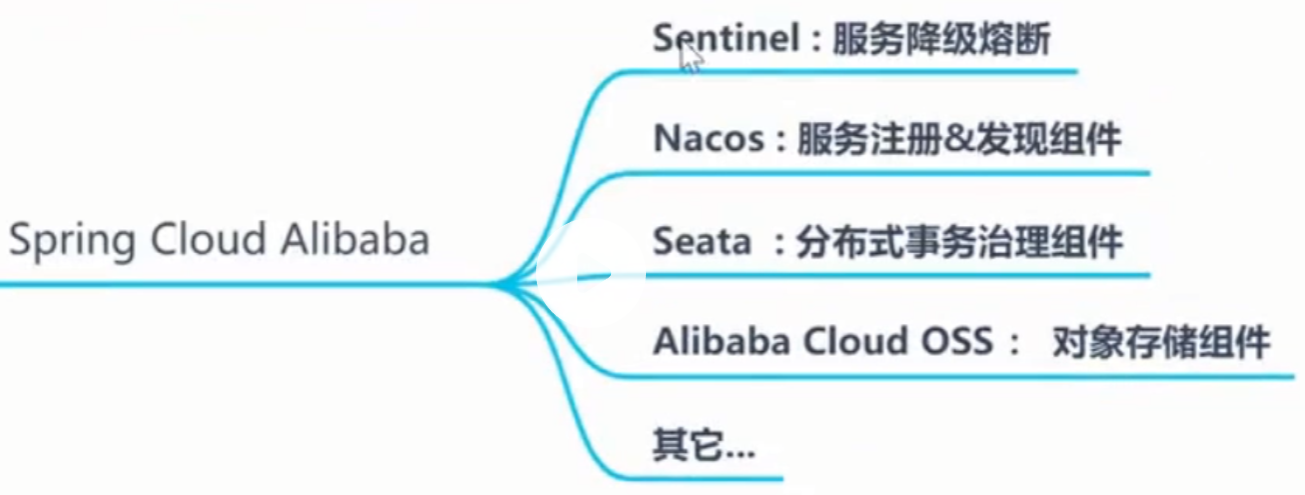
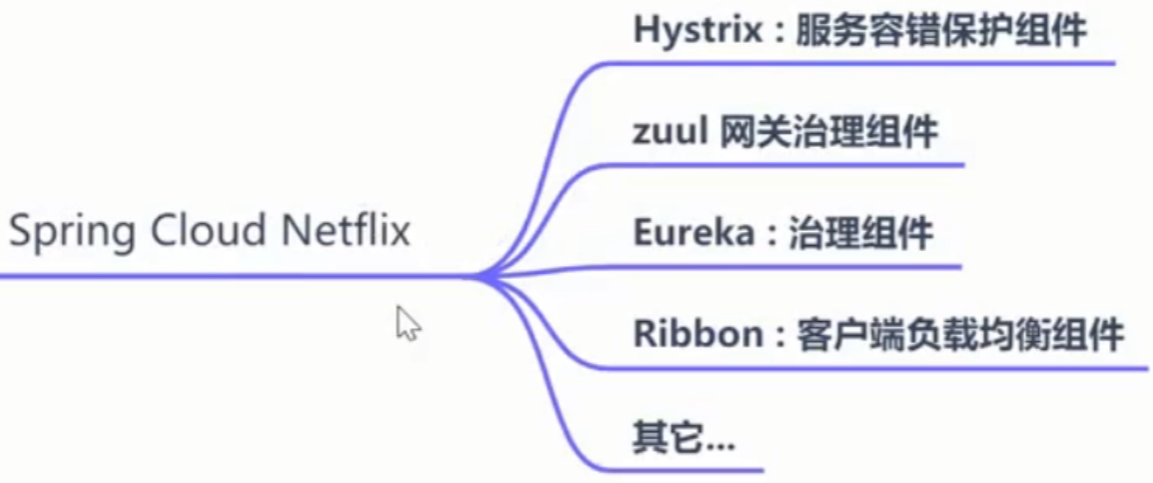
springCloud组件选型
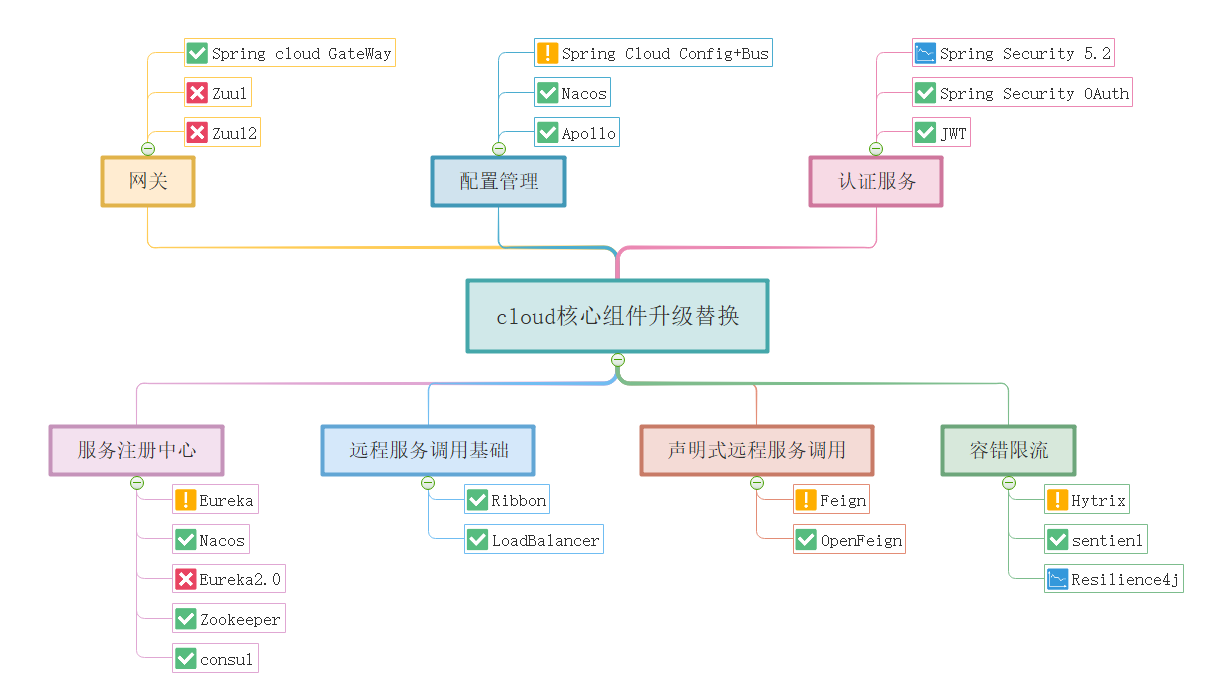
组件
Sentinel:把流量作为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
Nacos:一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
RocketMQ:一款开源的分布式消息系统,基于高可用分布式集群技术,提供低延时的、高可靠的消息发布与订阅服务。
Seata:阿里巴巴开源产品,一个易于使用的高性能微服务分布式事务解决方案。
Alibaba Cloud OSS: 阿里云对象存储服务(Object Storage Service,简称 OSS),是阿里云提供的海量、安全、低成本、高可靠的云存储服务。您可以在任何应用、任何时间、任何地点存储和访问任意类型的数据。
Alibaba Cloud SchedulerX: 阿里中间件团队开发的一款分布式任务调度产品,提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。
Alibaba Cloud SMS: 覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道。
RestTemplate
1、RestTemplate是Spring提供的用于访问Rest服务的模板类[JdbcTemplate]
2、RestTemplate提供了多种便捷访问远程Http服务的方法I
3、说明:可以这样理解,通过RestTemplate,我们可以发出http请求(支持Restful风格),去调用Controler提供的API接口,就像我们使用浏览器发出http请求,调用该API接口一样。
4、使用简单便捷
package com.zfc.springCloud.controller;
import com.zfc.springCloud.entity.Member;
import com.zfc.springCloud.entity.Result;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.client.RestTemplate;
import javax.annotation.Resource;
/**
* @author zfc
* @version 1.0
*/
@RestController
@Slf4j
public class MemberConsumerController {
@Resource
private RestTemplate restTemplate;
public static final String MEMBER_SERVICE_URL = "http://localhost:9999";
@PostMapping("/member/consumer/save")
public Result<Member> save(Member member) {
log.info("save member:{}", member);
return restTemplate.postForObject(MEMBER_SERVICE_URL + "/member/save", member, Result.class);
}
@GetMapping("/member/consumer/get/{id}")
public Result<Member> getConsumerById(@PathVariable Long id) {
log.info("get member id:{}", id);
return restTemplate.getForObject(MEMBER_SERVICE_URL + "/member/get/" + id, Result.class);
}
}
启动 Run Dashboard
<component name="RunDashboard">
<option name="configurationTypes">
<set>
<option value="SpringBootApplicationConfigurationType" />
</set>
</option>
<option name="ruleStates">
<list>
<RuleState>
<option name="name" value="ConfigurationTypeDashboardGroupingRule" />
</RuleState>
<RuleState>
<option name="name" value="StatusDashboardGroupingRule" />
</RuleState>
</list>
</option>
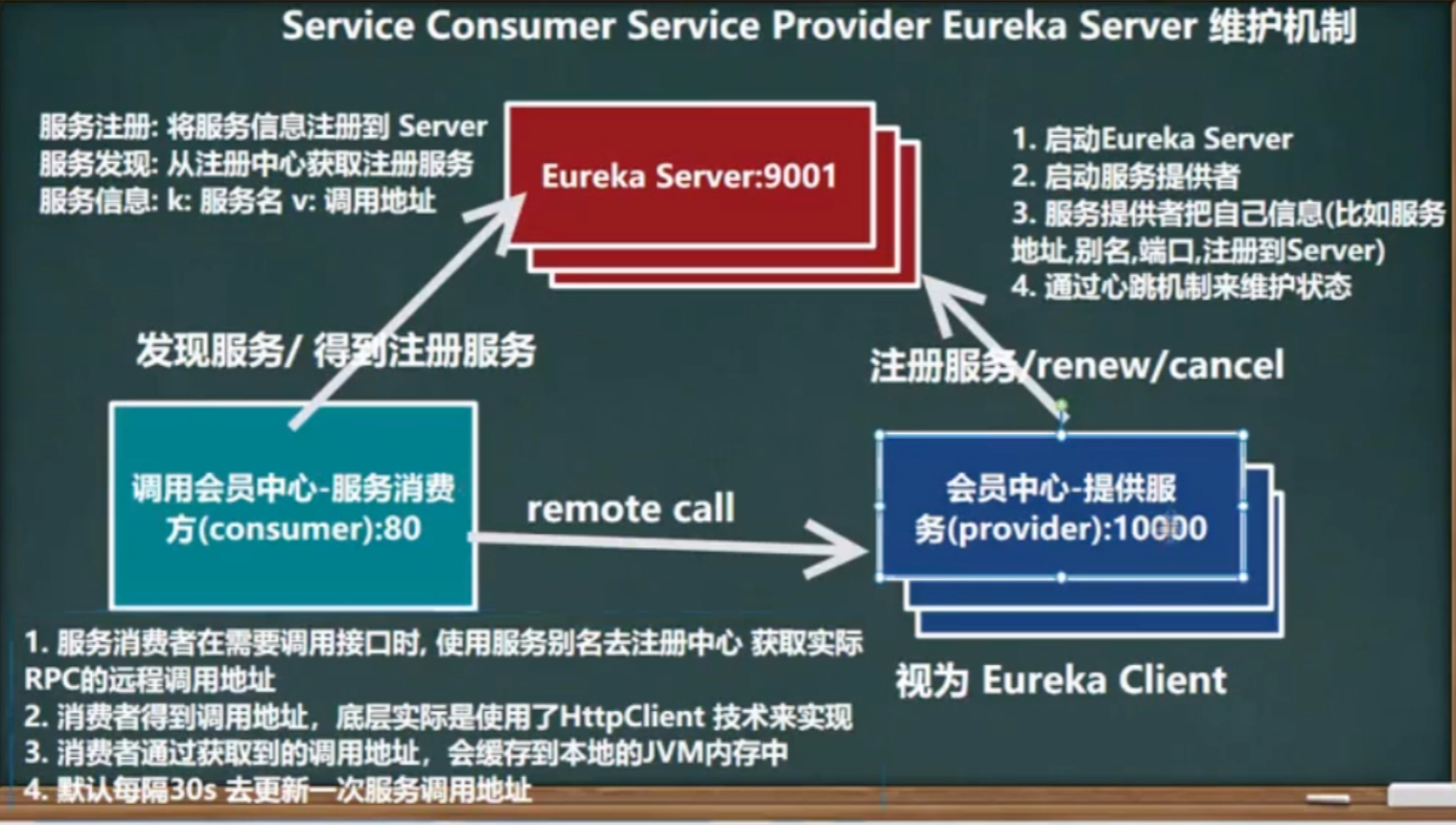
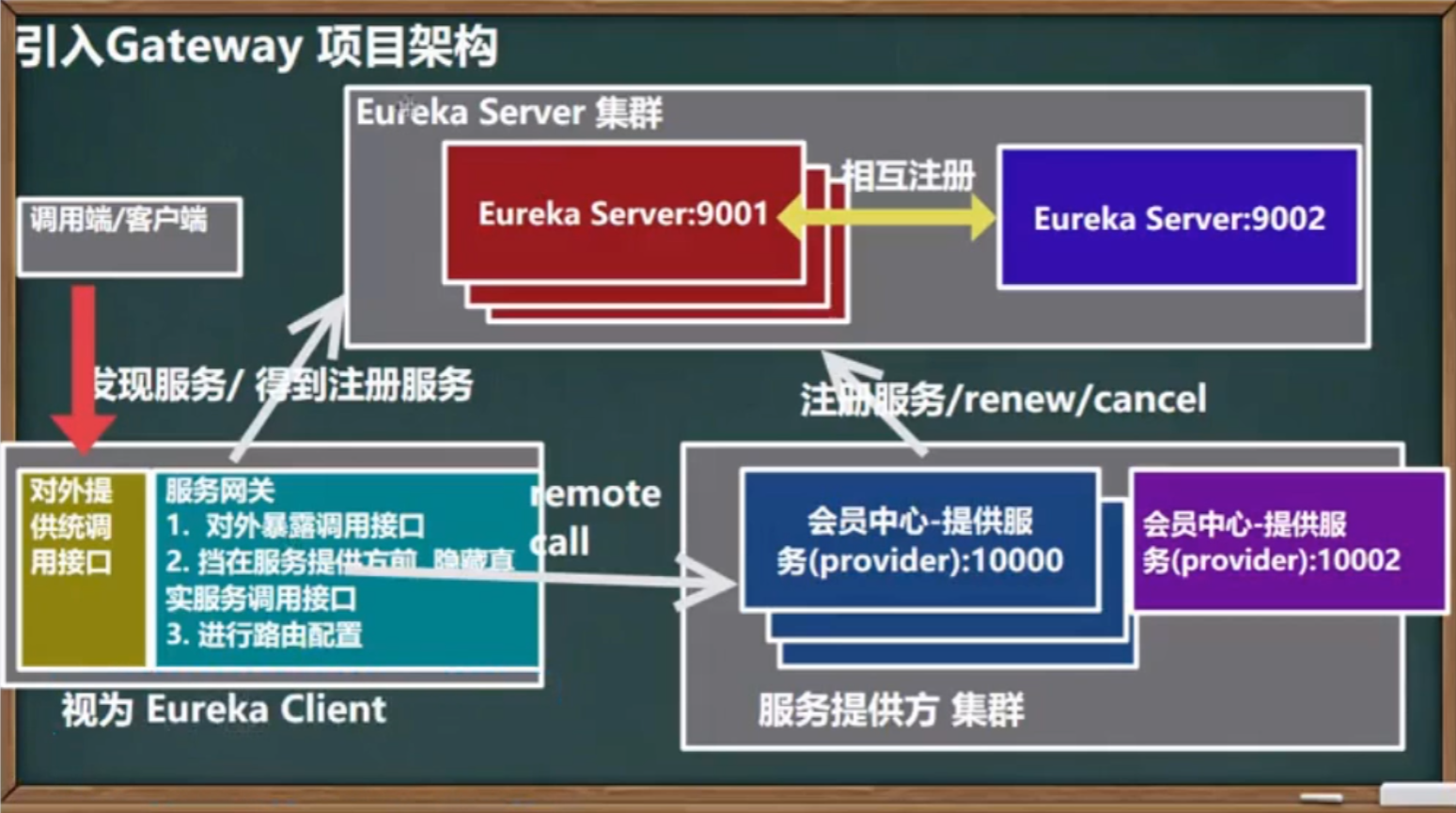
</component>Eureka(服务注册与发现)
在微服务架构中,服务注册(Service Registration)是一种机制,用于让微服务在启动时将自己的信息(如地址、端口、健康状态等)注册到一个服务注册中心(Service Registry),这样其他服务就可以通过这个中心来发现并访问它。
为了更通俗地理解,我们可以把服务注册想象成一个“电话簿”或“通讯录”。每个微服务就像是这个电话簿中的一个条目,在电话簿里列出了它的名字、地址(IP 和端口)以及它是否正常工作。其他微服务在需要与它通信时,就可以从这个电话簿中查找到它的具体信息,进而通过网络访问它。
具体过程:
服务启动时注册: 当一个微服务启动时,它会向服务注册中心报告自己的存在,注册自己的信息(比如服务名、IP 地址、端口号、健康状态等)。这就相当于服务自我“登记”到注册中心。
服务发现: 当其他微服务需要调用这个服务时,它们会向服务注册中心请求查找某个特定的服务。服务注册中心会返回该服务的地址和端口等信息,消费方服务就可以通过这些信息与提供方服务进行通信。
健康检查与注销: 服务注册中心通常会定期检查已注册服务的健康状况(健康检查)。如果某个服务宕机或不健康,注册中心会将其从注册列表中移除,以防止其他服务尝试访问不可用的服务。当服务停止或崩溃时,它也会从服务注册中心注销自己,确保注册表的准确性。
为什么需要服务注册?
动态化的服务发现: 在微服务架构中,服务是动态的,可能会随着时间的推移启动、停止或重新部署。服务的IP地址和端口也可能发生变化(特别是在容器化和云环境中)。服务注册可以帮助其他服务动态发现并访问到正确的服务,而不需要依赖固定的地址。
去中心化的服务调用: 微服务通常是分布式的,服务间的调用不可能是硬编码的(比如通过固定的IP地址)。通过服务注册和发现机制,服务可以动态地找到其他服务,不需要事先知道它们的确切位置。
容错和负载均衡: 服务注册中心通常会支持负载均衡和故障转移。消费方服务可以从注册中心获取多个提供方实例的信息,并进行负载均衡选择(比如轮询、随机等)。当某个服务实例不可用时,消费方可以自动切换到另一个健康的实例。
常见的服务注册工具:
Eureka:Netflix 开源的服务注册和发现工具,通常用于 Spring Cloud 微服务架构。
Consul:由 HashiCorp 开发的工具,提供服务注册、健康检查、分布式配置等功能。
Zookeeper:Apache 的一个分布式协调工具,可以用于服务注册和发现。
Etcd:一个分布式的键值存储系统,也可以用于服务注册和发现。
总结
服务注册是微服务架构中的一种关键机制,它让服务能够在启动时注册自己,并让其他服务能够通过注册中心发现并访问它们。通过这种方式,微服务可以动态地发现彼此,并进行灵活的调用,从而支持系统的弹性扩展、负载均衡和容错处理。
配置Eureka
server端
<dependencies>
<!--引入Eureka Server依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--用于springboot的监控系统-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<scope>provided</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>com.zfc</groupId>
<artifactId>commerce_center-common-api</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>client端
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>server:
port: 9001
#配置Eureka
eureka:
instance:
hostname: localhost
client:
# 不向注册中心注册自己
registerWithEureka: false
# 表示自己就是注册中心, 不需要去检索服务
fetchRegistry: false
serviceUrl:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/Eureka的自动维护机制
Eureka 自我保护机制

负载均衡注解
@Configuration
public class CustomizationBean {
@Bean
@LoadBalanced // 轮询算法调用远程接口
public RestTemplate getRestTemplate() {
return new RestTemplate();
}
}@DiscoveryService 注解

1. 注册服务 (register)
这是将当前服务注册到服务发现中心,通常包括服务名称、IP 地址、端口和健康检查信息等。
示例:
discoveryService.register("my-service", "127.0.0.1", 8080)
2. 注销服务 (deregister)
用于在服务停止时,从服务发现系统中注销服务。
示例:
discoveryService.deregister("my-service", "127.0.0.1", 8080)
3. 查询服务 (getInstances)
查询指定名称的所有可用服务实例,返回的通常是服务实例的列表(包含服务的 IP 地址和端口等信息)。
示例:
discoveryService.getInstances("my-service")
4. 服务健康检查 (checkHealth)
用于检查某个服务实例的健康状态,确保其可用性。
示例:
discoveryService.checkHealth("my-service-instance-id")
5. 获取服务元数据 (getMetadata)
获取与服务实例相关的元数据(例如:版本号、环境、区域等)。
示例:
discoveryService.getMetadata("my-service-instance-id")
6. 通过服务名称查找服务 (getService)
通过服务名称查找服务的实例,返回服务的 IP 和端口等信息。
示例:
discoveryService.getService("my-service")
7. 获取所有服务列表 (getAllServices)
获取系统中所有已注册的服务列表,通常返回一个服务名称的集合。
示例:
discoveryService.getAllServices()
8. 订阅服务变更事件 (subscribe)
监听服务注册、注销等事件的变化,适用于实时更新服务发现信息。
示例:
discoveryService.subscribe("my-service", event -> { ... })
9. 服务查询缓存 (getCachedInstances)
获取缓存的服务实例列表,而不是从服务发现中心实时查询。适用于减少请求延迟。
示例:
discoveryService.getCachedInstances("my-service")
10. 更新服务实例 (updateInstance)
更新服务实例的相关信息,如健康状态或元数据等。
示例:
discoveryService.updateInstance("my-service-instance-id", newMetadata)
11. 获取实例信息 (getInstanceInfo)
获取单个服务实例的详细信息。
示例:
discoveryService.getInstanceInfo("my-service-instance-id")
12. 服务实例列表 (getInstancesByMetadata)
根据特定的元数据筛选服务实例,适用于多租户或多版本服务场景。
示例:
discoveryService.getInstancesByMetadata("my-service", "version=1.0")
Ribbon
1.Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端 负载均衡的工具。
2.Ribbon主要功能是提供客户端负载均衡算法和服务调用
3.Ribbon客户端组件提供一系列完善的配置项如连接超时,重试等,
4.Ribbon会基于某种规则(如简单轮询,随机连接等)去连接指定服务
5.程序员很容易使用Ribbon的负载均衡算法实现负载均衡
6.一句话:Ribbon:负载均衡+RestTemplate调用
LB分类

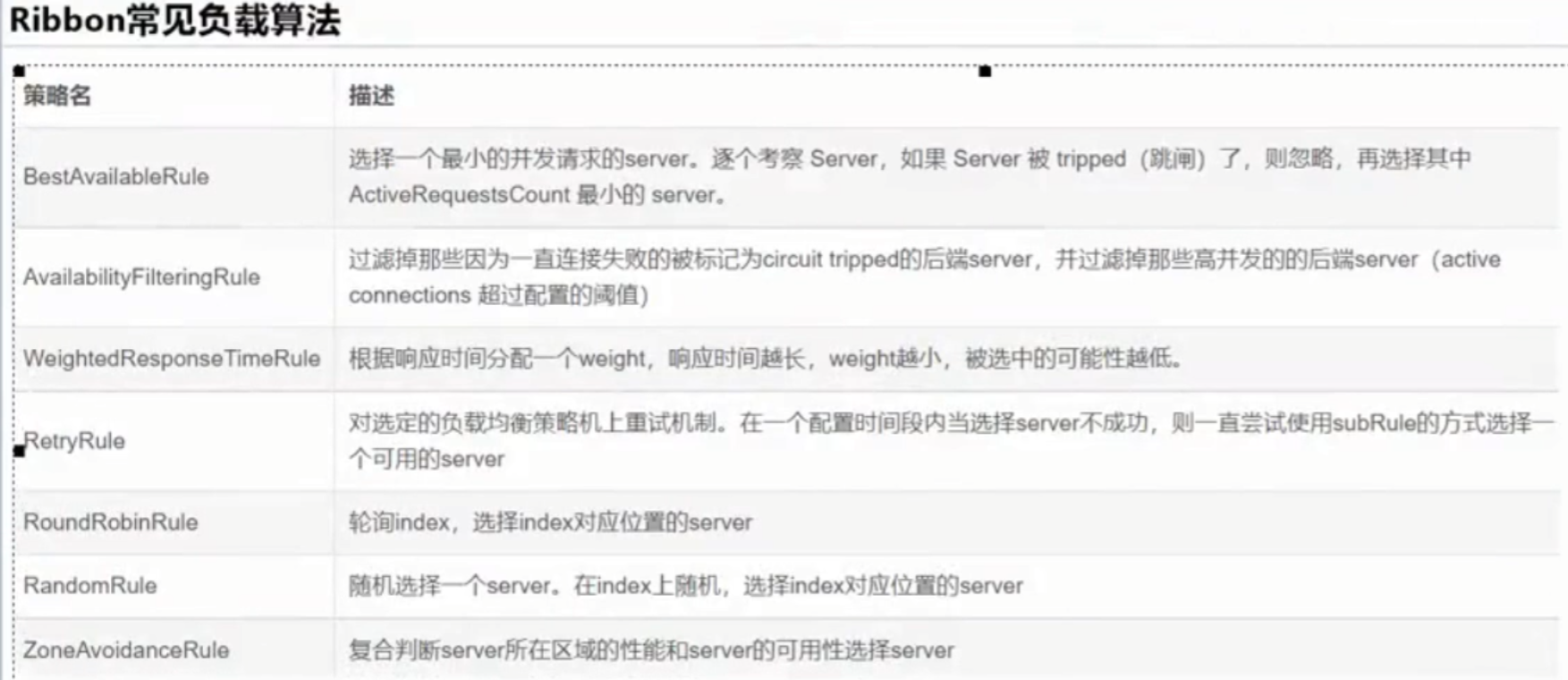
OpenFeign
1.OpenFeign是个声明式WebService客户端,使用OpenFeign让编写Web Service客户端更简单
2.它的使用方法是定义一个服务接口然后在上面添加注解
3.OpenFeign也支持可拔插式的编码器和解码器。
4.Spring Cloud对OpenFeign进行了封装使其支持了Spring MVC标准注解和HttpMessageConverters
5.OpenFeign可以与Eureka和Ribbon组合使用以支持负载均衡
package com.zfc.springcloud.service;
import com.zfc.springCloud.entity.Result;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.stereotype.Component;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
/**
* @author zfc
* @version 1.0
*/
@Component
@FeignClient(value = "MEMBER-SERVICE-PROVIDER")
public interface MemberFeignService {
@GetMapping("/member/get/{id}")
public Result getMemberById( @PathVariable("id") Long id);
}
OpenFeign 日志配置


logging:
level:
com.zfc.springcloud.service.MemberFeignService: debugconfig
@Configuration
public class OpenFeignConfig {
@Bean
public Logger.Level logLevel() {
return Logger.Level.FULL;
}
}OpenFeign 超时时间配置
ribbon:
# 建立连接从服务提供方获取可用资源的所用的全部时间
ReadTimeout: 8000
#两端连接所用时间
ConnectTimeout: 8000GeteWay
Gateway是在Spring生态系统之上构建的API网关服务,基于Spring,Spring Boot 和 Project Reactor等技术。
Gateway旨在提供一种简单而有效的方式来对API进行路由,以及提供一些强大的过滤器功能, 例如:熔断、限流、重试等
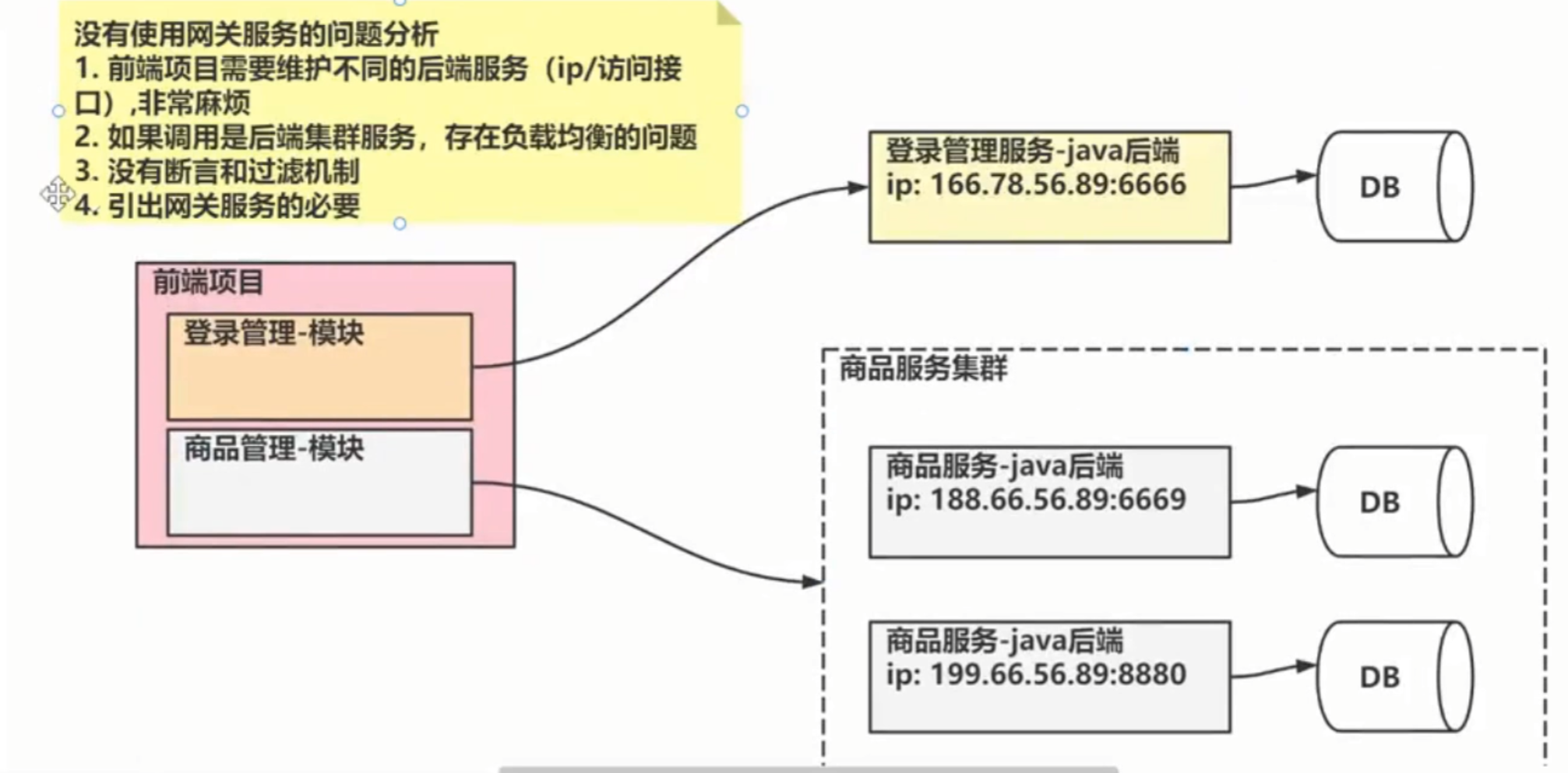
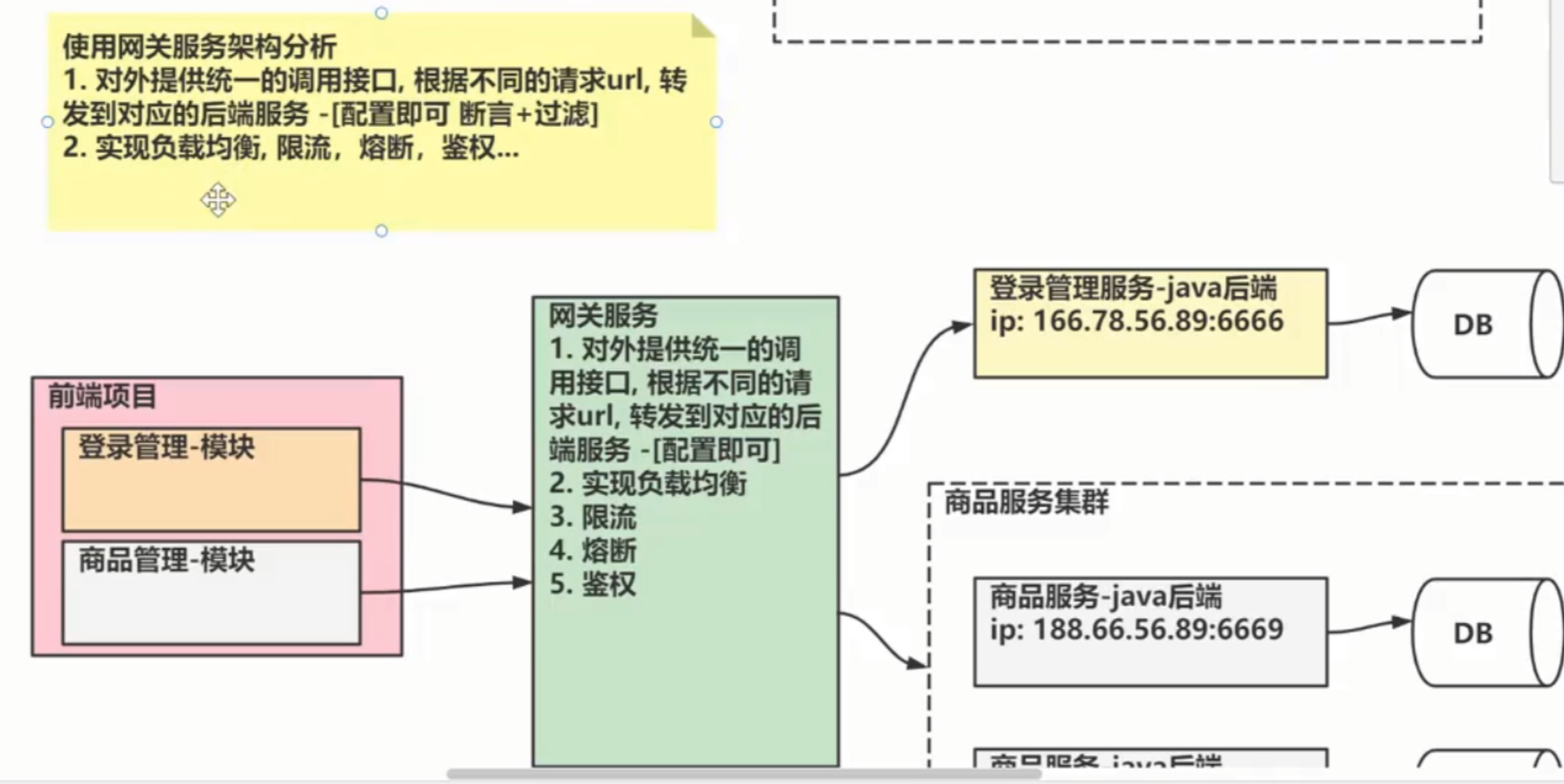
核心组件
1.Routing 路由
2. Predicate 断言
3.Filter 过滤
工作流程

注意!!!
不要引入
spring-boot-starter-web
spring-boot-starter-actuator
否则会出现冲突
因为gateway 是一个服务网关,不需要web...
<!--<dependency>-->
<!-- <groupId>org.springframework.boot</groupId>-->
<!-- <artifactId>spring-boot-starter-web</artifactId>-->
<!--</dependency>-->
<!--用于springboot的监控系统-->
<!--<dependency>-->
<!-- <groupId>org.springframework.boot</groupId>-->
<!-- <artifactId>spring-boot-starter-actuator</artifactId>-->
<!--</dependency>-->可通过config文件配置
@Configuration
public class GateWayRoutesConfig {
//配置注入路由
/**
* 在理解通过配置类注入/配置 路由,可以对照前面的application.yml来对比理解
* cloud:
* gateway:
* routes: #配置路由,可以配置多个路由 List<RouteDefinition> routes
* - id: member_route01 #路由的id, 程序员自己配置,要求唯一
* #gateway 最终访问的url 是 url=uri+Path
* #匹配后提供服务的路由地址: 也可以是外网 http://www.baidu.com
* #比如: 客户端/浏览器请求 url http://localhost:20000/member/get/1
* #如果根据Path匹配成功 最终访问的url/转发url 就是 url=http://localhost:10000/member/get/1
* #如果匹配失败, 则有gateway返回404信息
* #疑问: 这里老师配置的 uri 是固定,在当前这种情况其实可以没有有Eureka Server,后面老师会使用灵活方式
* # 配置,就会使用到Eureka Server
* uri: http://localhost:10000
* predicates: #断言,可以有多种形式
* - Path=/member/get/**
*/
@Bean
public RouteLocator myRouteLocator04(RouteLocatorBuilder routeLocatorBuilder) {
RouteLocatorBuilder.Builder routes = routeLocatorBuilder.routes();
//方法写完
//1. 下面的方法我们分别指定了id , uri 和path
//2. Function<PredicateSpec, Route.AsyncBuilder> fn
//(1) 是一个函数式接口
//(2) 接收的类型是 PredicateSpec ,返回的类型是 Route.AsyncBuilder
//(3) r -> r.path("/member/get/**")
// .uri("http://localhost:10000") 就是lambda表达式
//(4) 一会还要用代码进行说明-先使用-再理解
//3. 小伙伴们可以理解这是一个规定写法
return routes.route("member_route04", r -> r.path("/member/get/**")
.uri("http://localhost:10000"))
.build();
}
@Bean
public RouteLocator myRouteLocator05(RouteLocatorBuilder routeLocatorBuilder) {
RouteLocatorBuilder.Builder routes = routeLocatorBuilder.routes();
return routes.route("member_route05", r -> r.path("/member/save")
.uri("http://localhost:10000"))
.build();
}
}
实现lambada表达式
package com.zfc.springcloud;
import java.util.function.Function;
/**
* @author zfc
* @version 1.0
*/
public class T1 {
public static void main(String[] args) {
//这是lambda表达式的第一种形式
//Dog dog = hi("小花猫", (String str) -> {
// Cat cat = new Cat();
// cat.setName(str);
// return cat;
//});
//对上面的lambda表达式进行简写
//Dog dog = hi("小花猫", str -> {
// Cat cat = new Cat();
// cat.setName(str);
// return cat;
//});
//对上面的lambda表达式进行简写
//Dog dog = hi("小花猫", str -> {
// return new Cat(str);
//});
//对上面的lambda表达式进行简写
Dog dog = hi("小黄猫", r -> new Cat(r));
System.out.println(dog);
}
/**
* public Builder route(String id, Function<PredicateSpec, Route.AsyncBuilder> fn) {
* Route.AsyncBuilder routeBuilder = fn.apply(new RouteSpec(this).id(id));
* add(routeBuilder);
* return this;
* }
* routes.route("member_route04", r -> r.path("/member/get/**")
* .uri("http://localhost:10000"))
*/
//模拟把 Cat ->Dog
public static Dog hi(String str, Function<String, Cat> fn) {
Cat cat = fn.apply(str);
Dog dog = new Dog();
dog.setName(cat.getName() + " ~变成了小狗名");
return dog;
}
}
class Dog {
private String name;
public void setName(String name) {
this.name = name;
}
public String getName() {
return this.name;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
'}';
}
}
class Cat {
public Cat() {
}
public Cat(String name) {
this.name = name;
}
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
class Hsp {
}
Predicate/断言
一句话:
Predicate就是一组匹配规则,当请求匹配成功就执行对应的Route,匹配失败,放弃处理/转发
Spring Cloud Gateway包括许多内置的Route Predicate工厂,所有这些Predicate都与HTTP请求的不同属性匹配,可以组合使用.
Spring Cloud Gateway 创建 Route 对象时,使用RoutePredicateFactory 创建 Predicate 对象,Predicate 对象可以赋值给Route。
所有这些谓词都匹配HTTP请求的不同属性。多种谓词工厂可以组合
predicates: #断言,可以有多种形式
- Path=/member/get/**
#- After=2022-08-18T12:35:00.000+08:00[Asia/Shanghai]
#- Before=2022-08-18T12:35:50.000+08:00[Asia/Shanghai]
#- Between=2022-10-18T12:35:50.000+08:00[Asia/Shanghai],2022-11-18T12:35:50.000+08:00[Asia/Shanghai]
#- Cookie=user, hsp
#- Header=X-Request-Id, hello
#- Host=**.zfc.**
#- Method=POST,GET
#正则表达式在java基础时讲过,可以去回顾
#- Query=email, [\w-]+@([a-zA-Z]+\.)+[a-zA-Z]+
#- RemoteAddr=127.0.0.1
filters:
- AddRequestParameter=color, blue
- AddRequestParameter=address, beijing自定义过滤器
package com.zfc.springcloud.filter;
import lombok.extern.slf4j.Slf4j;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.http.HttpStatus;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
/**
* @author zfc
* @version 1.0
*/
@Component
public class CustomGateWayFilter implements GlobalFilter,
//filter是核心的方法,将我们的过滤的业务,写在该方法中
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
System.out.println("------CustomGateWayFilter------");
//先获取到对应的参数值
//比如 http://localhost:20000/member/get/1?user=zfc&pwd=123456
String user =
exchange.getRequest().getQueryParams().getFirst("user");
String pwd = exchange.getRequest().getQueryParams().getFirst("pwd");
if(!("zfc".equals(user) && "123456".equals(pwd))) {//如果不满足条件
System.out.println("-----非法用户-----");
exchange.getResponse().setStatusCode(HttpStatus.NOT_ACCEPTABLE);//回应
return exchange.getResponse().setComplete();
}
//验证通过, 放行
return chain.filter(exchange);
}
//order 表示过滤器执行的顺序, 数字越小, 优先级越高
@Override
public int getOrder() {
return 0;
}
}
Sleuth+Zipkin (链路追踪)

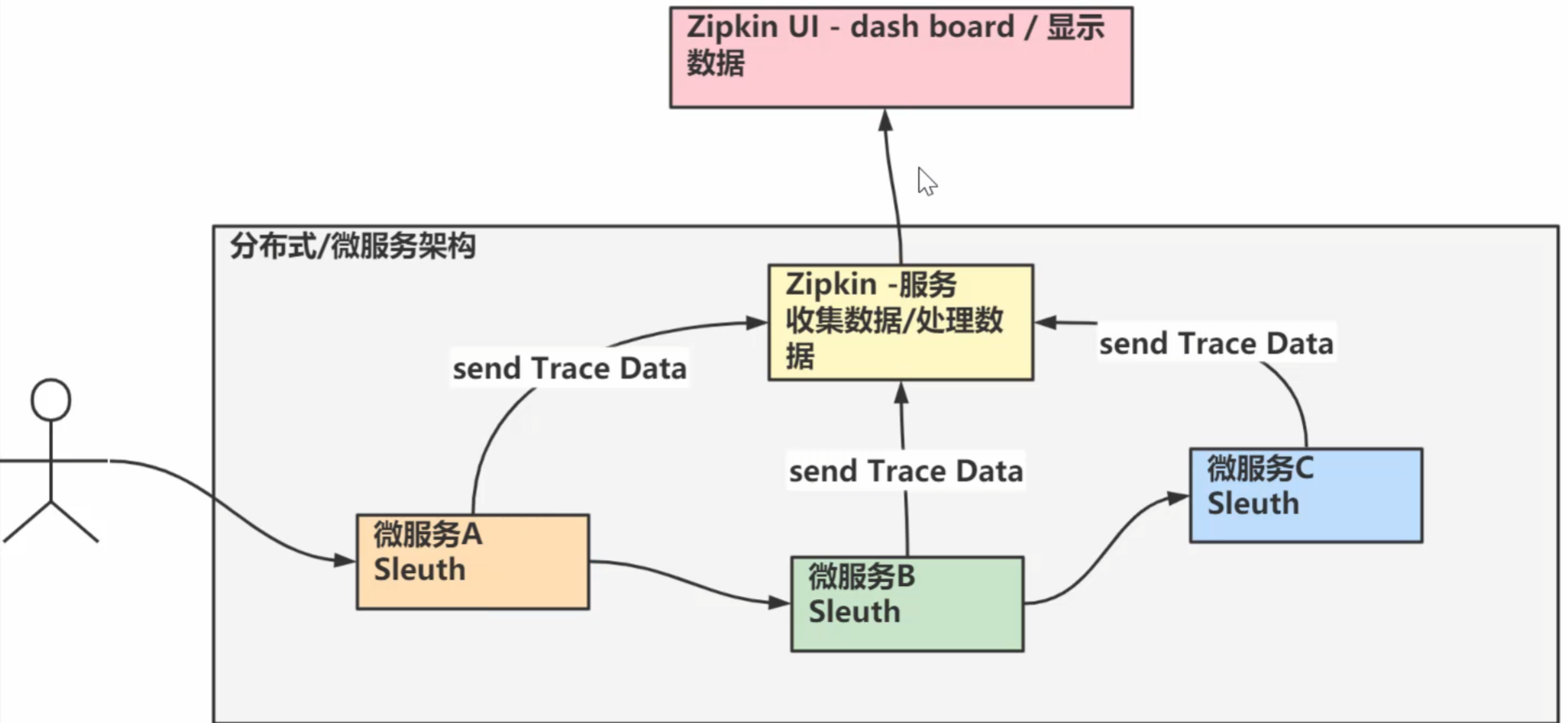
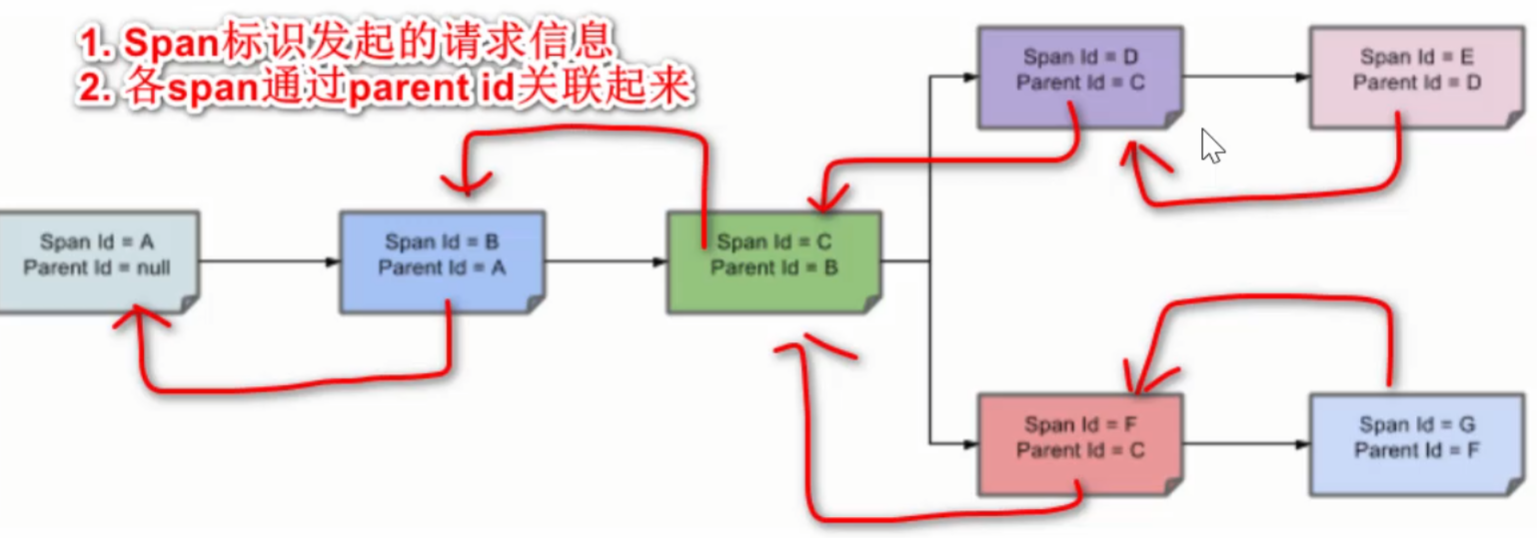
表示一请求链路,一条链路通过Trace Id唯一标识,Span标识发起的请求息,各span通过 parent id 关联起来
Trace:类似于树结构的Span集合,表示一条调用链路,存在唯一标识
Span:基本工作单元,表示调用链路来源,通俗的理解span就是一次请求信息
依赖配置
<!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-zipkin -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
<version>2.2.8.RELEASE</version>
</dependency>spring:
application:
name: member-service-provider
zipkin:
base-url: http://localhost:9411/
sleuth:
sampler:
probability: 1 # 采样率为1,即100%采样率Alibababa组件
cap
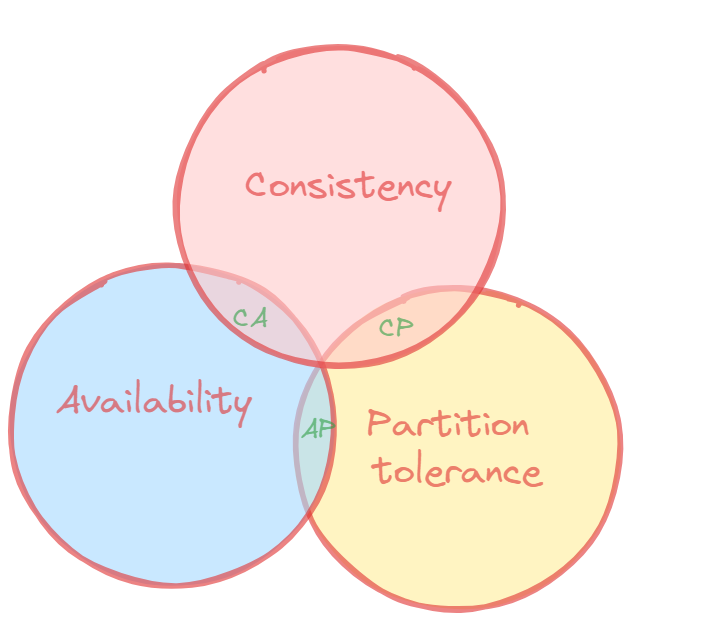
2000 年的时候,Eric Brewer 教授提出了 CAP 猜想,2年后,被 Seth Gilbert 和 Nancy Lynch 从理论上证明了猜想的可能性,从此,CAP 理论正式在学术上成为了分布式计算领域的公认定理。并深深的影响了分布式计算的发展。提出分布式系统有三个指标:
Consistency(一致性) 指数据在多个副本之间能够保持一致的特性(严格的一致性)
Availability(可用性) 指系统提供的服务必须一直处于可用的状态,每次请求都能获取到非错的响应(不保证获取的数据为最新数据)
Partition tolerance(分区容错性) 分布式系统在遇到任何网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务,除非整个网络环境都发生了故障
在一个分布式系统(指互相连接并共享数据的节点的集合)中,当涉及读写操作时,只能保证一致性(Consistence)、可用性(Availability)、分区容错性(Partition Tolerance)三者中的两个,另外一个必须被牺牲。
Nacos
application.yml
server:
port: 10004
spring:
application:
name: member-service-nacos-provider
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/springcloud?useSSL=true&useUnicode=true&characterEncoding=UTF-8
username: root
password: 123456
cloud:
nacos:
discovery:
server-addr: 192.168.137.47:8848
#配置所有监控点
management:
endpoints:
web:
exposure:
include: "*"
mybatis:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.zfc.springCloud.entitypom.xml
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>Nacos 配置中心
依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>在微服务架构中,配置中心是一个非常重要的组成部分。它的作用就是统一管理和集中存储各种微服务所需要的配置项,比如数据库连接地址、消息队列配置、第三方服务的API Key等。通常,这些配置是不同微服务在运行过程中必须用到的,如果每个微服务都单独去管理和读取这些配置,会非常麻烦,且不利于统一管理和维护。
用通俗的说明:
想象一下,如果你有一个大型的餐馆,餐馆里有多个厨房(代表微服务),每个厨房都有不同的菜品(服务功能),每个菜品的做法都需要一些原材料(配置项),比如某个菜可能需要特定的酱料、温度、烤制时间等等。如果每个厨房都要自己保存这些配方和原材料的细节,一旦有某个原料发生变化,所有厨房都需要重新调整和沟通,管理起来就变得很复杂。
这时,配置中心就像是一个中央仓库,所有厨房都可以从这个仓库里取到需要的原材料,并且如果某个原料(配置)发生变化,只需要在中央仓库更新一次,所有厨房(微服务)就能同步获取到新的原料配方,避免了重复配置和管理上的混乱。
配置中心做了什么:
集中管理:所有微服务的配置信息都集中在一个地方管理,不需要每个服务都去独立配置和维护。
动态更新:当配置有变动时,可以动态更新,不需要重新启动微服务。这样在发生配置变化时,系统能更快地响应,不影响服务的正常运行。
统一维护:通过配置中心,可以统一进行版本控制、权限控制、配置备份等,确保配置的安全性和一致性。
环境分离:配置中心可以区分不同的环境配置,例如开发环境、测试环境、生产环境,每个环境可以有不同的配置,而微服务通过环境标识来自动加载对应的配置。
配置中心的常见使用场景:
数据库连接配置:你可能会有多个微服务需要连接同一个数据库,配置中心就可以存储数据库的连接信息,微服务在启动时自动加载,避免每个服务都去重复配置。
API Key 或凭证信息:很多时候你会调用外部服务的API,可能需要配置一些认证信息或密钥,这些信息可以通过配置中心来统一管理。
动态调整服务行为:例如,某个微服务的功能可以根据配置来调整,比如日志级别、缓存策略等。通过配置中心,管理员可以动态改变这些设置,无需重新部署微服务。
常见的配置中心工具:
Spring Cloud Config:适用于Spring Boot应用,提供了配置管理的集中式解决方案。
Apollo:一个由携程公司开发的配置管理平台,支持动态推送配置和灰度发布等功能。
Nacos:阿里巴巴开源的一个服务发现与配置管理中心,支持分布式系统的配置管理。
总结来说,配置中心是微服务架构中用来集中管理配置的工具,能让系统更容易管理和扩展,避免每个服务都去管理自己的配置,减少了冗余和错误,并提高了系统的可维护性和可靠性。
application.yml
spring:
config:
activate:
on-profile: devbootstrap.yml
server:
port: 5000
spring:
application:
name: e-commerce-nacos-config-client
cloud:
nacos:
discovery:
server-addr: 192.168.137.47:8848
config:
server-addr: 192.168.137.47:8848
file-extension: yaml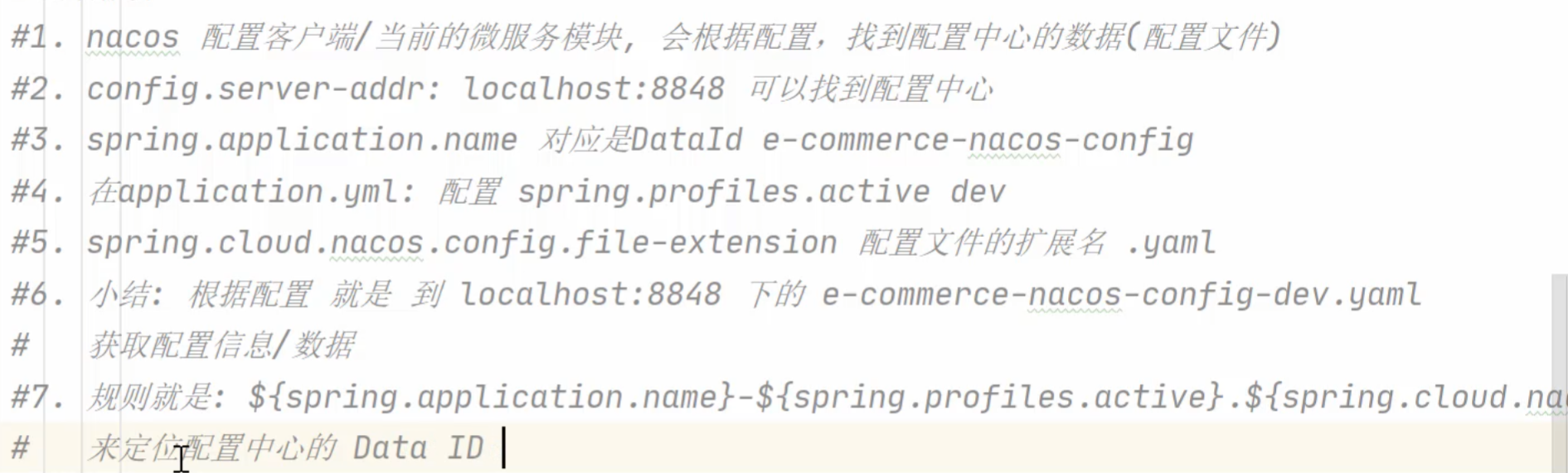
controller
package com.zfc.springcloud.controller;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.cloud.context.config.annotation.RefreshScope;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @author zfc
* @version 1.0
*/
@RestController
@Slf4j
@RefreshScope
public class NacosConfigClientController {
@Value("${config.ip}")
private String configIp;
@Value("${config.name}")
private String configName;
@GetMapping("/nacos/config/ip")
public String getConfigIp() {
System.out.println("configIp: " + configIp);
return configIp;
}
@GetMapping("/nacos/config/name")
public String getConfigName() {
System.out.println("configName: " + configName);
return configName;
}
}
分类配置隔离
可通过修改后缀的方式切换不同的配置文件

可通过配置GroupID的方式, DataID可以一样
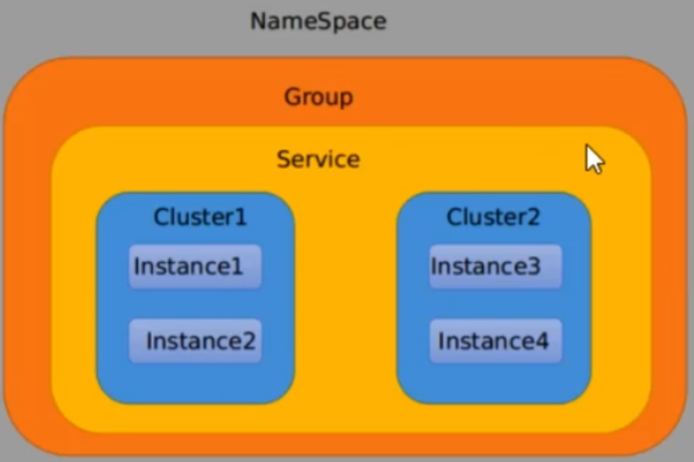
可通过Namespace的方式


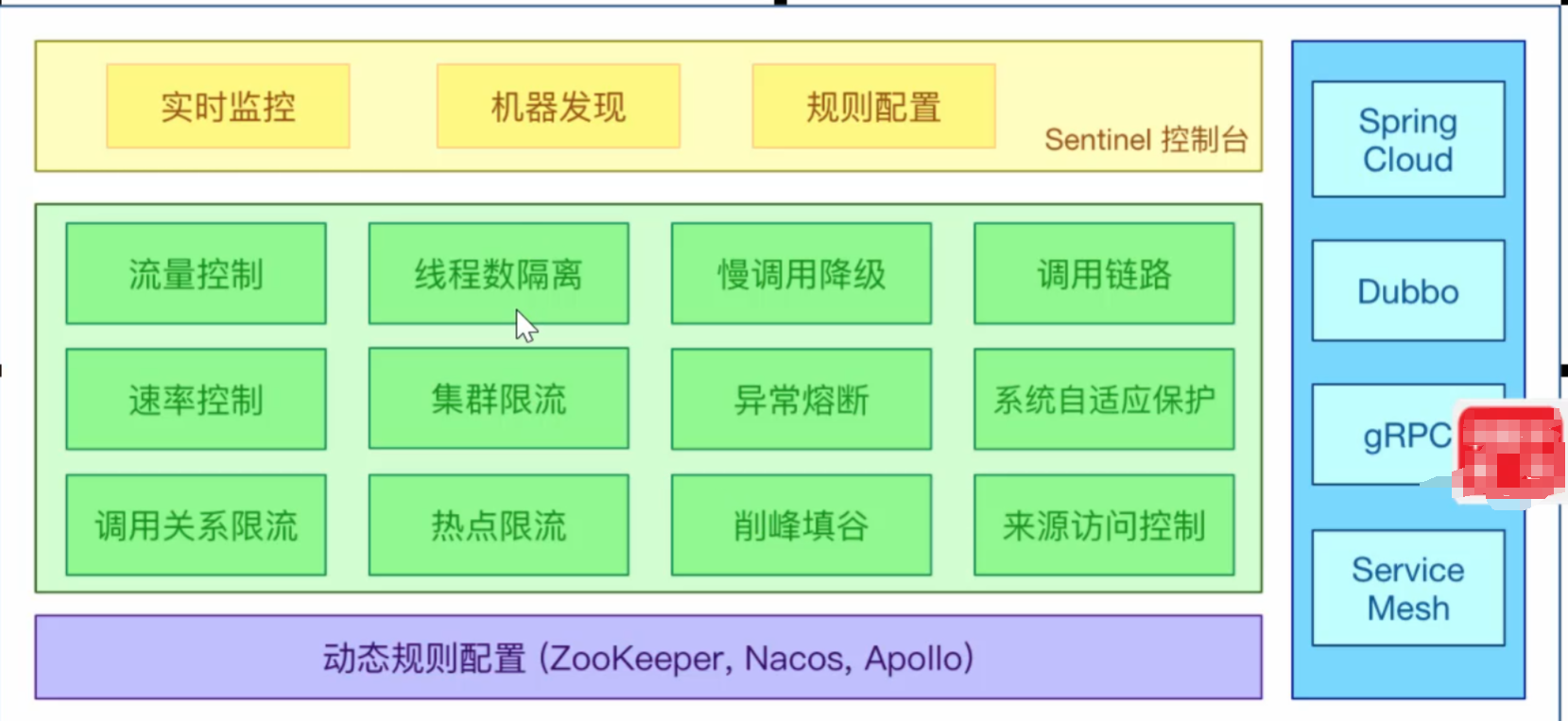
Sentinel
Sentinel 是什么?
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。!Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
熔断降级
熔断降级可以解决这个问题,所谓的熔断降级就是当检测到调用链路中某个资源出现不稳定的表现,列如请求响应时间长或异常比例升高的时候,则对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联故障
系统负载保护
-根据系统能够处理的请求,和允许进来的请求,来做平衡,追求的目标是在系统不被拖垮的情况下提高系统的吞吐率
消息削峰填谷
某瞬时来了大流量的请求,而如果此时要处理所有请求,很可能会导致系统负载过高,影响稳定性。但其实可能后面几秒之内都没有消息投递,若直接把多余的消息丢掉则没有充分利用系统处理消息的能力
Sentinel的Rate Limiter模式能在某一段时间间隔内以匀速方式处理这样的请求,充分利用系统的处理能力,也就是削峰填谷,保证资源的稳定性
application.yml配置
spring:
application:
name: member-service-nacos-provider
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/springcloud?useSSL=true&useUnicode=true&characterEncoding=UTF-8
username: root
password: 123456
cloud:
nacos:
discovery:
server-addr: 192.168.137.47:8848
sentinel:
transport:
dashboard: 192.168.137.47:8080
port: 8719 # 1.端口配置会在被监控的微服务对应主机上启动Http Server
# 2.该Http Server 会与Sentinel控制台进行交互
# 3. 比如sentinel 控制台添加了一个限流规则,会把规则数据push 给这个Http Server 接收
# Http Server 再将这个规则注册到Sentinel依赖
<!--引入sentinel依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>Sentinel 流量控制
1. QPS(Queries Per Second)
定义:QPS 是指每秒钟系统能够处理的请求数量,通常用于衡量系统的流量负载。例如,一个API每秒能接受多少个请求,或者一个服务器每秒能处理多少次访问。
作用:在 Sentinel 中,QPS 是用来设置流量控制的基础指标。比如你可以设置一个阈值,当流量达到设定的 QPS 限制时,Sentinel 会触发限流措施,保护系统免受过载。
例如,如果设置了 QPS 限制为 1000,表示系统每秒只能处理最多1000个请求。超过这个限制的请求将会被熔断、降级或拒绝,具体根据 Sentinel 的规则来决定。
应用场景:QPS 限流可以帮助开发者控制请求量,避免服务过载,特别是在高并发场景下,保护后端系统的稳定性。
2. 线程数(Threads)
定义:线程数是指当前应用或服务器能够并发执行的线程的数量。每个线程代表一个独立的执行单元,负责处理任务(如一个HTTP请求、一个数据库查询等)。线程数反映了应用能够并发处理的能力。
作用:在 Sentinel 中,线程数通常用于设置资源的并发执行上限,控制在特定时间内可以同时执行多少个任务。例如,如果线程数达到上限,系统将可能阻塞或拒绝新的请求,直到某个线程完成任务。
在一些情况下,线程数限制可能与 QPS 结合使用,限制流量不仅依赖于请求数量,还与并发执行的线程数密切相关。过多的并发线程可能导致资源竞争和性能下降。
应用场景:线程数管理对于高并发系统尤为重要,合理配置线程池和线程数可以避免资源浪费或瓶颈,保障服务稳定运行。
区别总结:
QPS 更侧重于控制单位时间内的请求量,保护系统免受过多请求的压力。
线程数 更侧重于控制系统可以并发执行的任务数,管理并发负载
流控模式:
直接: api达到限流条件时,直接限流
关联:当关联的资源达到阈值时,就限流自己
链路:当从某个接口过来的资源达到限流条件时,开启限流
流控效果
快速失败:直接失败,抛异常
Warm Up:根据codeFactor(冷加载因子,默认3)的值,从阈值/codeFactor,经过预热时长,才达到设置的OPS阈值
排队等待:匀速排队,让请求以匀速的速度通过,值类型必须设置为QPS,否则无效
warm up

排队
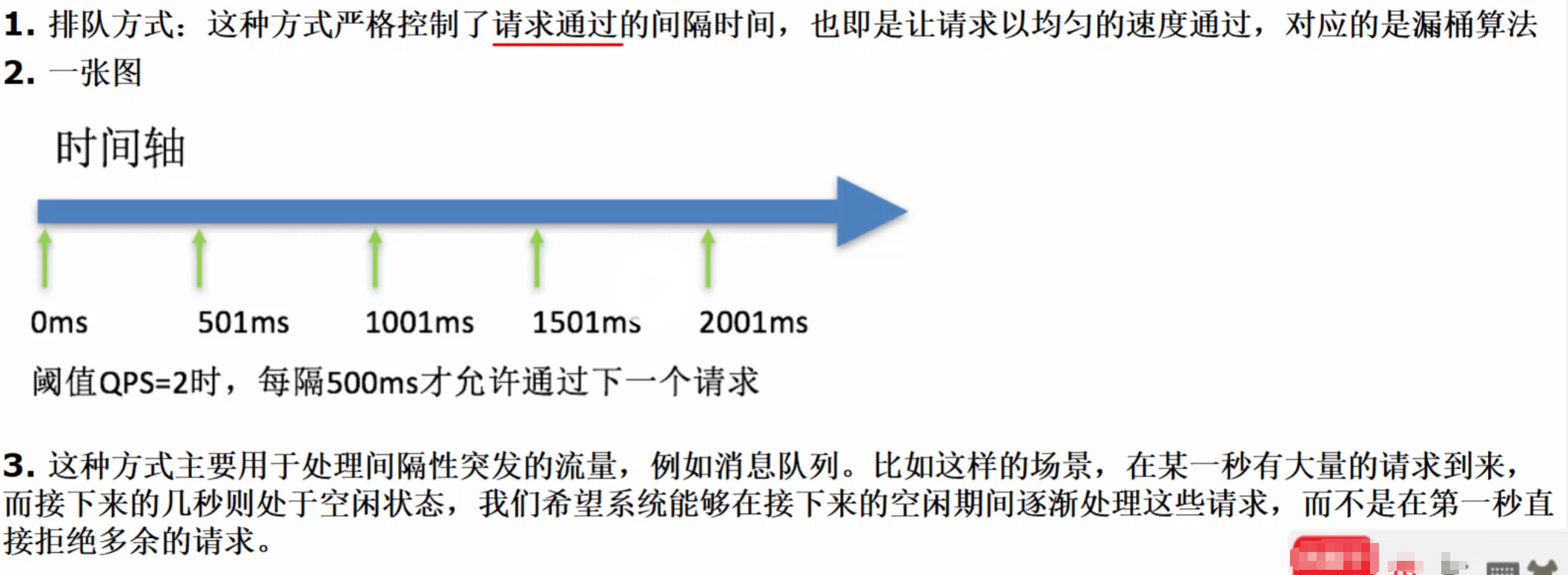
熔断降级


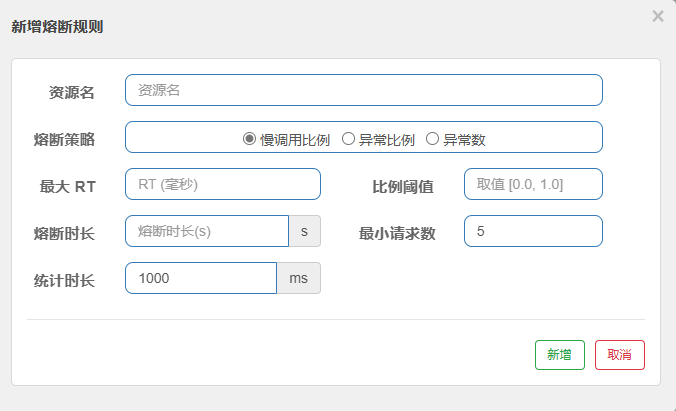

1. 慢调用比例 (Slow Call Ratio)
定义: 慢调用比例是指在一定时间内,执行超过设定阈值(通常是响应时间)时间的请求占总请求数的比例。这个指标可以帮助我们检测系统是否存在性能瓶颈,或某些服务调用过慢。
举例: 假设某个服务的响应时间阈值设置为 500 毫秒。如果在过去 1 分钟内,共有 100 个请求,其中 30 个请求的响应时间超过了 500 毫秒。那么,慢调用比例为:
慢调用比例=30/100=30%
如果慢调用比例过高,可能需要对该服务进行优化,比如增加缓存、改进数据库查询或优化算法。
2. 异常比例 (Exception Ratio)
定义: 异常比例是指在一定时间内,抛出异常(如系统错误、网络超时等)的请求占总请求数的比例。异常比例反映了服务是否在正常运行,若比例较高,说明系统可能存在大量故障或不稳定。
举例: 假设某个服务在过去 1 分钟内,共有 1000 个请求,其中 50 个请求抛出了异常(比如 500 错误)。那么,异常比例为:
异常比例=50/1000=5%
如果异常比例过高,通常需要排查系统日志,找出导致异常的根本原因,并进行修复。
3. 异常数 (Exception Count)
定义: 异常数是指在一定时间内,实际抛出的异常总数。这个指标通常用于更细粒度的监控,以帮助开发者量化异常发生的频率。
举例: 假设在过去 5 分钟内,某个服务总共处理了 2000 个请求,其中发生了 120 次异常。那么,异常数就是 120。
异常数=120
如果异常数明显增多,这可能表示系统中出现了某些问题,需要立即调查并修复。
总结
慢调用比例:关注请求的响应时间,帮助发现性能瓶颈。
异常比例:关注请求的异常情况,反映系统稳定性。
异常数:关注实际的异常发生数量,帮助识别故障的严重程度。
这些指标是 Sentinel 中非常重要的监控工具,通常用于流量控制、熔断、降级等场景,帮助系统更好地应对负载和错误,确保服务的高可用性和稳定性。
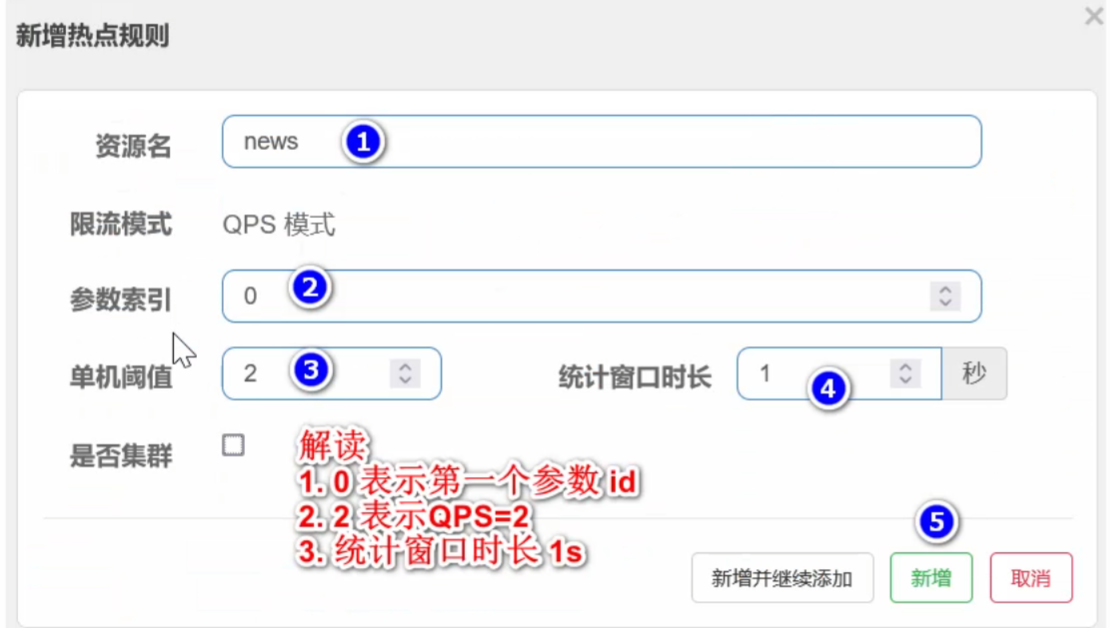
热点规则限流


import com.alibaba.csp.sentinel.annotation.SentinelResource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class MyController {
@SentinelResource(value = "helloWithFallback",
fallback = "fallbackMethod",
blockHandler = "blockHandlerMethod")
@GetMapping("/helloWithFallback")
public String helloWithFallback() {
// 模拟一个可能会抛出异常的方法
if (Math.random() > 0.5) {
throw new RuntimeException("Simulated Exception");
}
return "Hello, Sentinel with Fallback!";
}
// Fallback 方法
public String fallbackMethod(Throwable e) {
return "Fallback: Something went wrong!";
}
// BlockHandler 方法
public String blockHandlerMethod(BlockException ex) {
return "BlockHandler: Request is blocked!";
}
}
系统规则

在 Sentinel 中,系统规则 是指那些针对整个系统性能和稳定性进行保护的规则,主要包括对 系统资源(如 CPU、内存等) 和 系统级别的性能指标(如负载、响应时间等) 的控制。通过系统规则,Sentinel 能够动态地进行资源保护、流量管理以及应急响应,避免某个微服务或者整个系统因负载过大而崩溃。
Sentinel 系统规则主要包括以下几个方面:
1. QPS 限制(QPS Rules)
QPS(Queries Per Second)即每秒请求数,用来衡量系统处理请求的能力。通过设置 QPS 限制,可以防止系统因为处理过多请求而负载过高。
Sentinel 可以对不同的资源(比如 API 接口、微服务等)设置 QPS 限制,当请求数超过预定阈值时,系统会触发熔断或降级操作。
例子:限制某个接口的 QPS 为 1000,超过 1000 次请求则触发降级策略。
2. 系统负载保护(System Load Rules)
系统负载规则用于监控系统的负载情况,并在负载过高时采取应急措施。例如,CPU 使用率、内存占用率等可以作为系统负载的指标。
当系统负载超过设置的阈值时,Sentinel 会通过熔断、降级等方式限制流量,以避免系统进一步崩溃。
例子:当 CPU 使用率超过 90% 时,自动触发熔断,减少外部请求的处理。
3. 内存保护(Memory Rules)
内存保护规则用于监控系统的内存使用情况,避免系统因为内存过载而崩溃。如果内存使用量达到预设阈值,Sentinel 会采取降级或熔断操作。
例子:当内存使用达到 80% 时,限制新请求的进入或降低请求的处理优先级。
4. 线程池隔离规则(Thread Pool Isolation Rules)
线程池隔离是一种常见的流量控制策略,通过设置线程池的最大线程数、队列大小等限制来控制系统负载。
线程池隔离规则可以通过监控线程池的状态来判断是否需要调整资源分配或对某些请求做出限制。
例子:某个高并发服务的线程池最大线程数设置为 50,当线程池资源紧张时,自动执行降级。
系统规则的作用
保护系统资源:系统规则可以帮助保护 CPU、内存、线程池等关键资源,避免因为资源过载导致整个系统崩溃。
提高系统稳定性:通过动态调整流量或负载,系统规则能够确保在压力较大的情况下系统依然能够继续提供服务,并最大化降低系统的不稳定风险。
自动化容错机制:当系统发生异常或负载过高时,Sentinel 可以通过系统规则自动进行流量的调整、熔断或降级等操作,确保系统能够继续稳定运行,避免用户体验受到严重影响。
配置示例
在 Sentinel 中,系统规则通常可以通过配置文件或者代码进行设置。以下是一个基于 Java 配置的示例,展示如何设置系统规则:
javaimport com.alibaba.csp.sentinel.slots.system.SystemRule;
import com.alibaba.csp.sentinel.slots.system.SystemRuleManager;
import java.util.ArrayList;
import java.util.List;
public class SentinelSystemRuleDemo {
public static void main(String[] args) {
// 创建系统规则列表
List<SystemRule> rules = new ArrayList<>();
// 设置 QPS 限制规则
SystemRule qpsRule = new SystemRule();
qpsRule.setResource("MyAPI");
qpsRule.setCount(1000); // 每秒最多处理 1000 个请求
rules.add(qpsRule);
// 设置负载保护规则
SystemRule loadRule = new SystemRule();
loadRule.setResource("MyAPI");
loadRule.setCpuUsageThreshold(0.9); // CPU 使用率超过 90% 时触发
rules.add(loadRule);
// 设置内存保护规则
SystemRule memoryRule = new SystemRule();
memoryRule.setResource("MyAPI");
memoryRule.setMaxMemoryUsage(0.8); // 内存使用超过 80% 时触发
rules.add(memoryRule);
// 加载系统规则
SystemRuleManager.loadRules(rules);
System.out.println("Sentinel system rules initialized.");
}
}
总结
系统规则在 Sentinel 中起着至关重要的作用,帮助我们有效地管理和控制系统的资源使用,保障系统在面对突发流量或高负载时依然能够稳定运行。通过合理配置系统规则,可以有效避免由于过载导致的服务不可用或性能下降问题,提升整个微服务架构的健壮性。
全局异常处理类
/**
* @author zfc
* @version 1.0
* CustomGlobalFallbackHandler: 全局fallback处理类
* 在CustomGlobalFallbackHandler类中,可以去编写处理java异常/业务异常方法-static
*/
public class CustomGlobalFallbackHandler {
public static Result fallbackHandlerMethod1(Throwable e) {
return Result.error("402","java异常 信息=" + e.getMessage());
}
public static Result fallbackHandlerMethod2(Throwable e) {
return Result.error("403","java异常 信息=" + e.getMessage());
}
}/**
* @author zfc
* @version 1.0
* 1. CustomGlobalBlockHandler: 全局限流处理类
* 2. 在CustomGlobalBlockHandler类中,可以编写限流处理方法,但是要求方法是static
*/
public class CustomGlobalBlockHandler {
public static Result handlerMethod1(BlockException blockException) {
return Result.error("400", "客户自定义异常/限流处理方法handlerMethod1() ");
}
public static Result handlerMethod2(BlockException blockException) {
return Result.error("401", "客户自定义异常/限流处理方法handlerMethod2() ");
}
} /**
* value = "t6" 表示 sentinel限流资源的名字
* blockHandlerClass = CustomGlobalBlockHandler.class : 全局限流处理类
* blockHandler = "handlerMethod1": 指定使用全局限流处理类哪个方法,来处理限流信息
* fallbackClass = CustomGlobalFallbackHandler.class: 全局fallback处理类
* fallback = "fallbackHandlerMethod1": 指定使用全局fallback处理类哪个方法来处理java异常/业务异常
* exceptionsToIgnore = {RuntimeException.class}: 表示如果t6()抛出RuntimeException, 就使用系统默认方式处理
*
* @return
*/
//这里我们使用全局限流处理类,显示限流信息
@GetMapping("/t6")
@SentinelResource(value = "t6",
fallbackClass = CustomGlobalFallbackHandler.class,
fallback = "fallbackHandlerMethod1",
blockHandlerClass = CustomGlobalBlockHandler.class,
blockHandler = "handlerMethod1",
exceptionsToIgnore = {NullPointerException.class})
public Result t6() {
//假定: 当访问t6资源次数是5的倍数时,就出现java异常
if (++num % 5 == 0) {
throw new NullPointerException("null指针异常 num=" + num);
}
if (num % 6 == 0) {//当访问t6资源次数是6的倍数时,抛出 runtime异常
throw new RuntimeException("RuntimeException num=" + num);
}
log.info("执行t6() 线程id={}", Thread.currentThread().getId());
return Result.success("200", "t6()执行OK~~");
}Nacos持久化流控规则


依赖
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>spring:
application:
name: member-service-nacos-consumer
cloud:
nacos:
discovery:
server-addr: 192.168.137.47:8848
sentinel:
transport:
dashboard: 192.168.137.47:8080
port: 8719
datasource:
ds1:
nacos:
server-addr: 192.168.137.47:8848
data-id: member-service-nacos-consumer # 配置中心的Data ID
group-id: DEFAULT_GROUP # 配置中心的Group ID
data-type: json # 配置中心的数据类型
rule-type: flow # 限流规则类型Seata
一句话: Seata是一款开源的分布式事务解决方案致力于在微服务架构下提供高性能和简单易用的分布式事务服务
数据库SQL
drop table if exists `global_table`;
create table `global_table` (
`xid` varchar(128) not null,
`transaction_id` bigint,
`status` tinyint not null,
`application_id` varchar(32),
`transaction_service_group` varchar(32),
`transaction_name` varchar(128),
`timeout` int,
`begin_time` bigint,
`application_data` varchar(2000),
`gmt_create` datetime,
`gmt_modified` datetime,
primary key (`xid`),
key `idx_gmt_modified_status` (`gmt_modified`, `status`),
key `idx_transaction_id` (`transaction_id`)
);
-- the table to store BranchSession data
drop table if exists `branch_table`;
create table `branch_table` (
`branch_id` bigint not null,
`xid` varchar(128) not null,
`transaction_id` bigint ,
`resource_group_id` varchar(32),
`resource_id` varchar(256) ,
`lock_key` varchar(128) ,
`branch_type` varchar(8) ,
`status` tinyint,
`client_id` varchar(64),
`application_data` varchar(2000),
`gmt_create` datetime,
`gmt_modified` datetime,
primary key (`branch_id`),
key `idx_xid` (`xid`)
);
-- the table to store lock data
drop table if exists `lock_table`;
create table `lock_table` (
`row_key` varchar(128) not null,
`xid` varchar(96),
`transaction_id` long ,
`branch_id` long,
`resource_id` varchar(256) ,
`table_name` varchar(32) ,
`pk` varchar(36) ,
`gmt_create` datetime ,
`gmt_modified` datetime,
primary key(`row_key`)
);
-- the table to store seata xid data
-- 0.7.0+ add context
-- you must to init this sql for you business databese. the seata server not need it.
-- 此脚本必须初始化在你当前的业务数据库中,用于AT 模式XID记录。与server端无关(注:业务数据库)
-- 注意此处0.3.0+ 增加唯一索引 ux_undo_log
drop table if exists `undo_log`;
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
微服务表参考
# 创建订单服务数据库
CREATE DATABASE order_micro_service;
Use order_micro_service;
CREATE TABLE `order` (
id BIGINT NOT NULL PRIMARY KEY,
user_id BIGINT NOT NULL,
product_id BIGINT NOT NULL,
nums INT DEFAULT NULL,
money INT DEFAULT NULL,
`status` INT DEFAULT NULL COMMENT '0: 创建中; 1: 已完结'
);
-- 库存微服务的数据库`storage``order`
CREATE DATABASE storage_micro_service;
CREATE TABLE `storage`(
id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
product_id BIGINT DEFAULT NULL ,
amount INT DEFAULT NULL COMMENT '库存量'
);
INSERT INTO `storage` VALUES(NULL, 1, 10);
SELECT * FROM `storage`
-- 账号微服务的数据库
CREATE DATABASE account_micro_service
USE account_micro_service
CREATE TABLE `account`(
id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
user_id BIGINT DEFAULT NULL ,
money INT DEFAULT NULL COMMENT '账户金额'
);
-- 初始化账户表
INSERT INTO `account` VALUES(NULL, 666, 10000);服务端配置文件
# Transport configuration, for client and server
# 配置传输方式、心跳、批量请求和超时等与客户端和服务器通信相关的设置
transport.type=TCP
transport.server=NIO
transport.heartbeat=true
transport.enableTmClientBatchSendRequest=false
transport.enableRmClientBatchSendRequest=true
transport.enableTcServerBatchSendResponse=false
transport.rpcRmRequestTimeout=30000
transport.rpcTmRequestTimeout=30000
transport.rpcTcRequestTimeout=30000
transport.threadFactory.bossThreadPrefix=NettyBoss
transport.threadFactory.workerThreadPrefix=NettyServerNIOWorker
transport.threadFactory.serverExecutorThreadPrefix=NettyServerBizHandler
transport.threadFactory.shareBossWorker=false
transport.threadFactory.clientSelectorThreadPrefix=NettyClientSelector
transport.threadFactory.clientSelectorThreadSize=1
transport.threadFactory.clientWorkerThreadPrefix=NettyClientWorkerThread
transport.threadFactory.bossThreadSize=1
transport.threadFactory.workerThreadSize=default
transport.shutdown.wait=3
transport.serialization=seata
transport.compressor=none
# Transaction routing rules configuration, only for the client
# 事务路由规则配置,主要是客户端使用,用于指定事务组和默认的事务服务地址
# service.vgroupMapping.default_tx_group=default
service.vgroupMapping.zfc_tx_group=default
service.default.grouplist=192.168.137.47:8091
service.enableDegrade=false
service.disableGlobalTransaction=false
# Transaction rule configuration, only for the client
# 事务规则配置,客户端相关的事务控制配置,如异步提交、重试、SQL解析等
client.rm.asyncCommitBufferLimit=10000
client.rm.lock.retryInterval=10
client.rm.lock.retryTimes=30
client.rm.lock.retryPolicyBranchRollbackOnConflict=true
client.rm.reportRetryCount=5
client.rm.tableMetaCheckEnable=true
client.rm.tableMetaCheckerInterval=60000
client.rm.sqlParserType=druid
client.rm.reportSuccessEnable=false
client.rm.sagaBranchRegisterEnable=false
client.rm.sagaJsonParser=fastjson
client.rm.tccActionInterceptorOrder=-2147482648
client.tm.commitRetryCount=5
client.tm.rollbackRetryCount=5
client.tm.defaultGlobalTransactionTimeout=60000
client.tm.degradeCheck=false
client.tm.degradeCheckAllowTimes=10
client.tm.degradeCheckPeriod=2000
client.tm.interceptorOrder=-2147482648
client.undo.dataValidation=true
client.undo.logSerialization=jackson
client.undo.onlyCareUpdateColumns=true
server.undo.logSaveDays=7
server.undo.logDeletePeriod=86400000
client.undo.logTable=undo_log
client.undo.compress.enable=true
client.undo.compress.type=zip
client.undo.compress.threshold=64k
# For TCC transaction mode
# TCC事务模式相关的配置,主要包括TCC事务的日志表和清理周期设置
tcc.fence.logTableName=tcc_fence_log
tcc.fence.cleanPeriod=1h
# Log rule configuration, for client and server
# 日志规则配置,用于控制异常日志的记录频率
log.exceptionRate=100
# Transaction storage configuration, only for the server
# 事务存储配置,仅针对服务端配置,决定事务数据的存储方式(如文件、数据库、Redis)
store.mode=db
store.lock.mode=db
store.session.mode=db
store.publicKey=
# If `store.mode,store.lock.mode,store.session.mode` are not equal to `file`, you can remove the configuration block.
# 文件存储相关的配置,如果store.mode设置为file则使用这些配置
store.file.dir=file_store/data
store.file.maxBranchSessionSize=16384
store.file.maxGlobalSessionSize=512
store.file.fileWriteBufferCacheSize=16384
store.file.flushDiskMode=async
store.file.sessionReloadReadSize=100
# These configurations are required if the `store mode` is `db`. If `store.mode,store.lock.mode,store.session.mode` are not equal to `db`, you can remove the configuration block.
# 数据库存储配置,当store.mode设置为db时,需要配置数据库连接信息
store.db.datasource=druid
store.db.dbType=mysql
store.db.driverClassName=com.mysql.cj.jdbc.Driver
store.db.url=jdbc:mysql://192.168.137.47:3306/seata?useUnicode=true&rewriteBatchedStatements=true
store.db.user=root
store.db.password=123456
store.db.minConn=5
store.db.maxConn=30
store.db.globalTable=global_table
store.db.branchTable=branch_table
store.db.distributedLockTable=distributed_lock
store.db.queryLimit=100
store.db.lockTable=lock_table
store.db.maxWait=5000
# These configurations are required if the `store mode` is `redis`. If `store.mode,store.lock.mode,store.session.mode` are not equal to `redis`, you can remove the configuration block.
# Redis存储配置,当store.mode设置为redis时,配置Redis连接信息
store.redis.mode=single
store.redis.single.host=127.0.0.1
store.redis.single.port=6379
store.redis.sentinel.masterName=
store.redis.sentinel.sentinelHosts=
store.redis.sentinel.sentinelPassword=
store.redis.maxConn=10
store.redis.minConn=1
store.redis.maxTotal=100
store.redis.database=0
store.redis.password=
store.redis.queryLimit=100
# Transaction rule configuration, only for the server
# 服务器端的事务规则配置,包括事务重试、分支异步执行等相关参数
server.recovery.committingRetryPeriod=1000
server.recovery.asynCommittingRetryPeriod=1000
server.recovery.rollbackingRetryPeriod=1000
server.recovery.timeoutRetryPeriod=1000
server.maxCommitRetryTimeout=-1
server.maxRollbackRetryTimeout=-1
server.rollbackFailedUnlockEnable=false
server.distributedLockExpireTime=10000
server.xaerNotaRetryTimeout=60000
server.session.branchAsyncQueueSize=5000
server.session.enableBranchAsyncRemove=false
server.enableParallelRequestHandle=false
# Metrics configuration, only for the server
# 服务器端的度量配置,包括是否启用度量和导出器配置
metrics.enabled=false
metrics.registryType=compact
metrics.exporterList=prometheus
metrics.exporterPrometheusPort=9898

DataSourceProxyConfig
package com.zfc.cloud.config;
import com.alibaba.druid.pool.DruidDataSource;
import io.seata.rm.datasource.DataSourceProxy;
import lombok.extern.slf4j.Slf4j;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.transaction.SpringManagedTransactionFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import javax.sql.DataSource;
@Configuration
@Slf4j
public class DataSourceProxyConfig {
@Value("${mybatis.mapperLocations}")
private String mapperLocations;
// 配置 DruidDataSource
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource druidDataSource() {
return new DruidDataSource();
}
@Bean
public DataSourceProxy dataSourceProxy(DataSource dataSource) {
return new DataSourceProxy(dataSource);
}
// 配置 SqlSessionFactory
@Bean
public SqlSessionFactory sqlSessionFactoryBean(DataSource dataSourceProxy) throws Exception {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSourceProxy);
sqlSessionFactoryBean.setMapperLocations(
new PathMatchingResourcePatternResolver().getResources(mapperLocations));
sqlSessionFactoryBean.setTransactionFactory(new SpringManagedTransactionFactory());
return sqlSessionFactoryBean.getObject();
}
}
mybatis.config
package com.zfc.cloud.config;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.context.annotation.Configuration;
/**
* @author zfc
* @version 1.0
*/
@Configuration
@MapperScan({"com.zfc.cloud.dao"})
public class mybatisConfig {
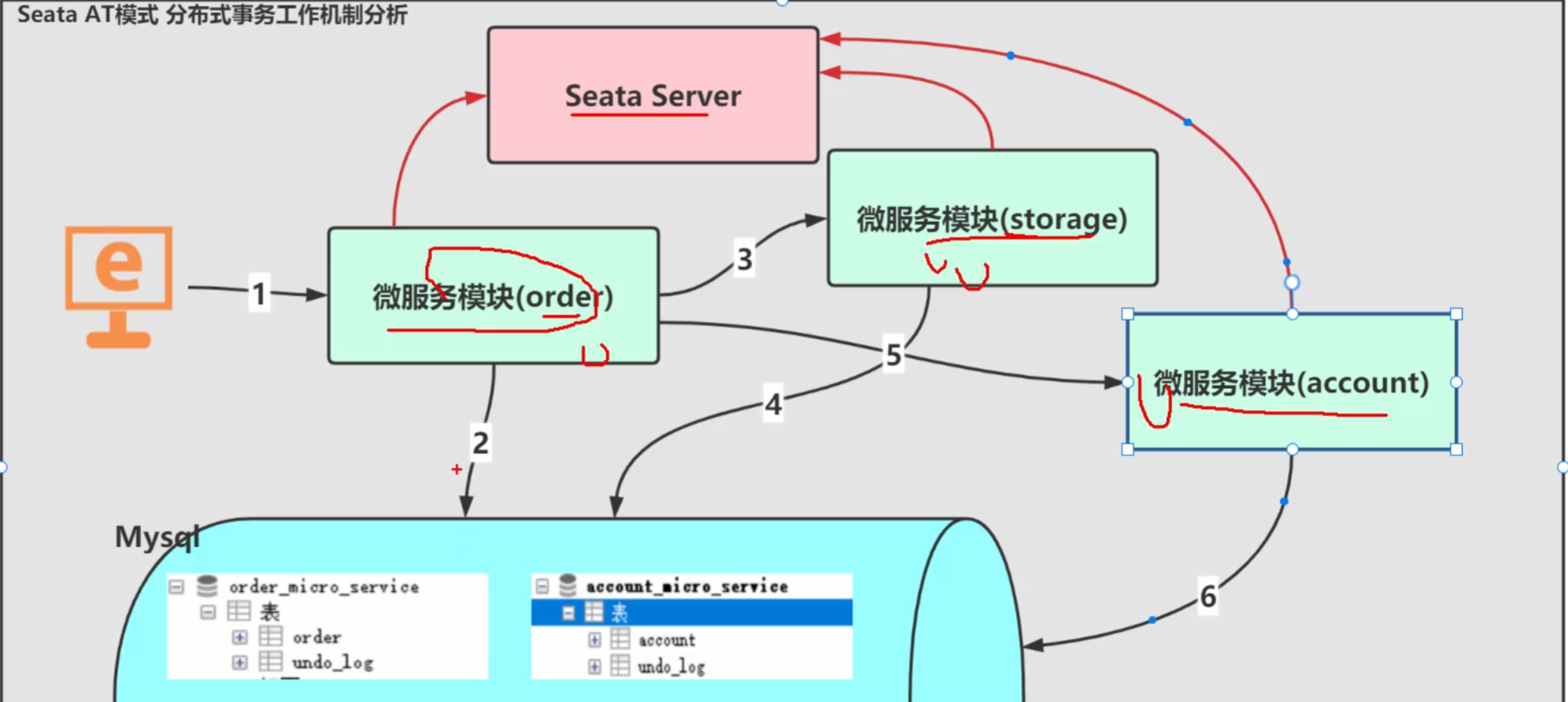
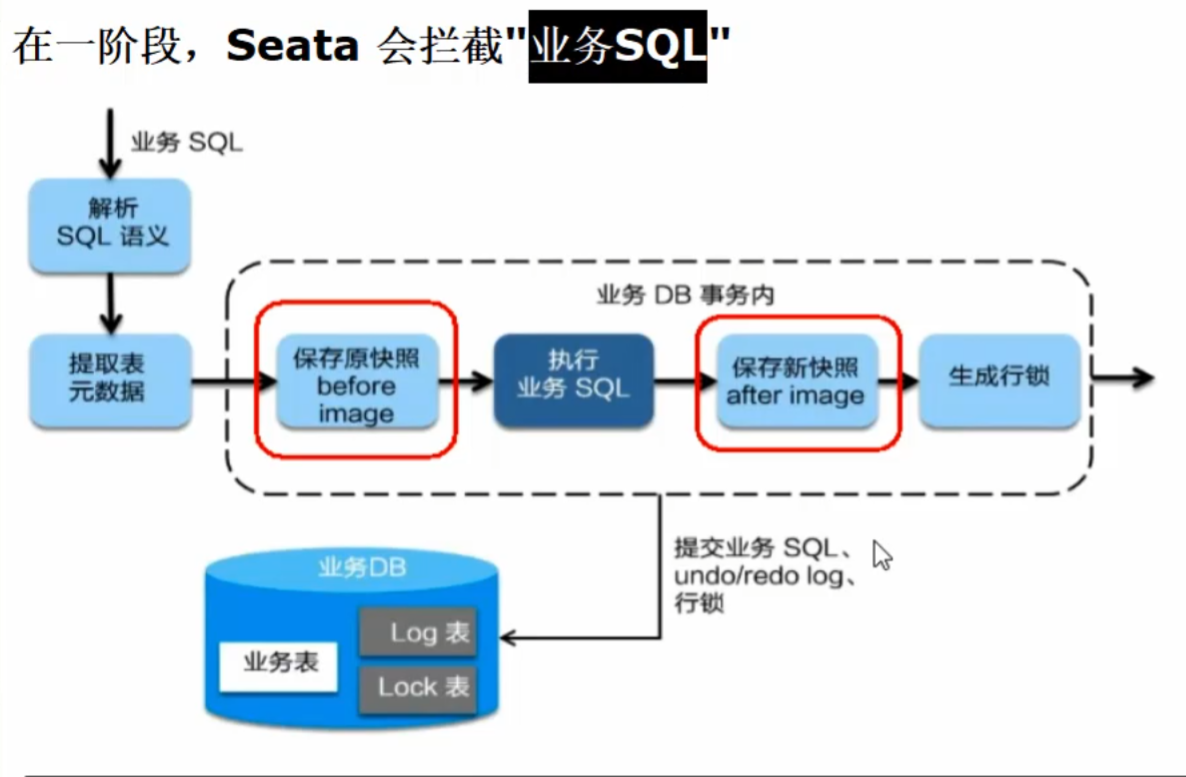
}事务流程分析
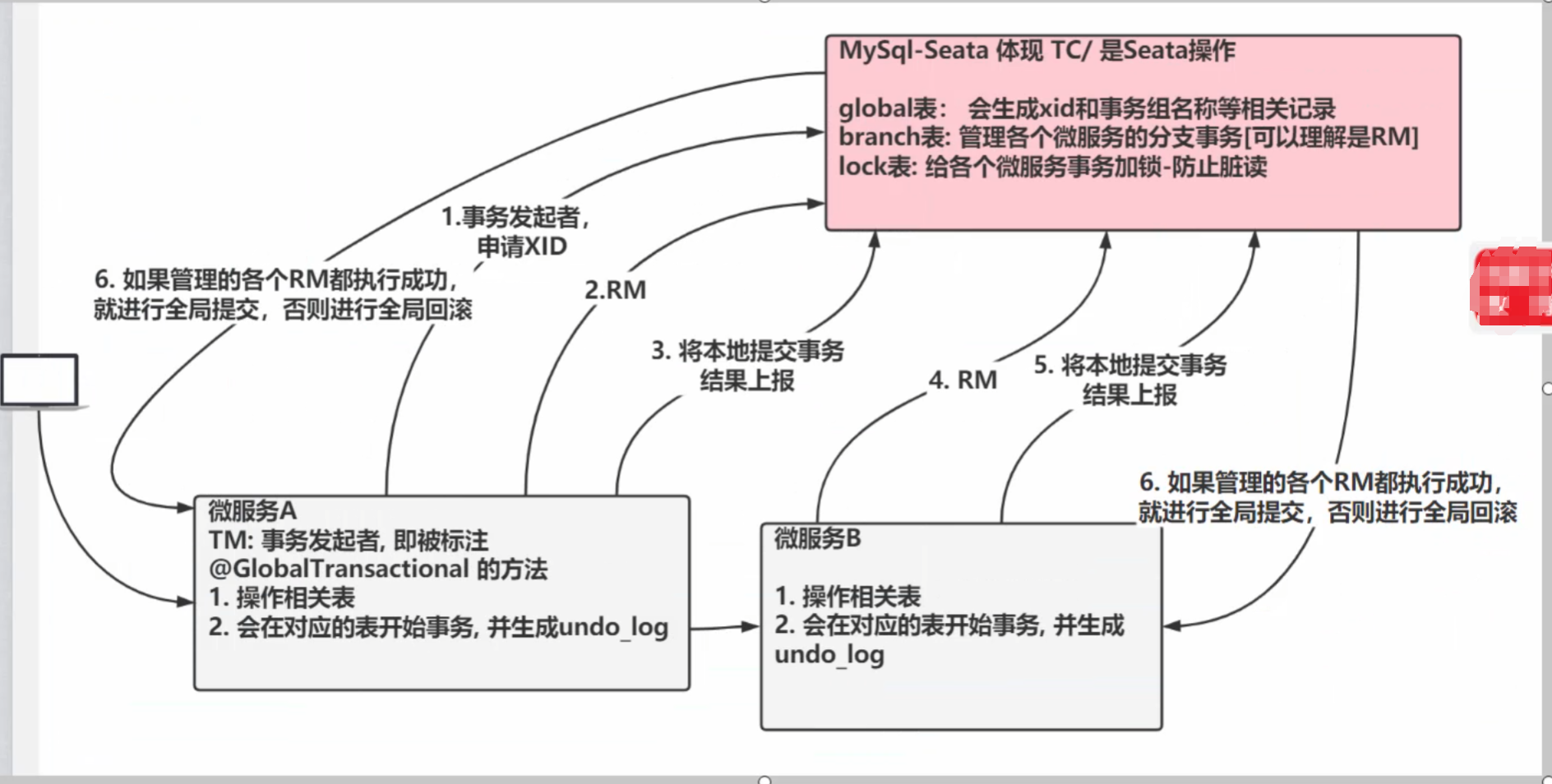
一阶段加载

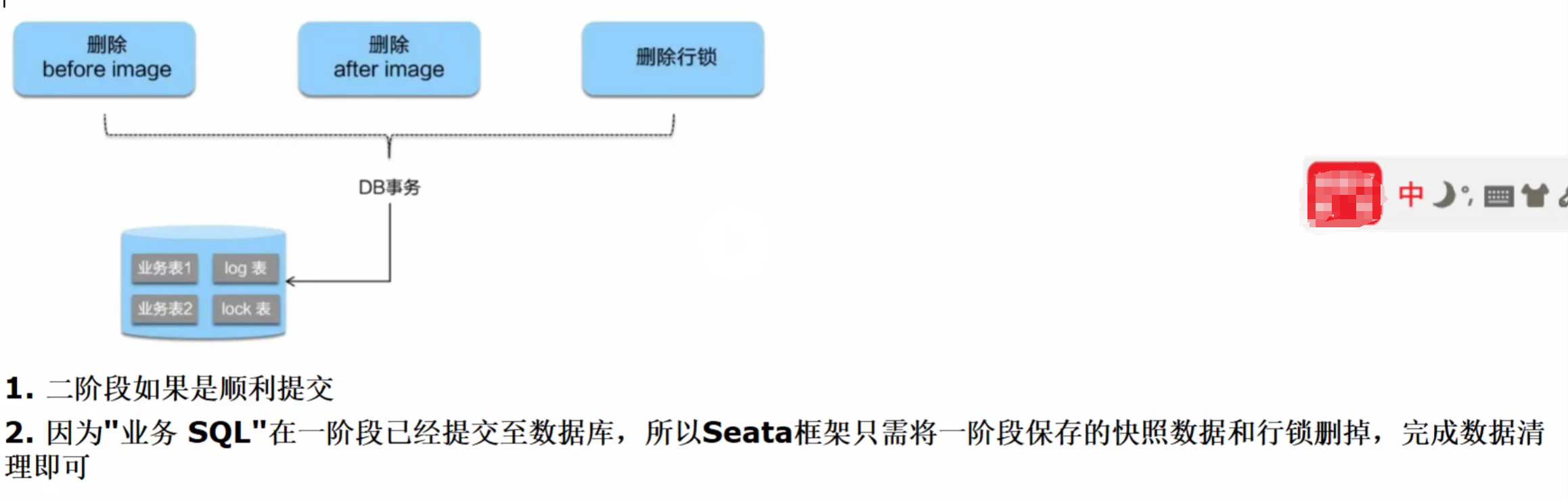
二阶段提交
SpringCloud
本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
评论交流
欢迎留下你的想法